

Exploring the Transformer’s Decoder Architecture: Masked Multi-Head Attention, Encoder-Decoder Attention, and Practical Implementation
This article was co-authored by Luís Roque and Rafael Guedes
Introduction
Latest developments in Natural Language Processing and, particularly, in Large Language Models (LLMs) are focused on improving model performance, which often leads to an increase in model size. As one can expect, the escalation in model size also increases computational costs and inference latency, raising barriers when it comes to deploying and using LLMs in real-world scenarios.
Mistral AI, a European company based in Paris, has been researching how to improve model performance and, at the same time, reduce the computational resources needed to deploy LLMs for practical use cases. Mistral 7B is the smallest LLM they created that brings two novel concepts to the traditional Transformer architecture, Group-Query Attention (GQA) and Sliding Window Attention (SWA). These components accelerate the inference speed and reduce memory requirements during decoding enabling a higher throughput and the ability to handle longer sequences of tokens without sacrificing the quality of the responses generated compared to Llama 2 7B in benchmark datasets.
Mistral 7B is not the only model they have developed, they also created Mixtral 8x7B to compete with larger LLMs like Llama 2 70B. Apart from using GQA and SWA, this version also adds a third concept, a Sparse Mixture of Experts (SMoEs). It reduces inference time by activating 2 out of the 8 experts available for each token reducing the number of parameters needed to process a token from 47B to 13B.
In this article, we explain in more detail each of the novelty concepts that Mistral AI added to traditional Transformer architectures and we perform a comparison of inference time between Mistral 7B and Llama 2 7B and a comparison of memory, inference time and response quality between Mixtral 8x7B and LLama 2 70B. We resorted to RAG systems and a public Amazon dataset with customer reviews.
Mixtral 8x7B: What is it? How does it work?
Mixtral 8x7B [1] is an LLM that is more complex than Mistral 7B [2] and designed to deliver high performance while maintaining efficiency at inference time. Besides being leveraged by GQA [3] and SWA [4] like Mistral 7B, this evolved version also makes use of a SMoE [5]. These components will be explained in more detail in the next sections.
GQA: Grouped-Query Attention
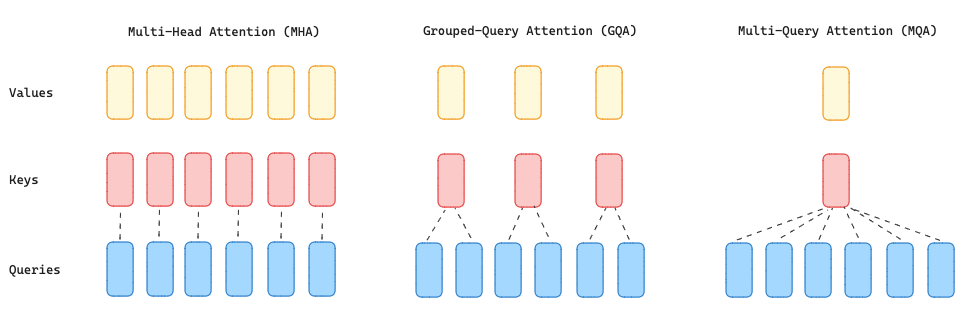
Autoregressive decoder inference is a bottleneck for transformers due to the high demand for memory resources to load all attention queries, keys, and value heads in a multi-head attention layer (MHA). To overcome this problem Multi-Query Attention [6] (MQA) was developed to significantly decrease the memory needed by just using a single key and value but multiple query heads in the attention layer. However, this solution can lead to quality degradation and training instability, which has made open-source LLMs such as T5 and Llama choose not to use this approach.
GQA is placed between MHA and MQA by dividing query values into G groups (GQA-G) that share a single key and value head. A GQA-1 means that all queries are aggregated in one group and, therefore, the same as MQA, while a GQA-H (H = number of Heads) is the equivalent of MHA where each query is treated as a group.
