

TimeGPT vs TiDE: Is Zero-Shot Inference the Future of Forecasting or Just Hype?
This article was co-authored by Luís Roque and Rafael GuedesIntroduction
Forecasting is one of the core domains of Artificial Intelligence (AI) in academic research and industrial applications. In fact, it is probably one of the most ubiquitous challenges we can find across all industries. Accurately predicting future sales volumes and market trends is essential for businesses to optimize their planning processes. This includes enhancing contribution margins, minimizing waste, ensuring adequate inventory levels, optimizing the supply chain, and improving decision-making overall.
Developing a forecast model represents a complex and multifaceted challenge. It requires a deep understanding of State-Of-The-Art (SOTA) forecasting methodologies and the specific business domain to which they are applied. Furthermore, the forecast engine will act as a critical infrastructure within an organization, supporting a broad spectrum of processes across various departments. For instance:
- The Marketing team leverages the model to inform strategic decisions regarding investment allocations for upcoming periods, such as the next month or quarter.
- The Procurement team utilizes the model to make informed decisions about purchase quantities and timing from suppliers, optimizing inventory levels and reducing waste or shortages.
- The Operations team uses the forecasts to optimize the production lines. They can deploy resources and workforce to meet expected demand while minimizing operational costs.
- The Finance team relies on the model for budgeting purposes, using forecast data to project monthly financial requirements and allocate resources accordingly.
- The Customer Service team uses the forecast to anticipate customer inquiry volumes, allowing the team to right-size staffing levels while ensuring high-quality customer service and minimizing wait times.
Recent advancements in forecasting have also been shaped by the successful development of foundational models across various domains, including text (e.g., ChatGPT), text-to-image (e.g., Midjourney), and text-to-speech (e.g., Eleven Labs). The wide adoption of these models has resulted in the introduction of models like TimeGPT [1], designed to generate predictions on previously unseen data through zero-shot inference. These models leverage the methodologies and architectures that resemble their predecessors in text, image, and speech. A general pre-trained model would constitute a paradigm shift in tackling forecasting tasks. It would make it more accessible to organizations, reduce the computation complexity, and make it more accurate overall.
In this article, we provide an in-depth explanation of the possible architecture behind TimeGPT. We also cover the main components that allow the model to perform zero-shot inference. Following this theoretical overview, we then apply TimeGPT to a specific use case and dataset. We cover the practical implementation details and conduct a thorough analysis of the model’s performance. Finally, we compare the performance of TimeGPT with TiDE [2], an ‘embarrassingly’ simple MLP that beats Transformers in forecasting use cases.
As always, the code is available on our GitHub.
TimeGPT
TimeGPT [1] was the first foundation model for time series forecasting, characterized by its ability to generalize across diverse domains. It can produce precise forecasts on datasets beyond those used during its training phase. The field of research surrounding foundation models for time series forecasting has been experiencing significant growth recently. Notable recent contributions include “MOMENT” developed by researchers at Carnegie Mellon University (CMU) [3], “TimesFM” from Google [4], “Lag-Llama,” a collaborative effort between Morgan Stanley and ServiceNow [5], and “Moirai” from Salesforce [6]. We plan to cover other time series foundational models for time series forecasting in the future.
TimeGPT leverages transfer learning to perform well in a zero-shot inference setup. It was trained with 100 billion data points from a large collection of publicly available datasets of various domains such as economics, demographics, healthcare, weather, IoT sensor data, energy, web traffic, sales, transport, and banking.
The extensive diversity of domains allows the model to capture complex patterns such as multiple seasonalities, cycles of different lengths, and evolving trends. Additionally, the datasets exhibit a range of noise levels, outliers, drift, and other characteristics. While some consist of clean data with regular patterns, others have unexpected events and behaviors where trends and patterns may fluctuate over time. These challenges provide many scenarios for the model to learn from, improving its robustness and generalization capabilities.
