

The Evolution of Llama: From Llama 1 to Llama 3.1
A Comprehensive Guide to the Advancements and Innovations in the Family of Llama Models from Meta AI
This article was co-authored by Luís Roque and Rafael GuedesIntroduction
Meta has released three major versions of its large language model (LLM), Llama, along with a minor (if we can call it that) update (version 3.1). The initial release of Llama in early 2023 marked a significant step forward for the open-source community in natural language processing (NLP). Meta has consistently contributed to this community by sharing its latest LLM versions.
To ensure correctness, we should distinguish between open and open-source LLMs. Open-source software traditionally makes its source code available under specific public use and modification licenses. In the context of LLMs, open LLMs typically disclose model weights and initial code. At the same time, open-source LLMs would also share the entire training process, including training data, with a permissive license. Most models today, including Meta’s Llama, fall under the open LLMs category since they do not release the datasets used for training.
Llama has undergone three key architectural iterations. Version 1 introduced several enhancements to the original Transformer architecture. Version 2 implemented Grouped-Query Attention (GQA) in larger models. Version 3 extended GQA to smaller models, introduced a more efficient tokenizer and expanded the vocabulary size. Version 3.1 did not change the core architecture. The bigger changes were the cleaning process of the training data, the longer context length, and the additional supported languages.
This article explores Llama’s architectural evolution, highlighting key advancements and their implications for the future of LLMs. It concludes with a practical experiment comparing Llama 2 and Llama 3, evaluating their performance on specific tasks using metrics like inference speed, answer length, and the Relative Answer Quality (RAQ) framework [1]. RAQ provides an objective ranking framework to test LLMs’ answers based on their accuracy relative to the ground truth, making it particularly useful for evaluating specific use cases.
As always, the code is available on our GitHub.
Llama: A Family of Open LLMs
Llama 1: The First Model
The first model of this family, Llama 1 [2], was built based on the encoder-decoder transformer architecture developed by Vaswani et al. in 2017 [3]. It was (and still is) one of the major breakthroughs in the area of NLP and the backbone architecture of all LLM models.
Llama 1 used it in its core architecture, combining it with several improvements, such as:
Pre-normalization
Inspired by the improvement of training stability implemented in the architecture of GPT3 [4], Llama 1 also normalizes the input of each transformer sub-layer rather than only the output, as shown in Figure 2.
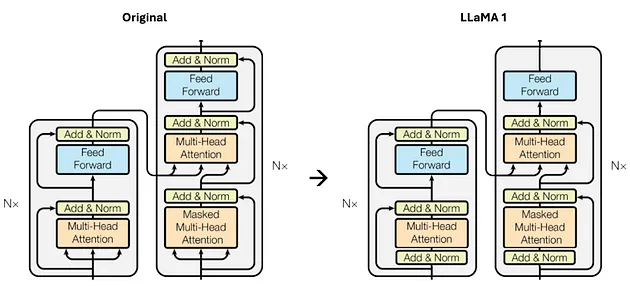
Additionally, they replace the traditional LayerNorm function with RMSNorm [5], which is more computationally efficient while preserving training stability and increasing model convergence.
RMSNorm achieves better efficiency because its authors demonstrated that the benefits of LayerNorm arise from rescaling invariance rather than recentering invariance. This insight allowed them to remove the mean calculation from the normalization process, making it simpler, just as effective, and significantly more efficient.