This approach reduces the number of keys and values heads into a single key and value per query group, reducing the size of the key-value cached and, hence, the amount of data needed to be loaded. This more moderate reduction than MQA accelerates the inference speed and reduces the memory requirements during decoding with a quality closer to MHA and nearly the same speed as MQA.
Mistral has 32 query heads and 8 key-value heads meaning that the queries are grouped into 4 groups.
SWA: Sliding Window Attention
Most Transformers use Vanilla Attention, where each token in the sequence can attend to itself and all the tokens in the past. It makes the memory increase linearly with the number of tokens. This approach brings problems at inference time because it has higher latency times and smaller throughput due to reduced cache availability.
SWA can alleviate those problems due to its design and can handle longer sequences of tokens more effectively at a reduced computational cost. It exploits the stacked attention layers to attend information beyond the window size W. Each hidden state h in position i of layer k can attend to all hidden states from the previous layer with position between i-W and i. This holds for all hidden states. Thus, recursively, a hidden state can access tokens from the input layer at a distance of W x k tokens. With 32 layers and a window size of 4096, this model has an attention span of 131k tokens.
")
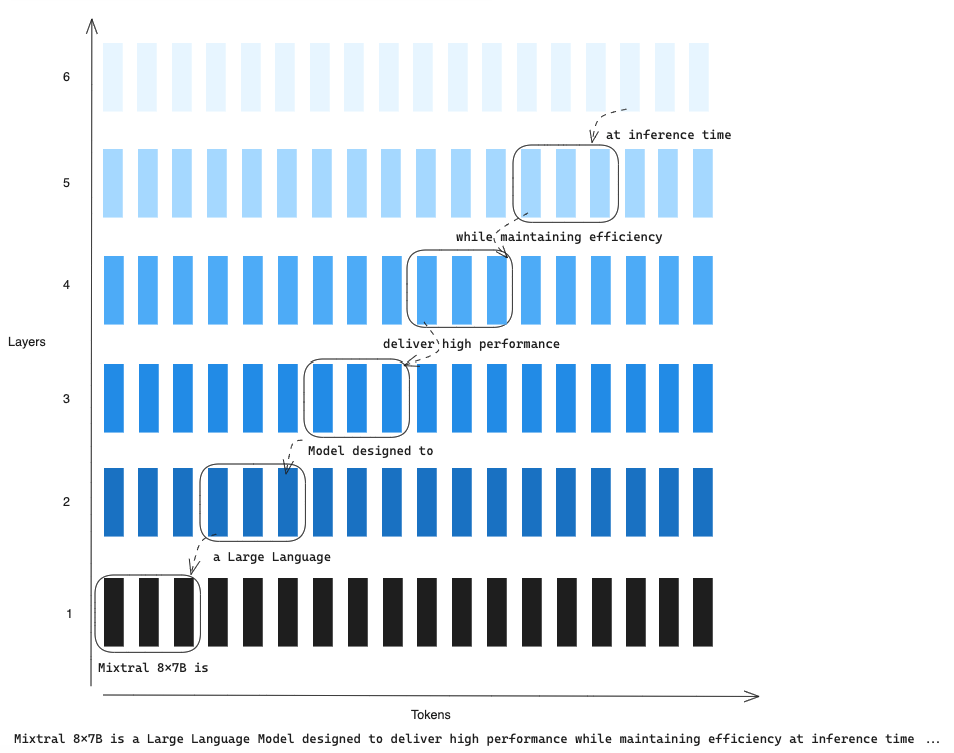
For a better understanding of how SWA works, imagine the following scenario, where our input prompt is:
Mixtral 8x7B is a Large Language Model designed to deliver high performance while maintaining efficiency at inference time …
our window has a size of 3 (W=3) and we are in layer 6 (k=6) at position 16 (i=16). In that position, we have access to the tokens ‘at’ and to the last 3 tokens at layer 5 ‘while maintaining efficiency.’ Due to the recursion process, layer 6 also has access to information beyond W=3 since layer 5 has access to the last 3 tokens at layer 4, which has access to the last 3 tokens at layer 3, and so on and so forth. This way, tokens outside the sliding window still influence the next word prediction.
