

TimesFM: The Boom of Foundation Models in Time Series Forecasting
Explore How Google’s Latest AI Model Delivers Zero-Shot Forecasting Accuracy Using Over 307 Billion Data Points
This article was co-authored by Luís Roque and Rafael GuedesIntroduction
Forecasting is one of the most important use cases across all industries. One example is the retail industry. Several planning activities require predicting capabilities, and these contribute to optimizing margin, e.g., financial, production, or workforce planning. This can impact stock management, for instance, waste and leftovers or stockouts, customer service levels, and overall decision-making.
Developing an accurate forecasting model to support the above-mentioned processes requires a deep understanding of state-of-the-art (SOTA) forecasting methodologies. At the same time, it requires specific business domain knowledge to which they are applied. These two factors have been motivating the increasing interest in pre-trained models — they reduce the need for highly custom setups. Adding that motivation to the success of large pre-trained models in the Natural Language Processing (NLP) community, a.k.a. Large Language Models (LLMs), we have a research path with many contributors.
Theoretically, we know several similarities between language and time series tasks, such as the fact that the data is sequential. On the other hand, one key difference is that time series data is continuous, whereas NLP models typically work with discrete tokens (words, phrases). In NLP, tokenization is straightforward — language can be broken into distinct units like words or subwords. In contrast, with time series data, there are no natural “breakpoints” in continuous sequences. As a result, converting continuous time-series data into meaningful, discrete tokens that a model can process while preserving temporal patterns and relationships is particularly challenging.
Despite these challenges, large tech companies and research labs have been making significant efforts to develop foundation models tailored for time series forecasting. We call foundation models any model trained on vast amounts of data — often millions, billions, or even trillions of data points — enabling them to generalize across a wide range of tasks and domains. A key feature of these models is their ability to perform zero-shot inference. This means we can generate accurate forecasts for new datasets without retraining our model, reducing time and effort when applying them to different use cases.
In this article, we provide an in-depth explanation of TimesFM, Google’s new foundation model for time series forecasting. We explore its architecture and the main components that enable the model to perform zero-shot inference. We also discuss the differences between the 4 foundation models we have researched so far: TimesFM, Chronos, MOIRAI, and TimeGPT.
Following this theoretical overview, we apply TimesFM to a specific use case and dataset. We cover the practical implementation details and provide a thorough analysis of the performance of the model. Finally, we compare TimesFM’s performance with TiDE, Chronos, and MOIRAI on a public dataset.
As always, the code is available on our GitHub.
TimesFM: Training Data
Like other foundation models for time series, such as Chronos or Moirai, TimesFM [1] was designed to perform zero-shot forecasts as accurately as SOTA-supervised forecasting models.
A foundation model must be trained on a large volume of temporal data to perform accurately across various use cases. The final dataset must be sufficiently heterogeneous to represent the wide variety of domains the model needs to predict accurately, considering specific trends, multiple seasonalities, and different time granularities.
To achieve this, the research team at Google created a dataset based on 4 main sources:
- Google Trends data consists of search interest over time at hourly, daily, weekly, and monthly granularities. The data ranges from 2018 to 2019 for hourly granularity and from 2007 to 2021 for the other granularities, comprising a total of 0.5 billion time points.
- Wiki Pageviews captures hourly views of Wikipedia pages. The data, ranging from 2021 to 2023, was aggregated to cover other granularities (daily, weekly, and monthly), resulting in a dataset of 300 billion time points.
- Synthetic Data was generated to increase the diversity of seasonal patterns using a mixture of sine and cosine functions of different frequencies. This data also captures trends, such as linear and exponential patterns, with change points and step functions. The authors generated 3 million time series, each with 2,048 time points, adding 6 billion time points to the previous datasets.
- Other real-world datasets were incorporated, including publicly available datasets such as the M4 dataset in five different granularities (yearly, quarterly, monthly, daily, and hourly) with 23 million time points, the LibCity dataset with 15-minute granularity and 34 million time points, Favorita Sales with daily granularity and 139 million time points, Weather with 10-minute granularity and 2 million time points, Traffic with hourly granularity and 15 million time points, and Electricity with hourly granularity and 8 million time points.
TimesFM was trained on nearly 307 billion time points and 205.3 million time series.
Model Architecture
TimesFM was designed to predict a time series's future H time steps given a context set of C time points. Note that this model does not handle external information such as static covariates (e.g., product brand or category) or dynamic covariates (e.g., discounts or prices).
