

Streamline Audio Analysis with State-of-the-Art Speech Recognition and Speaker Attribution Technologies
This article was co-authored by Luís Roque
Introduction
In our fast-paced world, we generate enormous amounts of audio data. Think about your favorite podcast or conference calls at work. The data is already rich in its raw form; we, as humans, can understand it. Even so, we could go further and, for example, convert it into a written format to search for it later.
To better understand the task at hand, we are introducing two concepts. The first is transcription, simply converting spoken language into text. A second one that we explore in this article is diarization. Diarization helps us give additional structure to the unstructured content. In this case, we are interested in attributing specific speech segments to different speakers.
With the above context, we address both tasks by using different tools. We use Whisper, a general-purpose speech recognition model developed by OpenAI. It was training on a diverse dataset of audio samples, and the researchers developed it to perform multiple tasks. Secondly, we use PyAnnotate, a library for speaker diarization. Finally, we use WhisperX, a research project that helps combine the two while solving some limitations of Whisper.
This article belongs to “Large Language Models Chronicles: Navigating the NLP Frontier”, a new weekly series of articles that will explore how to leverage the power of large models for various NLP tasks. By diving into these cutting-edge technologies, we aim to empower developers, researchers, and enthusiasts to harness the potential of NLP and unlock new possibilities.
Articles published so far:
- Summarizing the latest Spotify releases with ChatGPT
- Master Semantic Search at Scale: Index Millions of Documents with Lightning-Fast Inference Times using FAISS and Sentence Transformers
As always, the code is available on my Github.
Whisper: A General-Purpose Speech Recognition Model
Whisper is a general-purpose speech recognition model performing very well in various speech-processing tasks. It is reasonably robust at multilingual speech recognition, speech translation, spoken language identification, and voice activity detection.
At the core of Whisper lies a Transformer sequence-to-sequence model. The model jointly represents various speech-processing tasks as a sequence of tokens to be predicted by the decoder. The model can replace multiple stages of a traditional speech-processing pipeline by employing special tokens as task specifiers or classification targets. We can think of it as a meta-model for speech-processing tasks.
Whisper comes in five model sizes, targeting edge devices or large computing machines. It allows users to select the appropriate model for their use case and the capacity of their systems. Note that the English-only versions of some models perform better for English use cases.
PyAnnotate: Speaker Diarization Library
Speaker diarization is the process of identifying and segmenting speech by different speakers. The task can be beneficial, for example, when we are analyzing data from a call center, and we want to separate the customer and the agent’s voices. Companies can then use it to improve customer service and ensure company policy compliance.
PyAnnotate is a Python library specifically designed to support this task. The process is relatively simple. It preprocesses the data, allowing us to extract features from the raw audio file. Next, it produces clusters of similar speech segments based on the extracted features. Finally, it attributes the generated clusters to individual speakers.
WhisperX: Long-Form Audio Transcription with Voice Activity Detection and Forced Phoneme Alignment
As we saw in the previous sections, Whisper is a large-scale and weakly supervised model trained to perform several tasks in the speech-processing field. While it performs well in different domains and even in different languages it falls short when it comes to long audio transcription. The limitation comes from the fact that the training procedure uses a sliding window approach, which can result in drifting or even hallucination. In addition, it has severe limitations when it comes to aligning the transcription with the audio timestamps. This is particularly important to us when performing the speaker diarization.
To tackle these limitations, an Oxford research group is actively developing WhisperX. The Arxiv pre-print paper was published last month. It uses Voice Activity Detection (VAD), which detects the presence or absence of human speech and pre-segments the input audio file. It then cuts and merges these segments into windows of approximately 30 seconds by defining the boundaries on the regions where there is a low probability of speech (yield from the voice model). This step has an additional advantage: it allows using batch transcriptions with Whisper. It increases performance while reducing the probability of drifting or hallucination we discussed above. The final step is called forced alignment. WhisperX uses a phoneme model to align the transcription with the audio. Phoneme-based Automatic Speech Recognition (ASR) recognizes the smallest unit of speech, e.g., the element “g” in “big.” This post-processing operation aligns the generated transcription with the audio timestamps at the word level.
Integrating WhisperX, Whisper, and PyAnnotate
In this section, we integrate WhisperX, Whisper, and PyAnnotate to create our own ASR system. We designed our approach to handle long-form audio transcriptions while being able to segment the speech and attribute a specific speaker to each segment. In addition, it reduces the probability of hallucination, increases inference efficiency, and ensures proper alignment between the transcription and the audio. Let’s build a pipeline to perform the different tasks.