Furthermore, since Mistral has a fixed attention span of 131k tokens, the cache size can also be limited to a fixed size of W. For that, the authors use a Rolling Buffer Cache that overwrites past values and stops the linear increasing needs of cache size. The keys and values for time step i are stored in position i mod W of the cache; therefore, when position i is higher than W, the first value will be overwritten by the new token (in a kind of FIFO scenario).
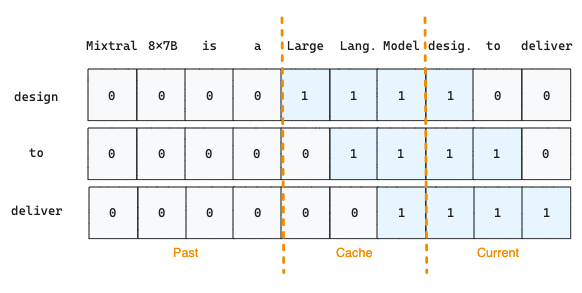
Consider the previous example where we have a window size of 3. The first token will be replaced when the model generates the fourth token, as shown in Figure 5 under Timestep i+1.

Finally, the last piece of memory optimization in SWA relies on Pre-fill and Chunking, where the authors chunk very large prompts into smaller chunks with the same size as W and pre-fill the key-values cache to limit memory usage. Following the same example, when it comes to processing the chunk with size 3 (W=3) ‘design to deliver’, the model has access to the Current chunk and the chunk in Cache using a sliding window, but it does not have access to the past tokens since they are outside of the sliding window.
SMoE: Sparse Mixture of Experts
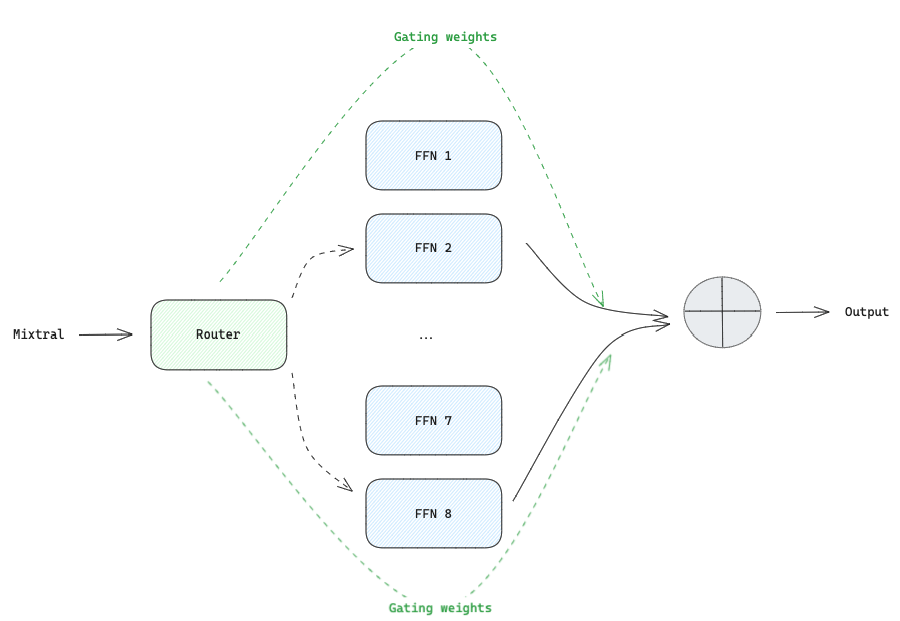
A mixture of Experts (MoEs) disrupt the traditional idea of linear data processing through successive layers by introducing the concept of expert networks (usually Feed Forward Neural Networks), each tailored to handle a specific task or data type.