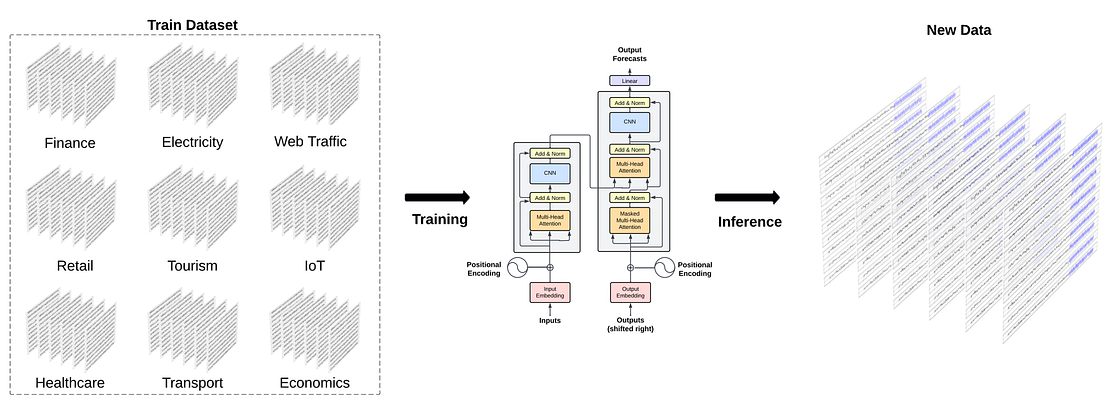
Architecture
TimeGPT is a Transformer-based model specifically designed for time series forecasting, incorporating a self-attention mechanism within an encoder-decoder architecture. By leveraging the self-attention mechanism, it can dynamically weigh the significance of different points in the time series.
The model receives a window of historical values (y) and exogenous covariates (x) as input. The covariates may include additional time series data and/or binary variables that denote specific events, such as public holidays. These inputs are augmented with sequential information by integrating local positional embeddings. This allows the model to be aware of the temporal dependencies. While not explicitly stated by the authors, we believe all the inputs are concatenated after the positional encoding, producing the final input to feed the encoder.

The positional encodings are also not defined by the authors. We assume that they use the sine and cosine functions from the foundational transformer architecture paper [7]. These functions are characterized by varying frequencies but maintain the same dimensionality as the input data.
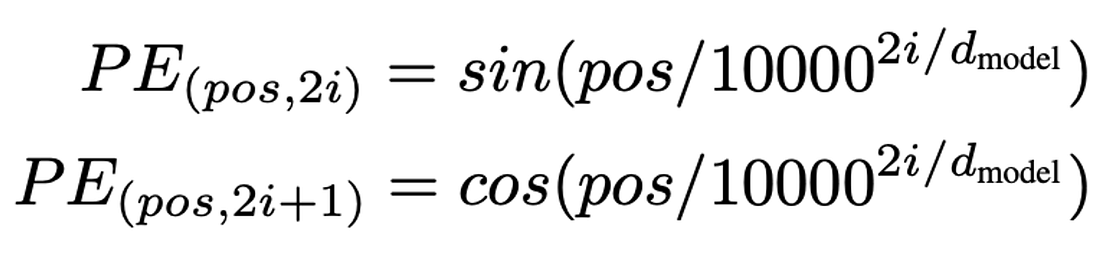
Once augmented with positional encodings, the input vector is introduced into the encoder. Within the encoder, a multi-head attention layer evaluates and assigns weights to the various elements within the input sequence, reflecting their relative importance. Subsequently, this representation is processed by a fully connected feed-forward network. It allows the generation of a representation that captures more complex relationships between the elements in the sequence. The output is then fed to the decoder part of the architecture.
In addition to processing the encoder’s output, the decoder operates in an auto-regressive process. It incorporates previously generated outputs before producing the forecasts of the subsequent time step (i+1). It leverages the attention mechanism to capture the complex relationships between the hidden states produced by the encoder and the previously generated outputs. This approach enables the decoder to effectively synthesize the contextual and sequential information encapsulated in the encoder’s representations with its own iterative predictions.

Finally, the linear layer is responsible for mapping the decoder’s output to a vector of values with the same length as the forecast horizon (h).