We start with transcription, converting the speech recognized from the audio file into written text. The transcribefunction loads a Whisper model specified by model_name and transcribes the audio file. It then returns a dictionary containing the transcript segments and language code. OpenAI designed Whisper also to perform language detection, being a multilanguage model.
def transcribe(audio_file: str, model_name: str, device: str = "cpu") -> Dict[str, Any]:
"""
Transcribe an audio file using a speech-to-text model.
Args:
audio_file: Path to the audio file to transcribe.
model_name: Name of the model to use for transcription.
device: The device to use for inference (e.g., “cpu” or “cuda”).
Returns:
A dictionary representing the transcript, including the segments, the language code, and the duration of the audio file.
“””
model = whisper.load_model(model_name, device)
result = model.transcribe(audio_file)
language_code = result[“language”]
return {
“segments”: result[“segments”],
“language_code”: language_code,
}
Next, we align the transcript segments using the align_segments function. As we discussed previously, this step is essencial for accurate speaker diarization, as it ensures that each segment corresponds to the correct speaker:
def align_segments(
segments: List[Dict[str, Any]],
language_code: str,
audio_file: str,
device: str = "cpu",
) -> Dict[str, Any]:
"""
Align the transcript segments using a pretrained alignment model.
Args:
segments: List of transcript segments to align.
language_code: Language code of the audio file.
audio_file: Path to the audio file containing the audio data.
device: The device to use for inference (e.g., “cpu” or “cuda”).
Returns:
A dictionary representing the aligned transcript segments.
“””
model_a, metadata = load_align_model(language_code=language_code, device=device)
result_aligned = align(segments, model_a, metadata, audio_file, device)
return result_aligned
With the transcript segments aligned, we can now perform speaker diarization. We use the diarize function, which leverages the PyAnnotate library:
def diarize(audio_file: str, hf_token: str) -> Dict[str, Any]:
"""
Perform speaker diarization on an audio file.
Args:
audio_file: Path to the audio file to diarize.
hf_token: Authentication token for accessing the Hugging Face API.
Returns:
A dictionary representing the diarized audio file, including the speaker embeddings and the number of speakers.
“””
diarization_pipeline = DiarizationPipeline(use_auth_token=hf_token)
diarization_result = diarization_pipeline(audio_file)
return diarization_result
After diarization, we assign speakers to each transcript segment using the assign_speakers function. It is the final step in our pipeline and completes our process of transforming the raw audio file into a transcript with speaker information:
def assign_speakers(
diarization_result: Dict[str, Any], aligned_segments: Dict[str, Any]
) -> List[Dict[str, Any]]:
"""
Assign speakers to each transcript segment based on the speaker diarization result.
Args:
diarization_result: Dictionary representing the diarized audio file, including the speaker embeddings and the number of speakers.
aligned_segments: Dictionary representing the aligned transcript segments.
Returns:
A list of dictionaries representing each segment of the transcript, including the start and end times, the
spoken text, and the speaker ID.
“””
result_segments, word_seg = assign_word_speakers(
diarization_result, aligned_segments[“segments”]
)
results_segments_w_speakers: List[Dict[str, Any]] = []
for result_segment in result_segments:
results_segments_w_speakers.append(
{
“start”: result_segment[“start”],
“end”: result_segment[“end”],
“text”: result_segment[“text”],
“speaker”: result_segment[“speaker”],
}
)
return results_segments_w_speakers
Finally, we combine all the steps into a single transcribe_and_diarize function. This function returns a list of dictionaries representing each transcript segment, including the start and end times, spoken text, and speaker identifier. Note that you need a Hugging Face API token to run the pipeline.
def transcribe_and_diarize(
audio_file: str,
hf_token: str,
model_name: str,
device: str = "cpu",
) -> List[Dict[str, Any]]:
"""
Transcribe an audio file and perform speaker diarization to determine which words were spoken by each speaker.
Args:
audio_file: Path to the audio file to transcribe and diarize.
hf_token: Authentication token for accessing the Hugging Face API.
model_name: Name of the model to use for transcription.
device: The device to use for inference (e.g., “cpu” or “cuda”).
Returns:
A list of dictionaries representing each segment of the transcript, including the start and end times, the
spoken text, and the speaker ID.
“””
transcript = transcribe(audio_file, model_name, device)
aligned_segments = align_segments(
transcript[“segments”], transcript[“language_code”], audio_file, device
)
diarization_result = diarize(audio_file, hf_token)
results_segments_w_speakers = assign_speakers(diarization_result, aligned_segments)
# Print the results in a user-friendly way
for i, segment in enumerate(results_segments_w_speakers):
print(f”Segment {i + 1}:”)
print(f”Start time: {segment[‘start’]:.2f}“)
print(f”End time: {segment[‘end’]:.2f}“)
print(f”Speaker: {segment[‘speaker’]}“)
print(f”Transcript: {segment[‘text’]}“)
print(“”)
return results_segments_w_speakers
Assessing the Performance of the Integrated ASR System
Let’s start by testing our pipeline with a short audio clip that I recorded myself. There are two speakers in the video that we need to identify. Also, notice the several hesitations in the speech of one of the speakers, making it hard to transcribe. We will use the base model from Whisper to assess its capabilities. For better accuracy, you can use the medium or large ones. The transcription is presented below:
Segment 1:
Start time: 0.95
End time: 2.44
Speaker: SPEAKER_01
Transcript: What TV show are you watching?
