

A deep dive into tailoring pre-trained LLMs for custom use cases using a RAG approach, featuring LangChain and Hugging Face integration
This article was co-authored by Luís Roque and Rafael Guedes
Introduction
Since the release of ChatGPT in November of 2022, Large Language Models (LLMs) have been the hot topic in the AI community for their capabilities in understanding and generating human-like text, pushing the boundaries of what was previously possible in natural language processing (NLP).
LLMs have been shown to be versatile by tackling different use cases in various industries since they are not limited to a specific task. They can be adapted to several domains, making them attractive for organizations and the research community. Several applications have been explored using LLMs such as content generation, chatbots, code generation, creative writing, virtual assistants, and many more.
Another characteristic that makes LLMs so attractive is the fact that there are open-source options. Companies like Meta made their pre-trained LLM (Llama2 🦙) available in repositories like Hugging Face 🤗. Are these pre-trained LLMs good enough for each company’s specific use case? Certainly not.
Organizations could train an LLM from scratch with their own data. But the vast majority of them (almost all of them) wouldn’t have either the data or the computing capacity required for the task. It requires datasets with trillions of tokens, thousands of GPUs, and several months. Another option is to use a pre-trained LLM and tailor it for a specific use case. There are two main approaches to follow: fine-tuning and RAGs (Retrieval Augmented Generation).
In this article, we will compare the performance of an isolated pre-trained Llama2 with a pre-trained LLama2 integrated in a RAG system to answer questions about the latest news regarding OpenAI. We will start by explaining how RAGs work and the architecture of their sub-modules (the retriever and the generator). We finish with a step-by-step implementation of how we can build a RAG system for any use case using LangChain 🦜️ and Hugging Face.
As always, the code is available on our Github.
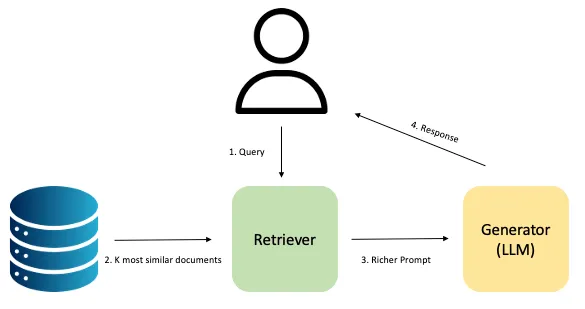
What is Retrieval Augmented Generation (RAG)?
Retrieval Augmented Generation (RAG) is a technique that combines a retriever (a non-parametric memory like vector databases or feature store) and a generator (a parametric memory like a pre-trained seq2seq transformer). They are used to improve the prediction quality of an LLM [1]. It uses the retriever during inference time to build a richer prompt by adding context/knowledge based on the most relevant documents for the user query.
The advantages of this kind of architecture over the traditional LLM are:
We can easily update its knowledge by replacing or adding more documents/information to the non-parametric memory. Thus, it does not require retraining the model.
It provides explainability over predictions because it allows the user to check which documents were retrieved to provide context, something we cannot get from traditional LLMs.
It reduces the well-known problem of ‘hallucinations’ by providing more accurate and up-to-date information through the documents provided by the retriever.
Retriever — what is it and how it works?
Retrievers were developed to solve the problem of Question-Answering (QA), where we expect a system to answer questions like “What is Retrieval Augmented Generation?”. It does it by accessing a database of documents that contain information about the topic.
The database is populated by splitting our documents into passages of equal lengths, where each passage is represented as a sequence of tokens. Given a question, the system needs to span the database to find ‘the passage’ that can better answer the question.
For these systems to work in several domains, their databases need to be populated with millions or billions of documents. Therefore, to be able to span the database searching for the right passage, the retriever needs to be very efficient in selecting a set of candidate passages.
