

Enhancing Visual Impairment Navigation: Integrating GPT-4V(ision) and TTS for Advanced Sensory Assistance
This article was co-authored by Luís Roque and Rafael Guedes
Introduction
OpenAI’s latest developments have taken AI’s usability to a whole different level with the release of GPT-4V(ision) and Text-to-Speech (TTS) APIs. Why? Let’s motivate their usefulness with a use case. Walking down the street is a simple task for most of us, but for those with visual impairments, every step can be a challenge. Traditional aids like guide dogs and canes have been useful, but the integration of AI technologies opens up a new chapter in improving the independence and mobility of the blind community. Simple glasses equipped with a discreet camera would be enough to revolutionize how the visually impaired experience their surroundings. We will explain how it can be done using the latest releases from OpenAI.
Another interesting use case is to change our experience in museums and other similar venues. Imagine for a second that audio guide systems commonly found in museums are replaced by a discreet camera pinned to your shirt. Let’s assume that you are visiting an art museum. As you walk through the museum, this technology can provide you with information about each painting and it can do so in a specific style chosen by you. Let’s say that you are a bit tired and you need something engaging and lightweight, you could prompt it to ‘Give me some historical context on the painting but make it engaging and fun, you can even add some jokes to it’.
What about Augmented Reality (AR)? Can this new technology improve or even replace it? Right now, AR is seen as this digital layer that we can overlay on our visual perception of the real world. The problem is that this can quickly become noisy. These new technologies could replace AR in some use cases. In other cases, it can make AR personalized for each one of us so that we can experience the world at our own pace.
In this post, we will explore how to combine GPT-4V(ision) and Text-to-Speech to make the world more inclusive and navigable for the visually impaired. We will start by explaining how GPT-4V(ision) works and its architecture (we will use some open-source counterparts to get the intuition since OpenAI does not provide details about their model). We follow it with an explanation of what is TTS and what is the most common model architecture used to transform text into audio signal. Finally, we finish with a step-by-step implementation on how we can take advantage of both GPT-4V(ision) and TTS to help visually impaired people navigate the streets of Porto, Portugal.
As always, the code is available on our Github.
What is GPT-4V(ision)?
GPT-4, like GPT-3.5, is a large multimodal model capable of processing text inputs and producing text outputs [1]. In the latest OpenAI announcement, they shared that GPT-4 has been extended to be a multimodal Large Language Model (LLM). It means that the model is now able to receive additional modalities as input, in this case, images. Multimodal LLMs expand the impact of language-only systems with new interfaces and capabilities, opening the door for more elaborate use cases. You can see an example of using GPT-4V(ision) in the figure below, where vision and reasoning capabilities work together to detect some complex nuances in a picture.

Although OpenAI specifically says in its paper that …
‘Given both the competitive landscape and the safety implications of large-scale models like GPT-4, this report contains no further details about the architecture (including model size), hardware, training compute, dataset construction, training method, or similar.’
… we can try to estimate what the architecture of GPT-4V(ision) looks like.
We know that GPT-4V(vision) receives as input text and images. Therefore, it most likely has three main components:
-
- Encoders: Separate encoders for handling text and image data
-
- Attention mechanism: It employs advanced attention mechanisms, enabling the model to focus on the most relevant parts of both text and image inputs.
-
- Decoder: To produce the output text based on the latent space of the encoders combined with the attention layer.

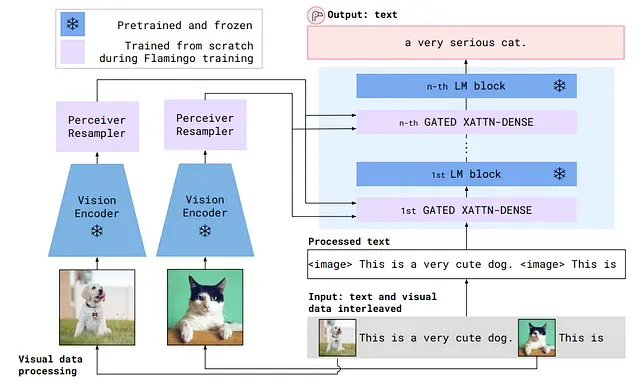
A similar architecture can be found in the 🦩 Flamingo model [2] created by DeepMind.