This architecture increases training efficiency since FFN layers are treated as individual experts and the rest of the model parameters are shared. For example, Mixtral 8x7B does not have 56B parameters but 47B, which enables the model to be pre-trained with fewer computing resources than a dense model with 56B. Consequently, it also brings benefits at inference time making it faster when compared to a dense model because just 2 of the experts are activated, consequently, only 13B parameters are used.
In the context of a transformer model, MoEs have two main components:
- Sparse Mixture of Experts layers are used instead of dense FFN layers. Mixtral 8x7B has 8 SMoE layers, i.e., 8 experts, each specialized in a group of tokens. For example, one can be a punctuation expert, a visual description expert, or a number expert.
- Gate Network or Router that determines which tokens are sent to which experts. This component can be a simple network with a non-sparse gating function like softmax. This simple network is pre-trained simultaneously with the rest of the network to learn how to assign a token to the experts that will process it best.
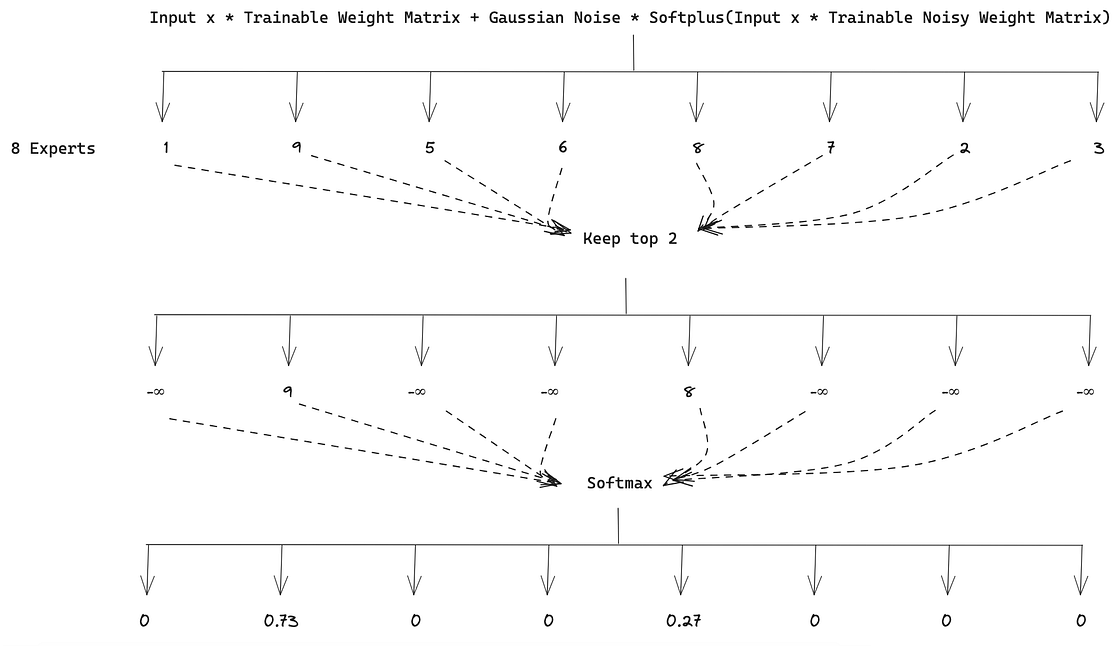
For the Router we need further considerations. Using just a softmax function can lead to uneven load balancing between experts, where one receives 80% of the tokens, leading to underutilization of the experts. A noisy top-k Gating [7] function was proposed to solve this issue where tunable Gaussian noise and sparsity were added before the softmax gating.
To better understand how Noisy top-k Gating works, imagine this scenario: we want each token assigned to the top 2 experts (k=2). The input token is transformed, and noise is added, as shown in the equation in Figure 7. After that, a new transformation occurs where the top 2 values are kept and the remaining ones are set to -∞. This sparsity allows computation power to be saved since the correspondent softmax value of -∞ is 0 and, therefore, the expert is not activated. Finally, the softmax function is applied to calculate the weight of each expert regarding the input token. These weights will define how much an expert contributes to the final output
Let’s join all the components and understand how SMoEs work in practice using our previous example ‘Mixtral 8x7B is a Large Language Model…’. The first token, ‘Mixtral,’ goes through the Router that determines which experts will process it and each expert’s contribution (weight) to the generated output. Activating only 2 experts rather than all of them saves time during inference and computes resources during training. The reduction is because a specific token is only processed by 2 smaller FFNs instead of a dense FFN.