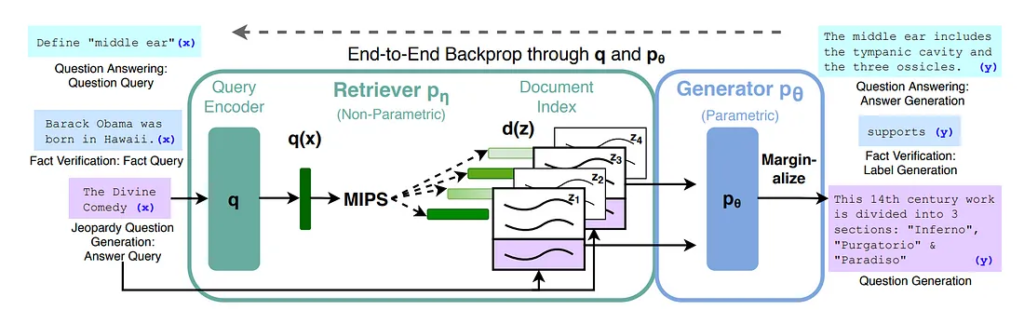
Dense Passage Retriever (DPR) [2] is the retriever used by the authors in [1]. Its goal is to index millions of passages into a low-dimensional and continuous space to efficiently retrieve the top k passages that are the most relevant for a specific question.
DPR uses two Dense Encoders:
The Passage Encoder converts each passage into a d-dimensional vector and indexes them using FAISS [3]. FAISS is an open-source library for similarity search of dense vectors which can be applied to billions of vectors.
The Question Encoder converts the input question to a d-dimensional vector and then uses FAISS to retrieve the k passages that have the closest vector to the question vector. The similarity between vectors can be computed by using the dot product between them.
The architecture for the encoder used by DPR is a BERT [4] network which converts the input into a high dimensional vector. However, we can use any architecture as long as it fits our use case.
Generator — what is it and how does it work?
The generator is an LLM responsible for generating text given a certain input, well known as a prompt.
LLMs are transformer models which are composed mainly of 2 types of layers [5]:
-
- A fully connected feed-forward network (FFN) maps one embedding vector to a new embedding vector through linear and non-linear transformations.
-
- The attention layer aims to select which parts of the input embedding are more useful for the task at hand, producing a new embedding vector.
BART [6] was the LLM chosen by the authors in [1] for the Generator, which is a sequence-to-sequence model with the following architecture [7]:
The encoder receives the input embedding and produces a 512-dimensional vector as output for the decoder through its six layers with two sub-layers (multi-head self-attention mechanism and FFN).
The decoder follows the same logic as the encoder with six layers and two sub-layers for the previously generated outputs. It has an additional 3rd sub-layer, which performs multi-head attention over the output of the encoder.
The decoder output is then passed to a linear layer followed by a softmax layer that will predict the likelihood of the next word.
As mentioned in the previous section, BART is not required to be used as the generator. With the advancements in this field, mainly since November of 2022 with the release of chatGPT, we can use any architecture that fits our needs. For example, one can use open-source approaches like Llama2 or Falcon.

How to implement a RAG using LangChain 🦜️ and HuggingFace 🤗?
This section describes how you can create your RAG using LangChain. LangChain is a framework to easily develop applications powered by LLMs, while HuggingFace is a platform that provides open-source LLMs and datasets for research and commercial usage.
In our case, and as stated in the introduction, we created an RAG where the generator is a Llama2 model to compare the quality of its output with a base Llama2. We will make Llama2 answer the question “What happened to the CEO of OpenAI?”.
The process starts with loading a dataset of news from HuggingFace (cnn_dailymail — apache 2.0 license) and supplementing it with more recent news about OpenAI, based on Luis’s latest posts on X/Twitter regarding the subject, including the resignation of its CEO. We then preprocess it by creating a list of documents (the expected format from LangChain) to fill our vector database.