Flamingo is designed to handle textual and visual data as inputs in order to produce a free-form text as output. The authors define it as a Visual Language Model (VLM). There are 3 main components to the model, the input processing, the perceiver resampler, and the layers that integrate both data types and generate the output text.
Input Processing: Flamingo receives both visual and text data. The text undergoes the usual process of tokenization before entering the Language Model (LM), while the visual input is processed by the Vision Encoder (VE), which turns pixels into a more abstract representation of features.
Perceiver Resampler: This component further processes the visual features. It adds a sense of time to images (especially important in videos) and compresses the data into a more manageable format. This is key for efficiently combining visual and textual data later in the process.

Integration and Output: The processed visual and textual data are then integrated into the GATED XATTN-DENSE layer. This layer employs a cross-attention mechanism combined with a gating function to merge the two types of data effectively. The output from this layer feeds into the LM layer, which finally leads to the generation of free-form text output by a Transformer decoder.
GPT-4V(ision) API
The GPT-4V(ision) API from OpenAI allows for processing both visual and text information. We cover the main steps to use the API below.
Set Up Your Environment:
Install the Python dependencies in your environment, namely the OpenAI library.
pip install openaiImport the necessary libraries in your Python script.
import openai
import osConfigure API Parameters: Utilize the ChatCompletion class with specific parameters for handling multimodal (text and image) data.
Model Parameter: Set this to gpt-4-vision-preview enable the processing of both visual and textual data.
params = {
"model": "gpt-4-vision-preview",
"messages": PROMPT_MESSAGES,
"api_key": os.environ['OPENAI_API_KEY'],
"headers": {"Openai-Version": "2020-11-07"},
"max_tokens": 400,
}Messages Parameter: This needs to include both text and images. Images should be encoded in base64 format.
PROMPT_MESSAGES = [{
"role": "user",
"content": [
"<Your Prompt>",
{"image": image_in_base64_format}
],
}]Handle Images: Before including them in the API call, images must be converted to a base64 format.
import base64
def convert_image_to_base64(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')Execute the API Call: With the parameters set, make the API call to process the input data.
response = openai.ChatCompletion.create(**params)
print(response)What is Text-to-Speech?
TTS [4] technology transforms written text into spoken words. This complex process involves several stages, each handled by different models. First, a Grapheme-to-Phoneme model translates written text into phonetic units. Next, a Phoneme-to-Mel Spectrogram model transforms these phonemes into a visual frequency representation. Finally, a Mel-Spectrogram-to-Audio model, or Vocoder, generates the actual spoken audio from this representation.

-
- Grapheme-to-Phoneme Conversion: The first step involves converting written words (graphemes) into phonemes, the basic units of pronunciation. For instance, the phrase “Swifts, flushed from chimneys” would be converted into phonetic representation like “ˈswɪfts, ˈfɫəʃt ˈfɹəm ˈtʃɪmniz”. A model commonly used for this is the G2P-Conformer [5].
-
- Phoneme-to-Mel Spectrogram: Next, these phonemes are processed to create a mel-spectrogram, a visual representation of the sound frequencies over time. This is typically achieved using an encoder-decoder architecture, such as Tacotron2 [6]. In this model, a convolutional neural network (CNN) embeds the phonemes, which are then processed through a bidirectional long short-term memory (LSTM) network. The resulting mel-spectrograms are a key intermediate step, acting as a bridge between phonemes and the final audio output.
-
- Mel-Spectrogram-to-Audio Conversion: The final stage involves converting the mel-Spectrogram into actual audio. This is where a vocoder comes in, often using advanced generative models. WaveNet [7], developed by DeepMind, is a good example. It employs a deep neural network with dilated causal convolutions to ensure correct sequential processing. Each predicted audio sample is fed back into the network to predict the next, allowing the model to capture the long-range patterns in the audio signal.
Text-to-Speech API
OpenAI provides a TTS service accessible via an API, offering two quality levels and six distinct voices to cater to different needs and preferences.