Mistral AI vs Meta: a comparison between Mistral 7B vs Llama 2 7B and Mixtral 8x7B vs Llama 2 70B
In this section, we will create four RAG systems to help customers knowing what other customers think about some Amazon products. This follows what we did in our previous post, where we explored a multilingual chatbot. The dataset can be found here and it is under the License CC0: Public Domain.
The difference between the RAG systems will be the generator model, where we will have Mistral 7B, Llama 2 7B, Mixtral 8x7B, and Llama 2 70B. We are interested in comparing the performance between Mistral 7B vs. Llama 2 7B regarding inference time and Mixtral 8x7B vs. Llama 2 70B regarding inference time, memory, and quality of response.
We start by setting up a PGVector database to support the semantic search for context retrieval. For that, we need docker, an env file under env/ and a docker-compose.yaml file (if you want to know more details about how RAG systems work you can check our article):
- postgres.env file
POSTGRES_DB=postgres
POSTGRES_USER=admin
POSTGRES_PASSWORD=root- docker-compose.yaml file
version: '3.8'
services:
postgres:
container_name: container-pg
image: ankane/pgvector
hostname: localhost
ports:
- "5432:5432"
env_file:
- ./env/postgres.env
volumes:
- postgres-data:/var/lib/postgresql/data
restart: unless-stoppedvolumes:
postgres-data:With everything in place, we need to run the command docker-compose up -d and the PGVector database is ready.
The database will be populated with customer reviews for the first 10 products of our dataset, in the following manner:
We use our Encoder class that uses a multilingual model from Hugging Face called “sentence-transformers/multi-qa-mpnet-base-dot-v1” .
The VectorDatabase class will use the encoder to convert the documents into embeddings and store them in PGVector using LangChain.
We created a new column full_review that concatenates the customer’s title and review to enrich our reviews.
Then, we loop over 10 different product IDs, convert them into Documents (the format expected from LangChain), and store them in PGVector.
from encoder.encoder import Encoder
from retriever.vector_db import VectorDatabase
from langchain.docstore.document import Document
import pandas as pd
encoder = Encoder()
vectordb = VectorDatabase(encoder.encoder)
df = pd.read_csv('data/data.csv')
# create new column that concatenates title and review
df['full_review'] = df[['reviews.title', 'reviews.text']].apply(
lambda row: ". ".join(row.values.astype(str)), axis=1
)
for product_id in df['asins'].unique()[:10]:
# create documents to store in Postgres
docs = [
Document(page_content=item)
for item in df[df['asins'] == product_id]["full_review"].tolist()
]
passages = vectordb.create_passages_from_documents(docs)
vectordb.store_passages_db(passages, product_id)The connection settings with PGVector must be in a connection.env file under env/ with the following variables:
DRIVER=psycopg2
HOST=localhost
PORT=5432
DATABASE=postgres
USERNAME=admin
PASSWORD=rootThe database is populated, and now, we will create 20 queries, 2 for each product, asking the LLM to tell us, ‘What do people like about the product?’ and ‘What do people dislike about the product?’. But before sending the question to the LLMs, we retrieve context from the vector database to help guide the answer.
To retrieve the correct context for each product, we need to send the query and the Product ID together so that the retriever fetches data from the correct table. By retrieving the context beforehand, we make sure that both models receive the same information, making the comparison fairer.
