

A comprehensive walkthrough of implementing and assessing Vosk-based speech recognition systems
This article was authored by Luis Roque.
Introduction
In our latest articles, we have been working extensively with different models and approaches to perform speech recognition. The open-source community has been developing solutions in this space for the last few years, giving us many options to select from. We have tried Whisper, WhisperX, and Whisper-JAX. All of them are based on the Whisper model trained and open-sourced by OpenAI recently. It is an Automatic Speech Recognition (ASR) system trained on multilingual and multiple tasks, making it general-purpose for speech and even language tasks.
One of the downsides of Whisper is the resources it takes to run it, especially in terms of execution time for longer audio files. In this article, we guide you through developing your enterprise-grade speech recognition model using Vosk, an open-source offline speech recognition toolkit. These models are significantly faster, which, in a significant number of use cases, is a decisive factor.
We dive into the performance of four Vosk speech recognition models, highlighting their strengths and weaknesses in terms of accuracy, execution time, and model size. Our findings reveal interesting insights, such as the 20% improvement in accuracy when transitioning from the smaller models to bigger ones. We also shed light on the trade-offs between speed and accuracy.
This article belongs to “Large Language Models Chronicles: Navigating the NLP Frontier”, a new weekly series of articles that will explore how to leverage the power of large models for various NLP tasks. By diving into these cutting-edge technologies, we aim to empower developers, researchers, and enthusiasts to harness the potential of NLP and unlock new possibilities.
As always, the code is available on my Github.
Understanding Speech Recognition
Speech recognition is the technology that enables computers and other devices to understand and process human speech, converting spoken language into written text. There are several steps in how these systems learn to convert speech to text. They automatically extract the raw audio waveform, essentially the audio signal’s acoustic features. Then, they map those features to phonemes and, using a language model, map the phonemes to words. More advanced systems also incorporate contextual information and semantic understanding to refine the transcript.
Speech recognition faces numerous challenges due to the complexity of human speech and the factors that introduce variability and ambiguity. Some challenges include speaker variability, background noise, disfluencies and filler words, and homophones and coarticulation. Speaker variability originates from different speakers’ unique accents, speaking styles, and pronunciations. Background noise, such as that found in noisy environments, interferes with the clarity of the speech signal, posing a challenge for accurate recognition. Disfluencies and filler words present another hurdle, as hesitations, repetitions, and filler words (e.g., “uh” and “um”) commonly occur in natural speech. Lastly, homophones and coarticulation create additional obstacles. Some words sound identical but have different meanings (homophones). The pronunciation of others can change depending on their position in a sentence (coarticulation). All these factors introduce ambiguity to the recognition task and make it harder for our models to perform accurately in certain tasks.
A Practical Guide to Building an Enterprise-Grade Speech Recognition Model with Vosk
We leverage the power of Vosk, an open-source offline speech recognition toolkit, to build a custom speech recognition system. Vosk offers a flexible and efficient solution for implementing speech recognition on various platforms, including Android, iOS, Windows, Linux, and Raspberry Pi. Its key features include support for multiple languages, speaker identification, compatibility with small-footprint devices, and large-scale server deployments.
In the following sections, we guide you through creating your speech recognition system using Vosk. We discuss popular frameworks and libraries, outline the steps for data collection, preprocessing, and model training, and provide tips for fine-tuning the model for specific use cases.
Data Collection
To evaluate different models, we will use the LibriSpeech ASR corpus dataset (CC BY 4.0). The dataset comprises recordings of LibriSpeech is a corpus of approximately 1000 hours of read English speech. The dataset is ideal for benchmarking speech recognition models as it provides various accents, speaking styles, pronunciations and background noises. As we discussed previously, these are often large obstacles for these models to perform well. We are interested in testing if Vosk is capable to work in these challenging environments.
Transcription and Word Representation
The Vosk API is quite rich; we have access to several attributes for each word transcribed. It returns the following attributes:
conf: Degree of confidence for the recognized word, ranging from 0 to 1.
start: Start time of pronouncing the word, in seconds.
end: End time of pronouncing the word, in seconds.
word: The recognized word.
To streamline our process, we create a WordVosk class that represents each word returned by the Vosk API:
class WordVosk:
"""A class representing a word from the JSON format for Vosk speech recognition API."""
def __init__(self, conf: float, start: float, end: float, word: str) -> None:
"""
Initialize a Word object.
Args:
conf (float): Degree of confidence, from 0 to 1.
start (float): Start time of pronouncing the word, in seconds.
end (float): End time of pronouncing the word, in seconds.
word (str): Recognized word.