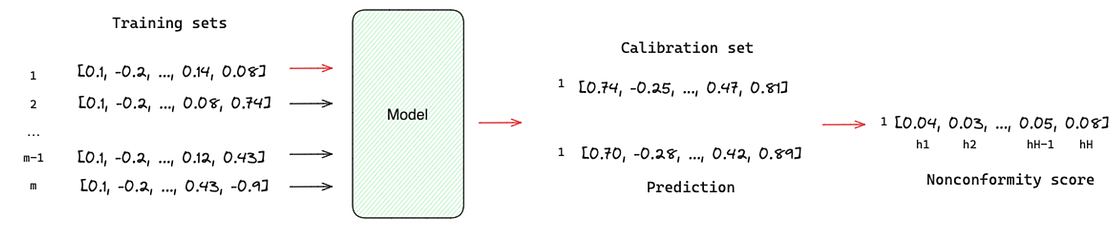
TimeGPT can generate a probabilistic distribution of potential outcomes, i.e., the estimation of forecast intervals. The authors relied on conformal prediction [8] based on historical errors to estimate the forecast intervals. Unlike traditional methods, conformal prediction does not require distributional assumptions, and it can be achieved by:
- Creating M training and calibration sets;
- Forecasting each calibration set with the model;
- For each forecast horizon h, the absolute residual values between the model’s predictions and the actual outcomes within the calibration set are calculated. These calculated residuals are called nonconformity scores.
- We select a specific quantile from the distribution of nonconformity scores for each forecast horizon h. The chosen quantile determines the forecast interval’s coverage level, with higher quantiles resulting in broader intervals.
The forecast intervals are given by the predicted value ± the final nonconformity score.
TimeGPT vs. TiDE: a comparison in a real use case
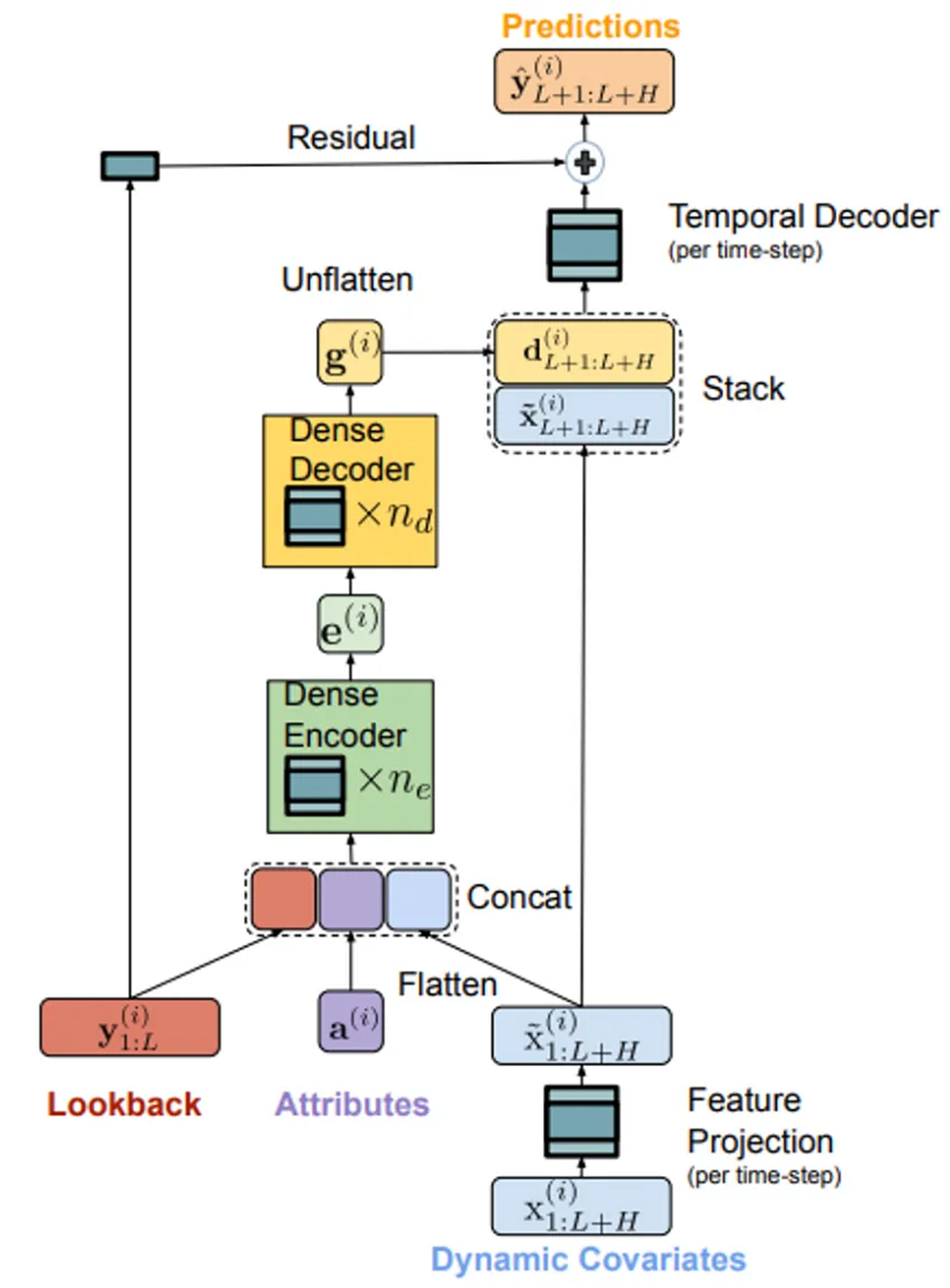
In this section, we will use TimeGPT to forecast sales using a real-world dataset from one of our clients. Subsequently, we compare the forecasting performance of TimeGPT with TiDE, using the same cutoff date for analysis.TiDE [2] is a novel multivariate time-series model that can use static covariates (e.g., brand of a product) and known or unknown dynamic covariates in the forecast horizon (e.g., price of a product) to generate an accurate forecast. Unlike the complex architecture of Transformers, TiDE is based on a simple Encoder-Decoder architecture with a Residual connection where:
- The Encoder is responsible for mapping the past target values and the covariates of a time series into a dense representation of features. First, the feature projection reduces the dimensionality of the dynamic covariates. Then, the Dense Encoder receives the output of the Feature Projection concatenated with static covariates and the past values to map them into a single embedding representation.
- The Decoder receives the embedding representation and converts it into future predictions. The Dense Decoder maps the embedding representation into a vector per time-step in the horizon. Afterward, the Temporal Decoder combines the output of the Dense Decoder with the projected features of that time step to produce the predictions.