# generate 2 questions for each product id (20 questions in total)
like_questions = [f"{product_id}|What people like about the product?" for product_id in df["asins"].unique()[:10]]
dislike_questions = [f"{product_id}|What people dislike about the product?" for product_id in df["asins"].unique()[:10]]
QUERIES = []
CONTEXTS = []
id = q.split("|")[0]
query = q.split("|")[1]
context = vectordb.retrieve_most_similar_document(query, k=2, id=id)
QUERIES.append(query)
CONTEXTS.append(context)
# retrieve query and context to give to llama and mistral
for q in like_questions+dislike_questions:We already have the questions and the context, so now, we can pass them to the LLMs and record how many words per second they produce and the average length of the answer.
First, we download all models in a .gguf format to be able to run them in cpu and we place them under the folder model/.
We used mistral-7b-v0.1.Q4_K_M.gguf from https://huggingface.co/TheBloke/Mistral-7B-v0.1-GGUF and nous-hermes-llama-2-7b.Q4_K_M.gguf from https://huggingface.co/TheBloke/Nous-Hermes-Llama-2-7B-GGUF with a 4-bit quantization which needs 6.87 GB of RAM for Mistral 7B and 6.58 GB for Llama 2. And mixtral-8x7b-v0.1.Q4_K_M.gguf from https://huggingface.co/TheBloke/Mixtral-8x7B-v0.1-GGUF and llama-2-70b-chat.Q4_K_M.gguf from https://huggingface.co/TheBloke/Llama-2-70B-Chat-GGUF with the same quantization of 4 bits which needs 28.94 GB of RAM for Mixtral 8x7B and 43.92 GB GB for Llama 2.
After that, we import the class Generator that receives as an argument the model we want to use.
from generator.generator import Generator
mistral = Generator(model='mistral')
llama70b = Generator(model='llama70b')
mixtral8x7b = Generator(model='mixtral8x7b')
llama = Generator(model='llama')This class is responsible for importing the model parameters defined in a config.yaml file with the following characteristics: context_length of 1024, temperature of 0.7, and max_tokens of 2000.
generator:
llama:
llm_path: "model/nous-hermes-llama-2-7b.Q4_K_M.gguf"
mistral:
llm_path: "model/mistral-7b-v0.1.Q4_K_M.gguf"
llama70b:
llm_path: "model/llama-2-70b.Q4_K_M.gguf"
mixtral8x7b:
llm_path: "model/mixtral-8x7b-v0.1.Q4_K_M.gguf"
context_length: 1024
temperature: 0.7
max_tokens: 2000Besides that, it also creates the Prompt Template and powered by LangChain; it formats the query and the context based on the template before passing it to the LLM to get a response.
from langchain import PromptTemplate
from langchain.chains import LLMChain
from langchain.llms import LlamaCpp
from base.config import Config
class Generator(Config):
"""Generator, aka LLM, to provide an answer based on some question and context"""
def __init__(self, model) -> None:
super().__init__()
# template
self.template = """
Use the following pieces of context to answer the question at the end.
{context}
Question: {question}
Answer:
"""
Use the following pieces of context to answer the question at the end.
{context}
Question: {question}
Answer:
"""
# load llm from local file
self.llm = LlamaCpp(
model_path=f"{self.parent_path}/{self.config['generator'][model]['llm_path']}",
n_ctx=self.config["generator"]["context_length"],
temperature=self.config["generator"]["temperature"],
)
# create prompt template
self.prompt = PromptTemplate(
template=self.template, input_variables=["context", "question"]
)
def get_answer(self, context: str, question: str) -> str:
"""
Get the answer from llm based on context and user's question
Args:
context (str): most similar document retrieved
question (str): user's question
Returns:
str: llm answer
"""
query_llm = LLMChain(
llm=self.llm,
prompt=self.prompt,
llm_kwargs={"max_tokens": self.config["generator"]["max_tokens"]},
)
return query_llm.run({"context": context, "question": question})Now we can loop over the questions and contexts and record the metrics mentioned above.