"""
self.conf = conf
self.start = start
self.end = end
self.word = word
def to_dict(self) -> Dict[str, Union[float, str]]:
"""Return a dictionary representation of the Word object."""
return {
"conf": self.conf,
"start": self.start,
"end": self.end,
"word": self.word,
}
def to_string(self) -> str:
"""Return a string describing this instance."""
return "{:20} from {:.2f} sec to {:.2f} sec, confidence is {:.2f}%".format(
self.word, self.start, self.end, self.conf * 100
)
def to_json(self) -> str:
"""Return a JSON representation of the Word object."""
return json.dumps(self, default=lambda o: o.__dict__, sort_keys=True)As our primary interest lies in obtaining transcriptions, we create a Transcription class that takes a list of WordVosk objects. The to_raw_text method generates the final raw transcription:
class Transcription:
def __init__(self, words: List[WordVosk]) -> None:
self.words = words
def to_dict(self) -> List[Dict[str, Union[float, str]]]:
"""Return a dictionary representation of the Transcription object."""
return [word.to_dict() for word in self.words]
def to_raw_text(self) -> str:
"""Generate raw transcription text from the list of WordVosk objects."""
return " ".join(word.word for word in self.words)These classes help manage the output from the Vosk speech recognition API more efficiently, allowing for easier manipulation of the transcription results.
Implementing the Main Model Class
The ModelSpeechToText class is designed to handle speech-to-text conversion using the Vosk API. It takes an audio file and a Vosk model as input, and it returns a list of transcribed words.
class ModelSpeechToText:
def __init__(self, audio_path: str, model_path: str) -> None:
self.audio_path = audio_path
self.wf = wave.open(self.audio_path)
self.model = Model(model_path)The speech_to_text method transcribes speech to text using the Vosk API. It reads the audio file in chunks and processes each chunk using the KaldiRecognizer. The transcription results are collected in the results list.
def speech_to_text(self) -> List[Dict[str, Any]]:
"""Transcribe speech to text using the Vosk API."""
rec = KaldiRecognizer(self.model, self.wf.getframerate())
rec.SetWords(True)
results = []
frames_per_second = 44100
i = 0
print("Starting transcription process...")
while True:
data = self.wf.readframes(4000)
i += 4000
if len(data) == 0:
break
if rec.AcceptWaveform(data):
part_result = json.loads(rec.Result())
results.append(part_result)
if i % (frames_per_second * 60) == 0:
print(f"{i / frames_per_second / 60} minutes processed")
part_result = json.loads(rec.FinalResult())
results.append(part_result)
self.wf.close()
print("Transcription process completed.")
return resultsThe results_to_words method takes the transcription results and converts them into a list of WordVosk objects. This method allows us to easily manipulate and process the transcribed words.
@staticmethod
def results_to_words(results: List[Dict[str, Any]]) -> List[WordVosk]:
"""Convert a list of Vosk API results to a list of words."""
list_of_words = []
for sentence in results:
if len(sentence) == 1:
continue
for ind_res in sentence["result"]:
word = WordVosk(
conf=ind_res["conf"],
start=ind_res["start"],
end=ind_res["end"],
word=ind_res["word"],
)
list_of_words.append(word)
return list_of_wordsThe ModelSpeechToText is the final abstraction that we needed to efficiently use the Vosk API. It allows us to transcribe audio files and obtain a list of transcribed words, which are represented as WordVosk objects.
Evaluating Speech-to-Text Models Using Word Error Rate
To evaluate speech-to-text models, we can use the Word Error Rate (WER) metric. It is the average number of insertions, deletions, and substitutions needed to transform the hypothesis transcription into the reference transcription, divided by the total number of words in the reference transcription. Lower WER values indicate better performance.
The calculate_wer function computes the average WER between reference and hypothesis transcriptions:
def calculate_wer(
reference_transcriptions: List[str], hypothesis_transcriptions: List[str]
) -> float:
"""Calculate the average Word Error Rate (WER) between reference and hypothesis transcriptions.
Args:
reference_transcriptions: List of reference transcriptions.
hypothesis_transcriptions: List of hypothesis transcriptions.
Returns:
The average Word Error Rate (WER).
"""
assert len(reference_transcriptions) == len(
hypothesis_transcriptions
), "Reference and hypothesis lists should have the same length"
total_wer = 0
for ref, hyp in zip(reference_transcriptions, hypothesis_transcriptions):
total_wer += wer(ref, hyp)
return total_wer / len(reference_transcriptions)The evaluate_models function evaluates multiple speech-to-text models using a given evaluation dataset:
def evaluate_models(
models: List[ModelSpeechToText],
evaluation_dataset: List[Tuple[str, str]],
) -> List[Tuple[float, float, float]]:
"""Evaluate multiple speech-to-text models using a given evaluation dataset.