Quality Options:
tts-1: Ideal for real-time applications, this option offers lower quality but benefits from reduced latency.
tts-1-hd: Suited for scenarios where higher audio quality is relevant and latency is not a problem.
Voice Selection:
OpenAI’s TTS API features six unique voices: alloy, echo, fable, onyx, nova, and shimmer.
Each voice has its own character; for instance, Fable resembles a podcast narrator’s voice.
You can preview these voices on OpenAI’s Text-to-Speech Guide.
Making an API Request:
To use OpenAI’s TTS API, send a request to https://api.openai.com/v1/audio/speech. Here’s what you’ll need:
Model Specification: Choose between tts-1 (low quality, low latency) or tts-1-hd (high quality, high latency) based on your needs.
Input Text: The textual content you want to convert into speech.
Voice Choice: Select from the available voices to find the one that best suits your content and audience.
Here’s a basic example of how to structure your API request:
response = requests.post(
"https://api.openai.com/v1/audio/speech",
headers={
"Authorization": f"Bearer {os.environ['OPENAI_API_KEY']}",
},
json={
"model": "tts-1",
"input": result.choices[0].message.content,
"voice": "fable",
},
)How to implement an application to help visually impaired people feel safer when walking down a street?
This section describes step by step how you can create the audio description of your video using GPT-4V(ision) and TTS from OpenAI. It also covers how you can add the generated audio to your video.
In our case, and as stated in the introduction, we created an audio guide to help a visually impaired person walking down the street by identifying the location of the obstacles and providing them with spatial information.
The process begins with importing necessary libraries and setting up the environment in Python. We use libraries such as cv2 for video processing and openai for accessing the GPT-4V(ision) and TTS models.
import base64
import cv2
import openai
import os
import requests
import time
from IPython.display import display, Image, Audio
from moviepy.editor import VideoFileClip, AudioFileClip
from moviepy.video.io.ffmpeg_tools import ffmpeg_extract_subclipNext, we load and process the video. The video is resized to a manageable resolution, ensuring we don’t exceed the token limits of OpenAI. Each frame is encoded in base64, the required format for OpenAI’s API.
video = cv2.VideoCapture("video.mp4")
base64Frames = []
while video.isOpened():
success, frame = video.read()
if not success:
break
frame = cv2.resize(frame, (512,512))
_, buffer = cv2.imencode(".jpg", frame)
base64Frames.append(base64.b64encode(buffer).decode("utf-8"))
video.release()
print(len(base64Frames), "frames read.")An important step is crafting the right prompt for GPT-4V(ision). A well-engineered prompt significantly influences the output that we get from the model. From our experiments, the 2 main components that influenced our outputs were:
Verbs like describe, narrate, tell;
Identifying the style of speech we wanted.
One of the first prompts that we tried was the following: ‘These are frames from a person walking in a city. Describe the elements and obstacles around you to help a blind person navigate them successfully. With this structure, the model tends to get extremely verbose and descriptive. Our use case requires a much less noisy output.
The prompt that worked for us was the following: ‘These are frames from a person walking. Narrate succinctly with short sentences like they do in GPS devices the elements and obstacles around you to help a blind person go navigate them successfully.’ This time the model gave us short sentences that allowed us to get just the essential information for street navigation. The result is below:
“Walk straight on a textured pathway, keep the building to your right. Continue forward with slight curve to the right. Stay straight, small overhang ahead on your right. Proceed, passing the overhang, continue on flat path. Straight ahead, approaching a well-lit area. After well-lit area, transition onto patterned pavement. Follow the tiled pavement with guiding lines straight ahead. Continue under the passageway, keeping the pillars parallel to you. Move through passageway, slight descent ahead. Pathway ends, prepare to stop at pedestrian crossing. Stand at crosswalk, wait for audible signal to cross the street.”