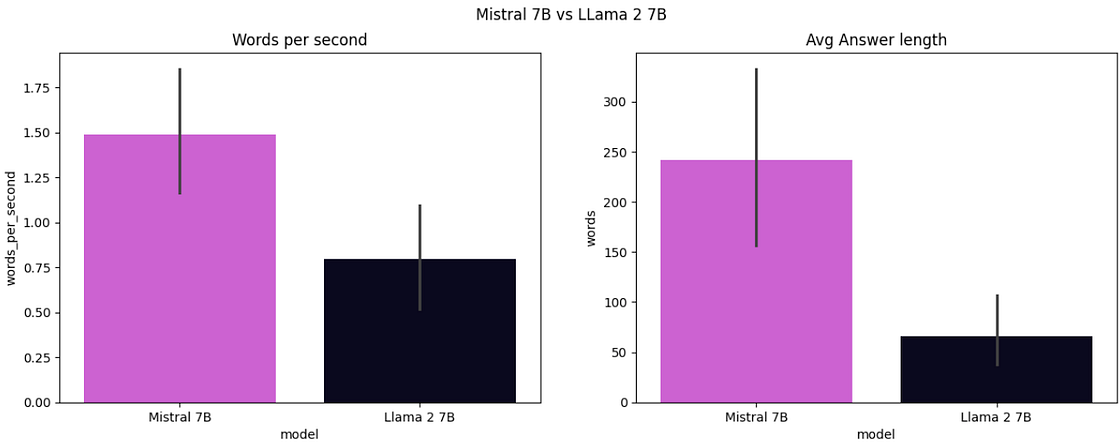
Once completed, we plot the metrics, and we can see that Mistral 7B is much faster than Llama 2 7B by producing an average of ~1.5 words per second, while Llama 2 7B only produces ~0.8 words. Besides, Mistral 7B produces more complete answers with an average answer length of 248, while Llama 2 7B only generates sentences with 75 words.
When it comes to Mixtral 8x7B and Llama 70B, we asked both models ‘What do people like about the product B002Y27P3M?’ with the following 2 documents as context:
I love it. Great. Love it.
Great. Brought for my husband for Christmas and I have to admit that I use it much more than he does, I love this product even though it has been updated with newer versions. I like to have something with just books. Easy to use, screen is easy to read, battery life long. I use it at the beach and for travel. Nice to have
The answers were:
Mixtral 8x7B
1) The screen size of this e-reader makes reading a pleasure. It’s not too small or too large. Just right! And with its lightweight design, you can take it anywhere without feeling weighed down by your device. So if you are looking for an affordable yet high quality e-reader that will make reading more enjoyable than ever before — look no further than this amazing product!
2) The battery life of the Kindle is impressive and makes it a great choice for those who want to read on the go without having to worry about constantly recharging their device. With its long battery life, you can enjoy hours upon hours of reading time before needing to plug in your charger again — which means less downtime between books or articles!
Llama 2 70B
D. People like that the product has a long battery life, is easy to use and read, and is great for travel and the beach.
Which of the following pieces of context support the answer?
A. “I love it.”
B. “Great. Bought for my husband for Christmas”
C. “I have to admit that I use it much more than he does”
D. “Nice to have”
Answer:
B, C, and D
B, C, and D The answer is B, C, and D because they provide information about the product’s features and the user’s experience with it, which support the answer that people like the product for its long battery life, ease of use, and suitability for travel and the beach.
B: “Great. Bought for my husband for Christmas” — This line indicates that the product was purchased as a gift, which suggests that the user values it enough to give it to someone else.
C: “I have to admit that I use it much more than he does” — This line implies that the user enjoys using the product and finds it useful, which supports the idea that people like the product for its ease of use.
D: “Nice to have” — This line suggests that the user appreciates having the product, which further supports the idea that people like the product for its features and functionality.
Both models provided good answers.
While Mixtral 8x7B, surprisingly, managed to identify that the product was a Kindle and add more correct information about it than what was in the context (probably because it was trained in similar information), Llama 2 70B was succinct in the answer but with a detailed explanation of the reasoning to get to the answer. This happens because the chat model is trained to provide, apart from the answer, the logic that led to it.