Args:
models: A list of ModelSpeechToText instances.
evaluation_dataset: A list of tuples containing the paths of the WAV files and their transcriptions.
Returns:
A list of tuples containing WER, execution time, and RAM usage for each model.
"""
if not evaluation_dataset:
print("The evaluation dataset is empty. Please check the dataset processing.")
return []
audio_files, reference_transcriptions = zip(*evaluation_dataset)
metrics = []
for model in models:
start_time = time.time()
hypothesis_transcriptions = transcribe_audio_files(model, audio_files)
memory = psutil.Process().memory_info().rss
elapsed_time = time.time() - start_time
wer = calculate_wer(reference_transcriptions, hypothesis_transcriptions)
metrics.append((wer, elapsed_time, memory / 1024 ** 3))
del model
gc.collect()
return metricsEvaluating Vosk Speech-to-Text Models: Accuracy, Execution Time, and Memory Consumption
First, let’s introduce the four models that we are testing. These models vary in size and complexity, which can potentially affect their performance. We compared them in terms of accuracy, execution time, and memory consumption. The models and their respective sizes are as follows:
-
- vosk-model-small-en-us-0.15 (Size: 40M)
-
- vosk-model-en-us-0.22 (Size: 1.8G)
-
- vosk-model-en-us-0.22-lgraph (Size: 128M)
-
- vosk-model-en-us-0.42-gigaspeech (Size: 2.3G)
Comparing Model Performance
After evaluating the four Vosk models on a dataset rich in accents and complex sentences, we observed noticeable differences in their performance. The best models in terms of accuracy were the 0.42-gigaspeech and 0.22, with the latter showing an improvement of about 20% compared to the smaller 0.15 and 0.22-lgraph models. This improvement can be attributed to the larger size of the 0.42-gigaspeech and 0.22 models, which allows them to better handle diverse accents and complex language structures.
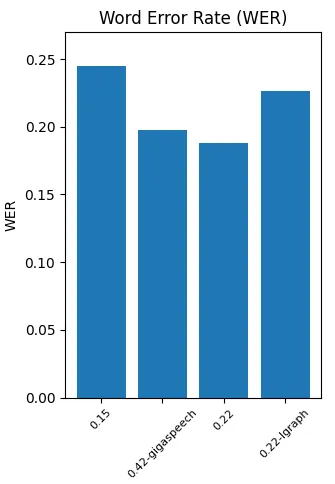
Word error rate (WER) for each model tested (image by author)
In terms of execution time, the 0.22 and 0.15 models were the best performers, taking around 150 seconds to complete the transcription process. On the other hand, the 0.22-lgraph model took considerably longer, at over 750 seconds. This highlights an interesting trade-off between accuracy and speed, with the 0.22 model emerging as an appealing option that achieves a good balance between performance and accuracy.
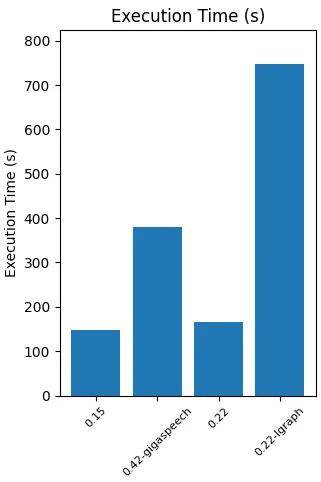
Execution time for each model tested (image by author)
Considering the results, the 0.22 model offers a promising combination of accuracy and efficiency, making it suitable for a wide range of applications.
Conclusion
In this article, we evaluated four different Vosk speech recognition models to compare their performance in terms of accuracy and execution time. We observed that the 0.42-gigaspeech and 0.22 models exhibited superior accuracy, with the 0.22 model demonstrating a 20% improvement over the smaller 0.15 and 0.22-lgraph models. This improvement can be attributed to the larger size of the 0.42-gigaspeech and 0.22 models, allowing them to handle diverse accents and complex language structures better.
When considering execution time, the 0.22 and 0.15 models emerged as the best performers. The 0.22 model, in particular, stands out as an appealing option that achieves a good balance between performance and accuracy. It is important to note that the choice of the optimal model depends on the specific requirements of each project. Always consider the trade-offs between speed and accuracy.
More articles: https://zaai.ai/lab/