PROMPT_MESSAGES = [
{
"role": "user",
"content": [
"These are frames from a person walking. Narrate succinctly with short sentences like they do in GPS devices the elements and obstacles around you to help a blind person go through.",
*map(lambda x: {"image": x}, base64Frames[0::100]),
],
},
]
params = {
"model": "gpt-4-vision-preview",
"messages": PROMPT_MESSAGES,
"api_key": os.environ['OPENAI_API_KEY'],
"headers": {"Openai-Version": "2020-11-07"},
"max_tokens": 350,
}
result = openai.ChatCompletion.create(**params)
print(result.choices[0].message.content)Once we receive the description from GPT-4V(ision), the next step is converting this text into audio. We chose the fable voice for its clarity and resemblance to narration. The TTS API from OpenAI is used to transform the generated text into an audio file.
response = requests.post(
"https://api.openai.com/v1/audio/speech",
headers={
"Authorization": f"Bearer {os.environ['OPENAI_API_KEY']}",
},
json={
"model": "tts-1",
"input": result.choices[0].message.content,
"voice": "fable",
},
)
audio = b""
for chunk in response.iter_content(chunk_size=1024 * 1024):
audio += chunk
with open('audio.mp3', 'wb') as file:
file.write(audio)Finally, the last step is to merge the audio with the original video.
# Open the video and audio
video_clip = VideoFileClip("video.mp4")
audio_clip = AudioFileClip("audio.mp3")
# Concatenate the video clip with the audio clip
final_clip = video_clip.set_audio(audio_clip)
final_clip.write_videofile("video_audio.mp4")You can see the resulting video here.
Conclusion
OpenAI’s GPT-4V(ision) and TTS APIs open new possibilities to solve important use cases that can change the daily lives of many. We explored one that focuses on inclusivity for the visually impaired but we could have followed many others. As we discussed in the introduction, they also allow us to elevate our human experiences (e.g. museum tours), and cater them even more to individual preferences and circumstances.
During the implementation, we found that prompt engineering had a significant impact on tailoring the solution to our specific use case. In the future, other approaches such as fine-tuning or some type of Retrieval-augmented generation (RAG) might be adapted to the VLMs. We have been seeing how these methods are useful to make LLMs better for certain tasks and contexts. While the output shows the potential of these new models, there is still work to be done. As seen in our experiment, the VLM ‘speaks’ like if you could see when it says “Follow the tiled pavement with guiding lines straight ahead”. It also struggles to accurately distinguish between left and right, which is an interesting fact to explore further.
Despite these challenges, OpenAI’s latest developments show us a possible future where the world is more inclusive and experiences can be enhanced by AI.
References
[1] OpenAI. (2023). GPT-4 Technical Report. arXiv preprint arXiv:2303.08774.
[2] Alayrac, J.-B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Mensch, A., Millican, K., Reynolds, M., Ring, R., Rutherford, E., Cabi, S., Han, T., Gong, Z., Samangooei, S., Monteiro, M., Menick, J., Borgeaud, S., Brock, A., Nematzadeh, A., Sharifzadeh, S., Binkowski, M., Barreira, R., Vinyals, O., Zisserman, A., & Simonyan, K. (2022). Flamingo: a Visual Language Model for Few-Shot Learning. arXiv preprint arXiv:2204.14198.
[3] Brock, A., De, S., Smith, S. L., & Simonyan, K. (2021). High-performance large-scale image recognition without normalization. arXiv preprint arXiv:2102.06171.
[4] Maheshwari, H. (2021, May 11). Basic Text to Speech, Explained. Towards Data Science. Retrieved from https://towardsdatascience.com/text-to-speech-explained-from-basic-498119aa38b5
[5] Gulati, A., Qin, J., Chiu, C.-C., Parmar, N., Zhang, Y., Yu, J., Han, W., Wang, S., Zhang, Z., Wu, Y., et al. (2020). Conformer: convolution-augmented transformer for speech recognition. arXiv preprint arXiv:2005.08100.
[6] Shen, J., Pang, R., Weiss, R. J., Schuster, M., Jaitly, N., Yang, Z., Chen, Z., Zhang, Y., Wang, Y., Skerry-Ryan, R. J., Saurous, R. A., Agiomyrgiannakis, Y., & Wu, Y. (2018). Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions. arXiv preprint arXiv:1712.05884.
[7] van den Oord, A., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., Kalchbrenner, N., Senior, A., & Kavukcuoglu, K. (2016). WaveNet: A Generative Model for Raw Audio. arXiv preprint arXiv:1609.03499.
More articles: https://zaai.ai/lab/