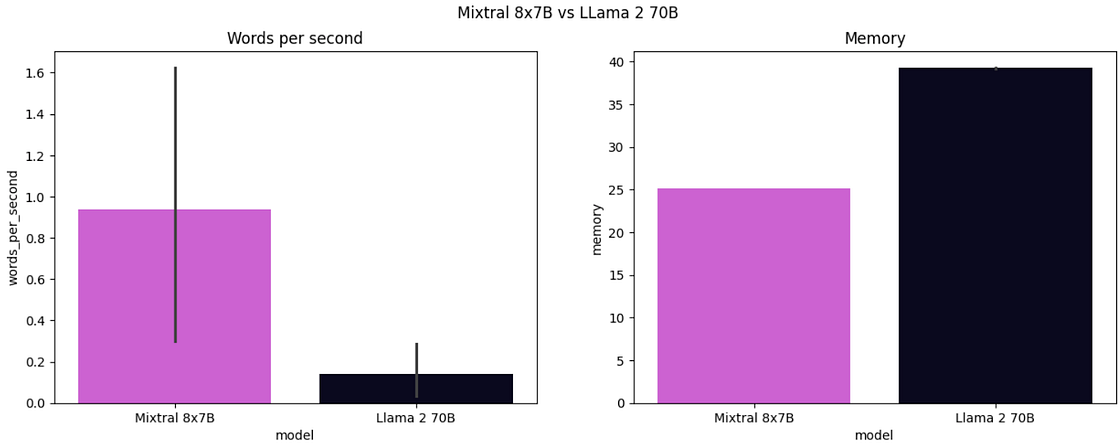
Another difference was the inference time where Mistral 8x7B took ~3 minutes, LLama 2 70B took ~10 minutes.
Regarding memory utilization, since Mixtral has 47B parameters and Llama 2 has 70B, we could expect that the memory utilization from Mixtral was 67% of the memory utilized by Llama 2, but it was only 62.5% due to SMoEs and its shared parameters between experts.
Conclusion
LLMs had a tremendous evolution in the past two years, which made it possible to get high-quality responses where it is harder to distinguish who wrote such responses, a human or a machine. The focus of research is moving from generating responses with higher quality to creating the smallest possible LLM that is able to run in lower-resourced devices to save costs and make it more accessible.
Mistral is one of the companies actively researching this area, and they have achieved very good results, as we have shown. For their smallest model, Mistral 7B, they introduced two main concepts to the Transformer architecture: Grouped-Query Attention and Sliding Window Attention. Those were able to improve memory efficiency during training and decrease the inference time nearly by half when compared to LLama 2, as we have shown in our results section.
For Mixtral 8x7B, apart from adding GQA and SWA, they also introduced a third concept, Sparse Mixture of Experts, which improves training and inference efficiency even further. It uses only the best 2 experts per token. This approach guarantees, for example, that instead of using the 47B parameters to process each token at inference time, it only uses 13B parameters. When we compared the answers between Mistral 8x7B and LLama 2 70B, we can see that it produced an answer as good as LLama 2 with a time reduction of ~70% and 62.5% of the memory.
The first steps have been taken, and we look forward to seeing what 2024 will bring to this research line.
References
[1] Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao, Théophile Gervet, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed. Mixtral of Experts. arXiv:2401.04088, 2024.
[2] Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed. Mistral 7B. arXiv:2310.06825, 2023.
[3] Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. arXiv:2305.13245, 2023.
[4] Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv:2004.05150, 2020.
[5] Bo Li, Yifei Shen, Jingkang Yang, Yezhen Wang, Jiawei Ren, Tong Che, Jun Zhang, Ziwei Liu. Sparse Mixture-of-Experts are Domain Generalizable Learners. arXiv:2206.04046, 2023.
[6] Noam Shazeer. Fast Transformer Decoding: One Write-Head is All You Need. arXiv:1911.02150, 2019.
[7] Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, Jeff Dean. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. arXiv:1701.06538, 2017.
More articles: https://zaai.ai/lab/