- Finally, the Residual Connection linearly maps the look-back to a vector with the size of the horizon, which is added to the output of the Temporal Decoder to produce the final predictions.
The dataset contains 195 unique time series, each detailing weekly sales data specifically for the United States market. In addition to historical sales data, the dataset has information on two types of marketing events. We incorporate US public holidays and binary seasonal features to augment the dataset, in this case, week and month identifiers. The forecasting horizon is 16 weeks, i.e., we want to predict 16 weeks into the future.
We start by importing the libraries:import matplotlib.pyplot as plt import os import pandas as pd import utils from nixtlats import TimeGPT from nixtlats.date_features import CountryHolidays from dotenv import load_dotenv from sklearn.preprocessing import MinMaxScaler, OrdinalEncoder load_dotenv()Then, we initiate the TimeGPT class by providing a TimeGPT token. You can request one from the Nixtla website.
timegpt = TimeGPT(token = os.environ.get("TIMEGPT_KEY"))
timegpt.validate_token()
When preparing to load your dataset after validating the authentication token, ensure the following:
- The target variable should be numeric and without missing values.
- Ensure no gaps exist in the date sequence from the start to the end date.
- The date column must be in a format recognizable by Pandas.
- Per the documentation, data normalization is handled internally. Therefore, you can skip that step.
- For forecasting multiple time series, include a column to uniquely identify each series, which will be used as an argument in the forecasting function.
- Exogenous features require a separate dataset for the forecast horizon.
# read data frame and parse dates as datetime
df = pd.read_csv('data/data.csv', parse_dates=['delivery_week'])
As discussed, to augment the dataset, we add binary seasonal features for week and month as follows:
# add week and month to df df['week'] = df['delivery_week'].dt.isocalendar().week df['month'] = df['delivery_week'].dt.month # one hot encode week and month df = pd.get_dummies(df, columns=['week', 'month'], dtype=int)
Now, we can truncate our dataset to be used by TimeGPT for forecasting. Additionally, we will create a holdout set with the actual sales data within the forecast horizon and the corresponding exogenous features for the same period.