Input Layers
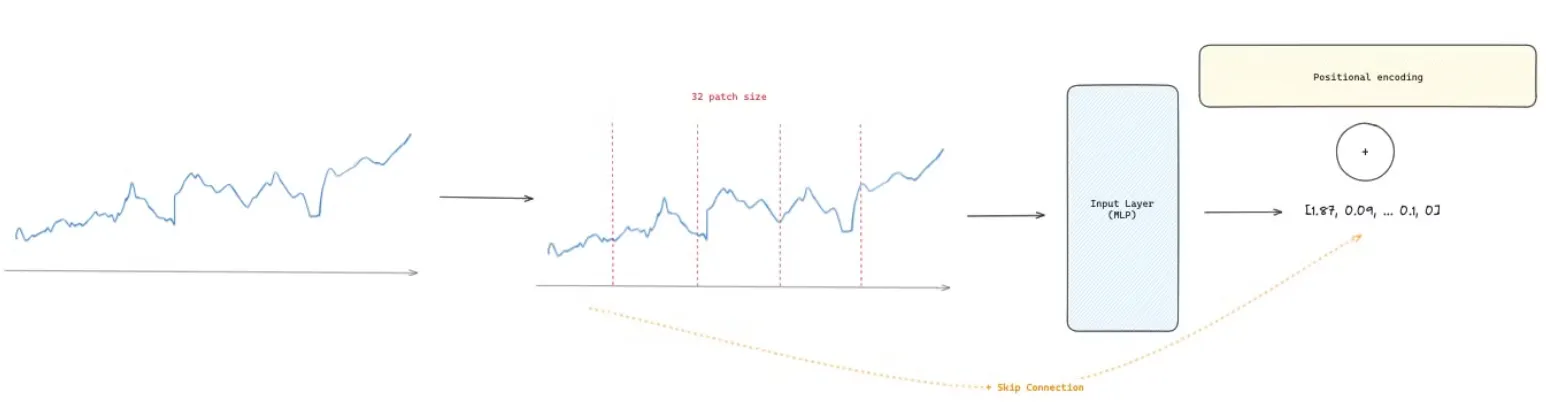
The input layers are responsible for converting the time series into input tokens for the transformer layers. This preprocessing is inspired by PatchTST [2], where tokenization involves breaking down the time-series data into non-overlapping patches of a predefined size (the number of patches is determined by context length/input patch length). By transforming the original series into patches, the data is converted from a continuous space to a discrete space (tokens), which offers several advantages:
- Enabling the attention mechanism to extract local semantic meaning by examining groups of time series data instead of focusing on individual time steps.
- Reducing the number of tokens fed to the encoder decreases the required memory and allows the model to process longer input sequences.
- Providing the model with longer sequences gives it more information to analyze and more meaningful temporal relationships to extract, potentially resulting in more accurate forecasts.
After the data is split into patches, these tokens are processed by a residual block comprised of a Multi-Layer Perceptron (MLP) with one hidden layer and a skip connection to create several 1,280-dimensional vectors (one per token). Finally, positional encoding is added to these d-dimensional vectors to generate the final representation that will feed into the transformer layers.
For example, as shown in Figure 2, the input layer breaks the time series into 5 tokens, each of length 32. Before feeding them into the transformer layer, these tokens are processed by an MLP block to create five 1,280-dimensional vectors. Afterward, absolute positional encoding, based on sine and cosine functions from the original Transformer architecture, is added to the output of the MLP.
Stacked Transformer
The transformer layers are stacked sequentially, each consisting of multi-head self-attention layers, followed by a feed-forward neural network. The authors used causal attention, and Figure 3 shows how it works. Causal attention ensures that each output token (prediction) can only attend to the input tokens (data points) that occur before it in the sequence. Using this approach we are preventing leaking unobserved data (at that point in time) into the trainig process.
During training, the model forecasts the next H time points based on different input window sizes. For example, the model is simultaneously trained on the first 32 time points to predict the next H time points, the first 64 time points to predict the next H time points, and so on. This progressive approach allows the model to learn from various window sizes during training.