from langchain.docstore.document import Document
from langchain.document_loaders import HuggingFaceDatasetLoader
# Get some open ai news to add to the final dataset
openai_news = [
"2023-11-22 - Sam Altman returns to OpenAl as CEO with a new initial board of Bret Taylor (Chair), Larry Summers, and Adam D'Angelo.",
"2023-11-21 - Ilya and the board's decision to fire Sam from OpenAI caught everyone off guard, with no prior information shared.",
"2023-11-21 - In a swift response, Sam was welcomed into Microsoft by Satya Nadella himself.",
"2023-11-21 - Meanwhile, a staggering 500+ OpenAI employees made a bold move, confronting the board with a letter: either step down or they will defect to Sam's new team at Microsoft.",
"2023-11-21 - In a jaw-dropping twist, Ilya, integral to Sam's firing, also put his name on that very letter. Talk about an unexpected turn of events!",
"2023-11-20 - BREAKING: Sam Altman and Greg Brockman Join Microsoft, Emmett Shear Appointed CEO of OpenAI",
"2023-11-20 - Microsoft CEO Satya Nadella announced a major shift in their partnership with OpenAI. Sam Altman and Greg Brockman, key figures at OpenAI, are now joining Microsoft to lead a new AI research team. This move marks a significant collaboration and potential for AI advancements. Additionally, Emmett Shear, former CEO of Twitch, has been appointed as the new CEO of OpenAI, signaling a new chapter in AI leadership and innovation.",
"2023-11-20 - Leadership Shakeup at OpenAI - Sam Altman Steps Down!",
"2023-11-20 - Just a few days after presenting at OpenAI's DevDay, CEO Sam Altman has unexpectedly departed from the company, and Mira Murati, CTO of the company, steps in as Interim CEO. This is a huge surprise and speaks volumes about the dynamic shifts in tech leadership today.",
"""2023-11-20 - What's Happening at OpenAI?
- Sam Altman, the face of OpenAI, is leaving not just the CEO role but also the board of directors.
- Mira Murati, an integral part of OpenAI's journey and a tech visionary, is taking the helm as interim CEO.
- The board is now on a quest to find a permanent successor.""",
"2023-11-20 - The transition raises questions about the future direction of OpenAI, especially after the board's statement about losing confidence in Altman's leadership.",
"""2023-11-20 - With a board consisting of AI and tech experts like Ilya Sutskever, Adam D'Angelo, Tasha McCauley, and Helen Toner, OpenAI is poised to continue its mission. Can they do it without Sam?
- Greg Brockman, stepping down as chairman, will still play a crucial role, reporting to the new CEO."""
]
# load dataset with some news
loader = HuggingFaceDatasetLoader("cnn_dailymail", "highlights", name='3.0.0')
docs = loader.load()[:10000] # get a sample of news
# add openai news to our list of docs
docs.extend([
Document(page_content=x) for x in openai_news
])Next, we are ready to create the 2 modules for our RAG.
Retriever
In the retriever, we have two sub-modules: the encoder and the retriever.
The encoder converts the passages into a d-dimensional embedding vector. For that, we import HuggingFaceEmbeddings from langchain.embeddings and we select the model we want to use to create the embeddings.
In our case, we have chosen sentence-transformers/all-MiniLM-l6-v2 because it creates 384-dimensional vectors with good quality to calculate the similarity between them. It is memory efficient and fast. You can check more details about this and other models here.
from langchain.embeddings import HuggingFaceEmbeddings
encoder = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-l6-v2",
model_kwargs={"device": "cpu"},
)The retriever splits the documents into passages of a certain length using CharacterTextSplitter from langchain.text_splitter .
In our case, we chose a length of 1000. We started with 100, as stated in the paper [1], but through some preliminary experiments, we found out that 1000 gives better results in our use case.
We then use the encoder to convert the passages into embeddings. Finally, we can store them in a vector store such as FAISS from langchain.vectorstores . From those, we can later retrieve the top k documents more similar to the question.
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
# create passages
text_splitter = CharacterTextSplitter(
chunk_size=1000,
chunk_overlap=0,
)
passages = text_splitter.split_documents(<YOUR DOCUMENTS>)
# store passages in embedding format in FAISS
db = FAISS.from_documents(passages, encoder)
# retrieve the most similar document to your question
db.similarity_search(<YOUR QUESTION>, k=4)[0].page_contentGenerator
As mentioned previously, the LLM for text generation is Llama2. It uses quantization, a technique to reduce the precision of how the weights are represented to minimize the memory required to use the model. Notice that since no free lunches exist, we are trading off memory size with accuracy.