# Truncate data frame forecast_df = df[df['delivery_week'] < "2023-10-16"] # Let's use the last x weeks of actuals for the holdout set holdout_df = df[(df['delivery_week'] >= "2023-10-16") & (df['delivery_week'] <= "2024-02-05")]After splitting the data, we can proceed to feed the training and holdout datasets into the
forecast() function. We need to set the following parameters:
- df - data frame with historical data
time_col- column with temporal informationtarget_col- column with historical dataX_df- data frame with exogenous features for the forecast horizondate_features- allows the specification of new exogenous features like the public holidays in the USh- define the forecast horizonlevel- forecast intervals (80% confidence)freq- frequency of the data, in our case, it is weekly on Mondayid_col- column that identifies each time series in a multivariate scenariomodel- TimeGPT has two models one for short term and another for long term. The long-term should be used when there is more than one seasonal period in the forecast horizon.add_history- return the fitted values in historical data
# create list with seasonal exogenous features
EXOGENOUS_FEATURES = [x for x in df.columns if ('week_' in x) or ('month_' in x)]
timegpt_fcst_ex_vars_df = timegpt.forecast(
df=forecast_df[['unique_id', 'delivery_week', 'target', 'marketing_events_1', 'marketing_events_2'] + EXOGENOUS_FEATURES],
time_col='delivery_week',
target_col='target',
X_df=holdout_df[['unique_id', 'delivery_week', 'marketing_events_1', 'marketing_events_2'] + EXOGENOUS_FEATURES],
date_features=[CountryHolidays(['US'])],
h=17,
level=[80],
freq='W-MON',
id_col='unique_id',
model='timegpt-1',
add_history=True,
)
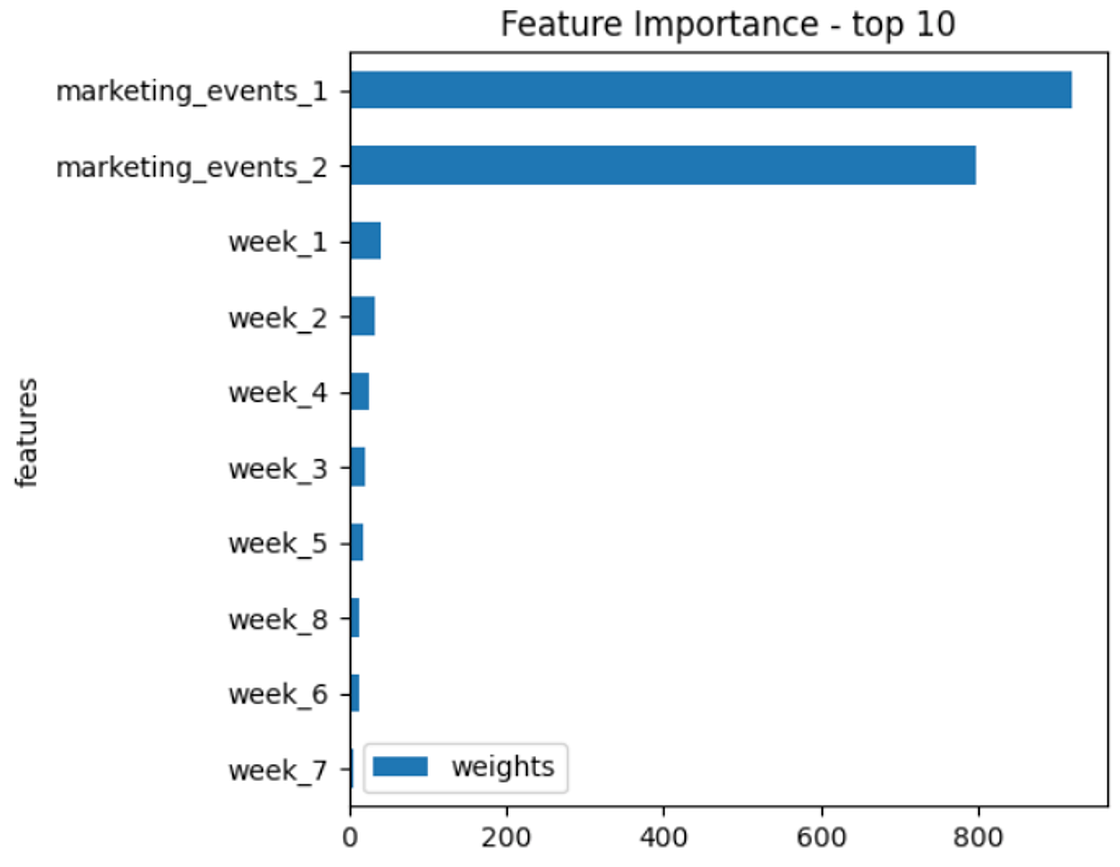
The forecast takes just a few minutes to run. It then returns a data frame with the fitted values for historical data and the predictions for the forecast horizon. It also returns the importance of the exogenous covariates in the forecast.
timegpt.weights_x.head(10).sort_values(by='weights').plot.barh(x='features', y='weights')
plt.title('Feature Importance - top 10')
plt.show()
In our case, we extracted the ten most important covariates, which shows that the marketing events have the highest importance. Conversely, the seasonal and holidays covariates have a residual importance.