Segment 2:
Start time: 3.56
End time: 5.40
Speaker: SPEAKER_00
Transcript: Currently I’m watching This Is Us.
Segment 3:
Start time: 6.18
End time: 6.93
Speaker: SPEAKER_01
Transcript: What is it about?
Segment 4:
Start time: 8.30
End time: 15.44
Speaker: SPEAKER_00
Transcript: It is about the life of a family throughout several generations.
Segment 5:
Start time: 15.88
End time: 21.42
Speaker: SPEAKER_00
Transcript: And you can somehow live their lives through the series.
Segment 6:
Start time: 22.34
End time: 23.55
Speaker: SPEAKER_01
Transcript: What will be the next one?
Segment 7:
Start time: 25.48
End time: 28.81
Speaker: SPEAKER_00
Transcript: Maybe beef I’ve been hearing very good things about it.
Execution time for base: 8.57 seconds
Memory usage for base: 3.67GB
Our approach achieves its main goals with the transcription above. First, notice that the transcription is accurate and that we could ignore the speech hesitations successfully. We produced text with the correct syntax, which helps readability. The segments were well separated and correctly aligned with the audio timestamps. Finally, the speaker diarization was also executed adequately, with the two speakers attributed accurately to each speech segment.
Another important aspect is the computation efficiency of the various models on long-format audio when running inference on CPU and GPU. We selected an audio file of around 30 minutes. Below, you can find the results:
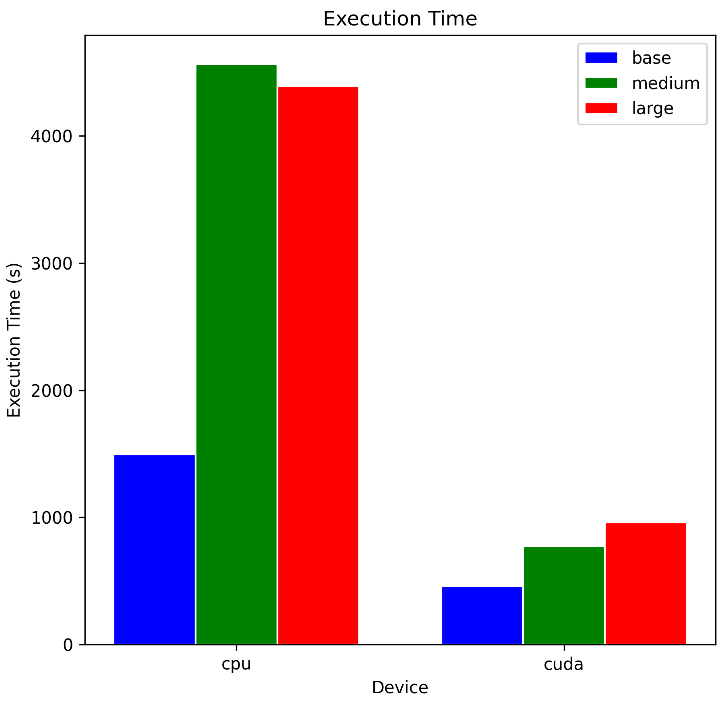
The main takeaway is that these models are very heavy and need to be more efficient to run at scale. For 30 minutes of video, we take around 70–75 minutes to run the transcriptions on the CPU and approximately 15 minutes on GPU. Also, remember that we need about 10GB of VRAM to run the large model. We should expect these results since the models are still in the research phase.
Conclusion
This article provides a comprehensive step-by-step guide to analyzing audio data using state-of-the-art speech recognition and speaker diarization technologies. We introduced Whisper, PyAnnotate, and WhisperX, forming a powerful integrated ASR system together — our approach produces promising results when working with long-form audio transcriptions. It also solves the main limitations of Whisper, hallucinating on long-form audio transcriptions, ensuring alignment between transcription and audio, accurately segmenting the speech, and attributing speakers to each segment.
Nonetheless, the computational efficiency of these models remains a challenge, particularly for long-format audio and when running inference on limited hardware. Even so, the integration of Whisper, WhisperX, and PyAnnotate demonstrates the potential of these tools to transform the way we process and analyze audio data, unlocking new possibilities for applications across various industries and use cases.
More articles: https://zaai.ai/lab/