This process brings advantages like the possibility of running LLMs with less resources but, also, disadvantages such as a reduction in performance due to quantization.
from langchain.llms import LlamaCpp
llm = LlamaCpp(
model_path="local/path/to/your/llama",
n_ctx=1024, # context length
temperature=0.7, # argument to control how much you want your LLM to follow your prompt
)Once we have our LLM, it is time to set the Prompt Template. Prompt Engineering is relevant when interacting with LLMs since it can significantly impact its output.
When we find a prompt that produces the desired output for the use case, we can create a template. LangChain offers a simple solution to create a Prompt Template. We start by defining the structure of the prompt and adding the dynamic variables in a dictionary format based on the user’s query. In our case, the {context} is given by the retriever and the user’s {question}.
from langchain import PromptTemplate
TEMPLATE = """
Use the following pieces of context to answer the question at the end taking
in consideration the dates.
{context}
Question: {question}
Answer:
"""
# create prompt template
prompt = PromptTemplate(
template=TEMPLATE, input_variables=["context", "question"]
)Now that we have defined our LLM and Prompt Template, we create an LLMChain from langchain.chains . It allows us to combine multiple components to create a coherent application.
In our case, we can create a chain that takes the user’s question and the context, formats it with a Prompt Template, and then passes the formatted response to the LLM to get a response.
from langchain.chains import LLMChain
# define the LLMChain
query_llm = LLMChain(
llm=llm, prompt=prompt, llm_kwargs={"max_tokens": 5000}
)
# get answer from llm based on context and question
query_llm.run({"context": context, "question": question})We are now ready to use our model and compare it with a base Llama2 model.
Results: Base Llama2 vs RAG Llama2
“What happened to the CEO of OpenAI?”
Considering the question, “What happened to the CEO of OpenAI?” Our goal is to show that without fine-tuning an LLM and using an RAG system, we can easily improve the prompt with relevant information which will make the LLM be more accurate and more updated in its answer. On the contrary, we expect the Base Llama2 to provide an accurate answer but is outdated since its training data did not contain information from last week.
Base Llama2:
OpenAI is a non-profit artificial intelligence research organization based in San Francisco, California, that focuses on developing friendly AI and ensuring its safe use. The CEO of OpenAI is Sam Altman, who has been at the helm since 2010 when he co-founded the company with Elon Musk, Greg Brockman, Ilya Sutskever, and Vince Conitzer. In terms of recent news, there haven’t been any major developments regarding the CEO or OpenAI specifically, but it is known that OpenAI has recently expanded its team by hiring an additional 15 employees to work on various projects related to AI, including the development of new models and tools for machine learning.
RAG Llama2:
Sam Altman stepped down from his role as CEO of OpenAI on November 20th, 2023. He was replaced by Mira Murati who assumed the position of interim CEO. However, Sam Altman returned to the company a few days later as CEO with a new initial board consisting of Bret Taylor (Chair), Larry Summers and Adam D’Angelo.
As we can see from the examples above, the RAG Llama managed to provide an answer with updated information without any additional fine-tuning process which would be expensive and time-consuming.
Conclusion
RAGs opened the possibility of deploying LLMs faster and in a more affordable way for organizations than fine-tuning LLMs for every single use case.
As we saw in our use case, adding just twelve documents about the scandal regarding OpenAI and its CEO from last week to the set of 10k news that we fetched from HuggingFace was enough. Our retriever was able to create enough context for our generator to produce a more accurate and updated answer about the topic.
When it comes to accessing external information RAGs are a very good option because they augment LLMs capabilities by retrieving relevant information from knowledge sources before generating a response. Nevertheless, when it comes to adjusting the LLM behavior to tailor its responses for a specific writing style with uncommon words or expressions, a combination of both might be more suitable.
References
[1] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv:2005.11401, 2021
[2] Vladimir Karpukhin, Barlas Oguz, Sewon Min, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering.arXiv:2004.04906, 2020
[3] Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-scale similarity search with GPUs. arXiv:1702.08734, 2017
[4] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv:1810.04805, 2019
[5] Michael R. Douglas. Large Language Models. arXiv:2307.05782, 2023.
[6] Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. arXiv:1910.13461, 2019
[7] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. Attention Is All You Need. arXiv:1706.03762, 2017.
More articles: https://zaai.ai/lab/