Since we set add_history=True, we can plot the fitted values and the predictions. We selected the six series with the highest volume in the holdout set. They are more relevant for the business and likely easier to forecast with more stable patterns.
# get series ordered by volume in a descending way
series = holdout_df.groupby('unique_id')['target'].sum().reset_index().sort_values(by='target', ascending=False)['unique_id'].tolist()
timegpt.plot(
forecast_df[['unique_id', 'delivery_week', 'target']],
timegpt_fcst_ex_vars_df,
time_col='delivery_week',
target_col='target',
unique_ids=series[:6],
level=[80],
)
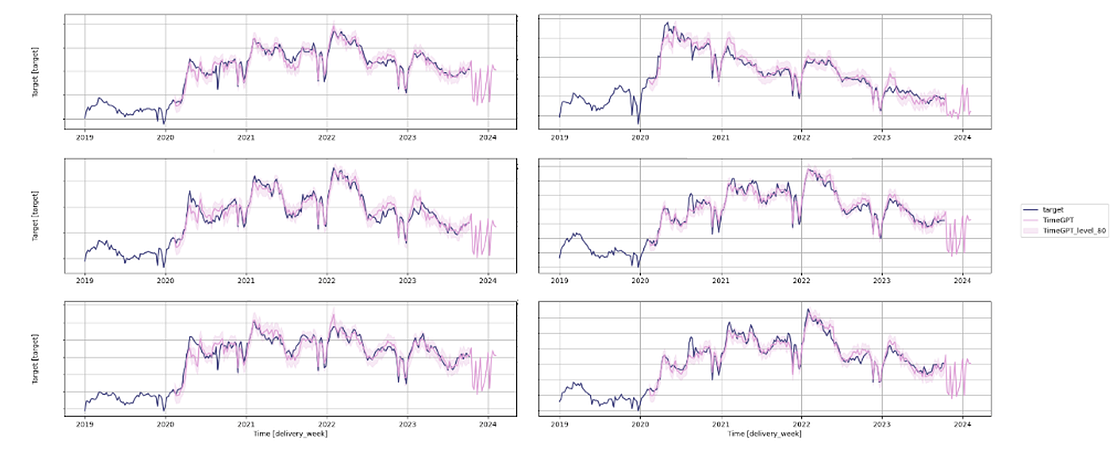
Figure 10 shows that while the fitted values align well with the actual values, the forecasts are inconsistent. They show uniform patterns across most series except in one case (we can find it in the top right corner). Additionally, all predictions show consecutive unexpected spikes, which we did not expect to see.
Having obtained the forecast from TimeGPT, we can now load the forecast generated by TiDE and compute forecasting performance metrics for comparison. We have used the Mean Absolute Percentage Error (MAPE) as our comparison metric to maintain confidentiality and prevent the disclosure of actual sales volumes.