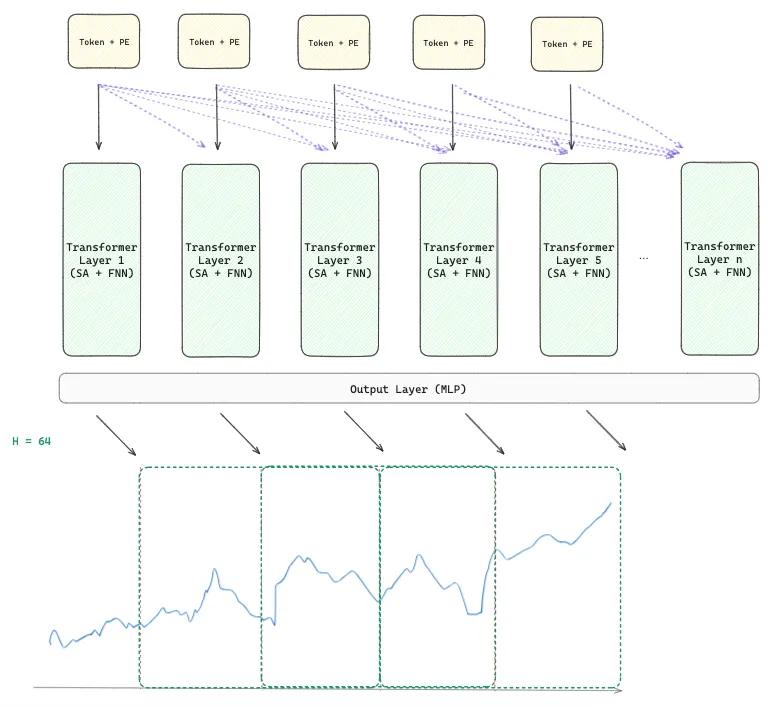
Output Layers
The output layer is responsible for mapping the output tokens into predictions of the part of the time series that follows the last input patch. As seen in the previous section, the model can predict an output patch with a different input size because it was trained based on a setup where the output and input patch sizes can be different. The authors found that this characteristic allows the model to predict a horizon of any length faster and more accurately.

Loss Function
The loss function used was Mean Squared Error since the authors focused on point forecasting. Nevertheless, they mentioned that it can be easily adaptable to probabilistic forecasting, and the code available to try this model already contains this feature.
TimeGPT vs Chronos vs MOIRAI vs TimesFM: The Comparison
This section presents the similarities and dissimilarities between the foundation models we have studied and published in previous articles.
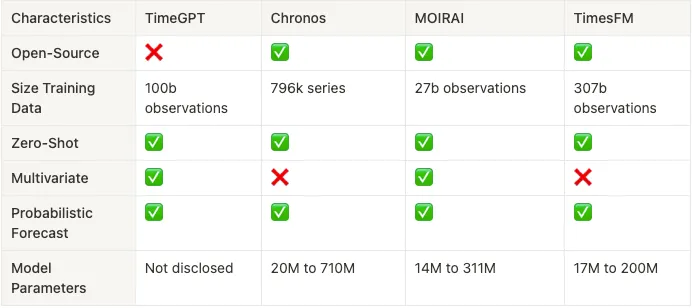
These models are designed for forecasting and time-series analysis, and the table below allows us to evaluate their features based on several characteristics. One important factor in our evaluation is whether the models are open-source: Chronos, MOIRAI, and TimesFM are open for public access and modification, while TimeGPT is proprietary. In terms of the size of the training data, TimesFM stands out with a significantly larger dataset. Still, we must remember that more training data does not necessarily correlate with better model performance. Actually, we prefer smaller datasets since models trained on them can be updated more frequently.
As they all are foundation models, they all support zero-shot learning. One additional difference between the models is that Chronos and TimesFM are limited to univariate analysis. All models are equipped with probabilistic forecasting capabilities, allowing them to predict outcomes with uncertainty estimates. The number of model parameters, an indicator of complexity, is within similar ranges across the models. Interestingly, these models use far fewer parameters than their counterparts for language tasks (LLMs typically come in sizes of 7b, 70b, and even 405b parameters).
TimesFM vs. Chronos vs. MOIRAI: a comparison in a public dataset
In this section, we will use TimesFM to forecast tourism visitors to Australia using a real-world dataset that is publicly available under the CC-BY-4.0 license. Subsequently, we will compare the forecasting performance of TimesFM against Chronos (its large version), Moirai, and TiDE. To access the code that generates the forecasts with Chronos and TiDE, please refer to this article, and for Moirai, please refer to this one.
Although TimesFM cannot use external information, other models like TiDE and Moirain can. Therefore, we enhanced the dataset with economic covariates (e.g., CPI, Inflation Rate, GDP) extracted from Trading Economics. It uses economic indicators based on official sources. We also perform some preprocessing to further increase the usability of the dataset. The final structure of the dataset is the following:
- EUnique ID: A combination of encoded names for States, Zones, Regions within Australia, and the purpose of the visit (e.g., business, holiday, visiting, other).
- Time: Represents the time dimension of the dataset.
- Target: The target variable to predict, in this case, the number of visits.
- Dynamic Covariates: Economic indicators such as CPI, Inflation Rate, and GDP that vary over time.
- Static Covariates (Static_1 to Static_4): Extracted from the unique ID, these provide additional information for analysis, including geographic and purpose-of-visit details.
We stored the new version of the dataset here so that our experiments can be easily reproduced.
We start by importing the libraries and setting global variables. We set the date column, target column, dynamic covariates, the frequency of our series and the forecast horizon.
import pandas as pd
import numpy as np
import utils
import timesfm
from datasets import load_dataset
import warnings
warnings.filterwarnings("ignore")
TIME_COL = "Date"
TARGET = "visits"
FORECAST_HORIZON = 8 # months
FREQ = "MS"
After that, we load our dataset, which already has the exogenous features mentioned in the dataset description.