# load the forecast from TiDE and TimeGPT
tide_model_df = pd.read_csv('data/tide.csv', parse_dates=['delivery_week'])
timegpt_fcst_ex_vars_df = pd.read_csv('data/timegpt.csv', parse_dates=['delivery_week'])
# merge data frames with TiDE forecast and actuals
model_eval_df = pd.merge(holdout_df[['unique_id', 'delivery_week', 'target']], tide_model_df[['unique_id', 'delivery_week', 'forecast']], on=['unique_id', 'delivery_week'], how='inner')
# merge data frames with TimeGPT forecast and actuals
model_eval_df = pd.merge(model_eval_df, timegpt_fcst_ex_vars_df[['unique_id', 'delivery_week', 'TimeGPT']], on=['unique_id', 'delivery_week'], how='inner')
utils.plot_model_comparison(model_eval_df)
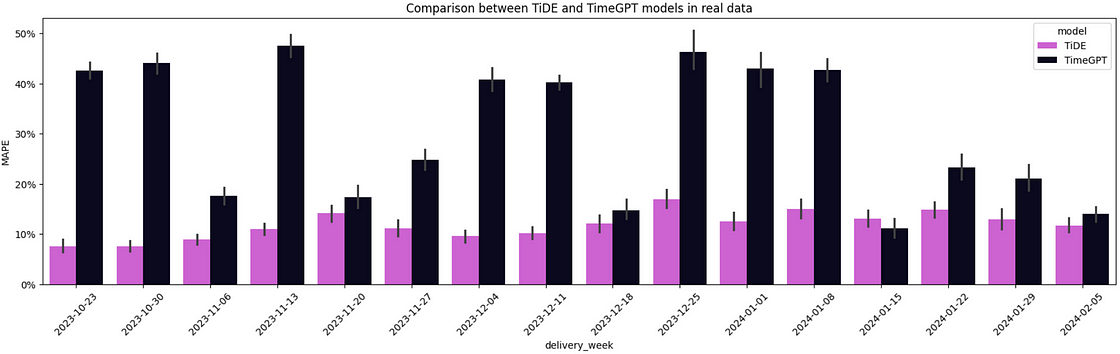
As shown in Figure 11, TiDE has a lower average MAPE when compared to TimeGPT across the 195-time series for 15 out of 16 weeks. Although both models have access to the same information, the zero-shot inference from TimeGPT did not manage to beat our fine-tuned model.
The significance of forecasting cannot be overstated in today’s competitive landscape. Effective forecasting methods are key for organizations striving for operational excellence, enabling them to plan and manage their operations more efficiently.
In this article, we explored one of the most recent innovations in time series forecasting — the development of foundation models. These models aim to democratize access to sophisticated algorithms for organizations lacking the specialized expertise required to develop SOTA models in-house. While this initiative is promising, our analysis indicates that it still falls short of delivering accurate forecasts. Specifically, TiDE significantly outperformed TimeGPT in a zero-shot inference scenario.
Nevertheless, it is encouraging to witness the efforts of AI companies to push the boundaries of forecasting. While other domains, such as computer vision and NLP, have been gaining increased attention, the significance of forecasting for organizations should not be overlooked.
About me
Serial entrepreneur and leader in the AI space. I develop AI products for businesses and invest in AI-focused startups.Founder @ ZAAI | LinkedIn | X/Twitter
References
[1] Garza, A., & Mergenthaler-Canseco, M. (2023). TimeGPT-1. Retrieved from arXiv:2310.03589.
[2] Abhimanyu Das, Weihao Kong, Andrew Leach, Shaan Mathur, Rajat Sen, Rose Yu. (2023) Long-term Forecasting with TiDE: Time-series Dense Encoder. arXiv:2304.08424.
[3] Goswami, M., Szafer, K., Choudhry, A., Cai, Y., Li, S., & Dubrawski, A. (2024). MOMENT: A Family of Open Time-series Foundation Models. Retrieved from arXiv:2402.03885 (cs.LG).
[4] Das, A., Kong, W., Sen, R., & Zhou, Y. (2024). A decoder-only foundation model for time-series forecasting. Retrieved from arXiv:2310.10688 (cs.CL).
[5] Rasul, K., Ashok, A., Williams, A. R., Ghonia, H., Bhagwatkar, R., Khorasani, A., Darvishi Bayazi, M. J., Adamopoulos, G., Riachi, R., Hassen, N., Biloš, M., Garg, S., Schneider, A., Chapados, N., Drouin, A., Zantedeschi, V., Nevmyvaka, Y., & Rish, I. (2024). Lag-Llama: Towards Foundation Models for Probabilistic Time Series Forecasting. Retrieved from arXiv:2310.08278 (cs.LG).
[6] Woo, G., Liu, C., Kumar, A., Xiong, C., Savarese, S., & Sahoo, D. (2024). Unified Training of Universal Time Series Forecasting Transformers. Retrieved from arXiv:2402.02592 (cs.LG).
[7] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. Retrieved from arXiv:1706.03762.
[8] Stankeviciute, K., Alaa, A. M., & van der Schaar, M. (2021). Conformal time-series forecasting. In Advances in Neural Information Processing Systems (Vol. 34, pp. 6216–6228).
More articles: https://zaai.ai/lab/