# load data
df = pd.DataFrame(load_dataset("zaai-ai/time_series_datasets", data_files={'train': 'data.csv'})['train']).drop(columns=['Unnamed: 0'])
df[TIME_COL] = pd.to_datetime(df[TIME_COL])
print(f"Distinct number of time series: {len(df['unique_id'].unique())}")
df.head()
Distinct number of time series: 304
Once the dataset is loaded, we can split the data between train and test (we decided to use the last 8 months of data for our test set).
# 8 months to test
train = df[df[TIME_COL] <= (max(df[TIME_COL])-pd.DateOffset(months=FORECAST_HORIZON))]
test = df[df[TIME_COL] > (max(df[TIME_COL])-pd.DateOffset(months=FORECAST_HORIZON))]
print(f"Months for training: {len(train[TIME_COL].unique())} from {min(train[TIME_COL]).date()} to {max(train[TIME_COL]).date()}")
print(f"Months for testing: {len(test[TIME_COL].unique())} from {min(test[TIME_COL]).date()} to {max(test[TIME_COL]).date()}")
Months for training: 220 from 1998–01–01 to 2016–04–01 Months for testing: 8 from 2016–05–01 to 2016–12–01
With the dataset split, we can forecast using TimesFM. For that, we need to load the model from Hugging Face and set the following parameters:
- horizon_len — which is the forecast horizon we defined earlier.
- context_len — how many items in the sequence the model can attend to (any positive integer up to 512).
- The remaining hyper parameters must be fixed because the 200M model expects a input patch of 32, a output patch of 128, 20 layers and a model dimension of 1200.
tfm = timesfm.TimesFm(
context_len=512,
horizon_len=FORECAST_HORIZON,
input_patch_len=32,
output_patch_len=128,
num_layers=20,
model_dims=1280,
backend="cpu",
)
tfm.load_from_checkpoint(repo_id="google/timesfm-1.0-200m")
forecast_df = tfm.forecast_on_df(
inputs=train.loc[:,[TIME_COL, 'unique_id', TARGET]].rename(columns={TIME_COL:'ds'}),
freq=FREQ,
value_name=TARGET,
num_jobs=-1,
)
Once the forecast has finished, we can plot the ground truth values and the predictions, and we will check the top 3 series with more visits.

Figure 5 shows that TimesFM struggled to forecast the first two series, especially the huge drop in the first series. The third series looks much better, and we have a nearly perfect overlap between the actuals and the forecast. It is also worth mentioning that the actuals are always within the prediction interval.
Having obtained the forecast from TimesFM, we can now load the forecast generated by TiDE, Chronos and Moirai and compute forecasting performance metrics for comparison. For better interpretability, we have used the Mean Absolute Percentage Error (MAPE) as our comparison metric.

As shown in Figure 6, TimesFM had the lowest MAPE in 4 out of 8 months, demonstrating a performance similar to Chronos, the most accurate foundation model we have researched so far.
We also tested all models on 4 large private datasets, and the results were consistent with what we are reporting in this article. Testing with private datasets is very important for foundational models since there is a risk that the specific public dataset used in the evaluation could have been part of the original training data of the models. If that is the case, we would introduce bias in the evaluation process.
Conclusion
In this article, we explored TimesFM, a foundation model for time-series forecasting developed by Google. Our analysis shows that TimesFM outperforms TiDE and performs similarly to Chronos on this public dataset. In the case of TiDE, the model had access to external information and was specifically trained on this dataset. Still, TimesFM outperformed it in 6 out of 8 months. It’s worth mentioning that we did not perform any hyperparameter tuning on TiDE, which could lead to improvements in its performance. Regarding Chronos, since both models had access to the same information, we expected a similar performance, which was the case. Still, Chronos had a slightly lower MAPE than TimesFM in 4 out of 8 months.
The field of foundation models in time series forecasting seems to be converging, similar to what we have observed with large models in language tasks. As datasets grow larger and models become more complex, the marginal improvements in performance start to diminish. There are two key aspects we are particularly interested in: 1) how to effectively fine-tune these models in the context of time series forecasting, as it has proven successful for language tasks, and 2) the need for a better evaluation framework for these types of models.
About me
Serial entrepreneur and leader in the AI space. I develop AI products for businesses and invest in AI-focused startups. Founder @ ZAAI | LinkedIn | X/Twitter
References
A[1] Abhimanyu Das, Weihao Kong, Rajat Sen, Yichen Zhou. A decoder-only foundation model for time-series forecasting. arXiv:2310.10688, 2023.
[2] Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam. A Time Series is Worth 64 Words: Long-term Forecasting with Transformers. arXiv:2211.14730, 2022.
All images are by the authors unless noted otherwise.