Additionally, they replace the traditional LayerNorm function with RMSNorm [5], which is more computationally efficient while preserving training stability and increasing model convergence.
SwiGLU activation function
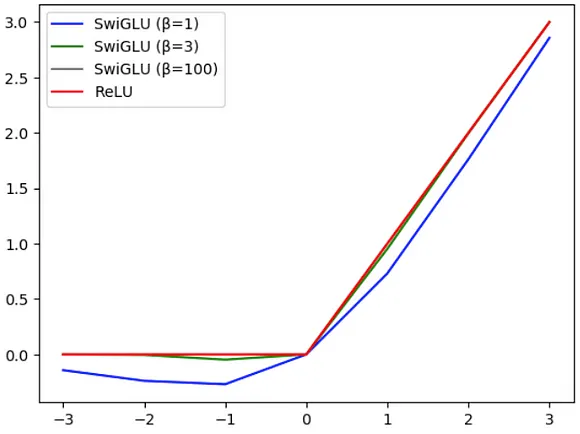
Regarding the activation function, the authors decided to replace the well-known ReLU with the SwiGLU [6] function, which has been shown to improve model performance. The main difference between both functions is that:
- ReLU transforms all negative values to 0 and returns the same value if it is positive.
- SwiGLU has a trainable parameter β that controls the degree of interpolation. As the β increases, the behavior becomes more similar to ReLU, as shown in Figure 4.
Rotary Positional Embeddings
Positional Embeddings are crucial for LLMs because the Transformer architecture is order invariant. This means it would represent two sentences in the same way, even if they use the same words in a different order and with different meanings. For example, the following sentences would have the same meaning for a Transformer if positional embeddings were not applied:
Sentence 1: Llama 2 is better than Llama 1 Sentence 2: Llama 1 is better than Llama 2
The original paper [3] implemented Absolute Positional Embeddings represented through two sinusoidal functions (sine and cosine). Each position in the sequence has a unique positional embedding that is summed up in the word embedding, ensuring that two sentences with the same words do not mean the same thing.
Let’s consider that the words in a sentence are encoded with a 1d-vector rather than a multiple-dimensional vector for explainability purposes. As shown in Figure 5, the words “1” and “2” are represented with the same value in the word embedding for both sentences. Still, after adding the positional encoding, they are represented with different values (0.88 → 1.04 and 0.26 → 0.1), respectively.

Although it already solved the problem of Transformers being order invariant, it still creates positional embeddings independent of each other. The consequence is that the proximity of two positions is not modeled. This means that from the model point of view, there are no differences in the correlation between positions 1 and 2 and positions 1 and 500. We know this is not the case because the similarity between the word in positions 1 and 2, in theory, must be higher than the similarity between the word in positions 1 and 500.
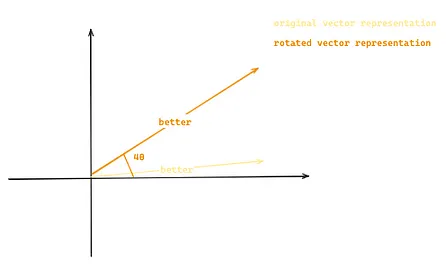
Rotary positional embeddings [7] (RoPE) can tackle this problem and model the relative position of the words by representing each position in the sequence through a rotation of the word embedding. Let’s use the same example as before: ‘Llama 2 is better than Llama 1’, and let’s consider that the word embedding now has 2 dimensions. The word better will be represented by a 2D rotated vector of the original 2D vector based on its position m (4) and a constant θ, as shown in Figure 6.
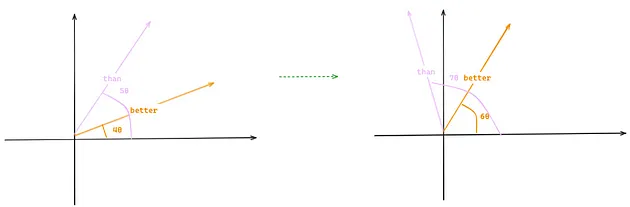
This approach allows us to preserve the relative distance between words because even if we add more words to the original sentence, the similarity between both vectors remains the same. Imagine this example where we add two words to the sentence, ‘The LLM Llama 2 is better than Llama 1’, the position better and than have different positions (4 & 5 → 6 & 7), but since the amount of rotation is the same, the similarity between both vectors also remains the same (the dot product between vectors on the left image is the same as in the right image).
Llama 2: The Evolved Form of Llama 1
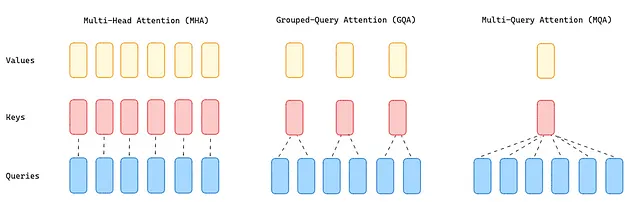
Llama 2 [8] kept all the architecture changes made to the original Transformer architecture on Llama 1. Additionally, it increased the context length from 2048 to 4096 and replaced Multi-Head Attention (MHA) [9] with Grouped-Query Attention (GQA) [10] for the larger models (34B and 70B).
Multi-Query Attention [9] (MQA) significantly decreases the memory needed by just using a single key and value but multiple query heads in the attention layer. However, this solution can lead to quality degradation and training instability, making other open LLMs, such as T5, not choose this approach.
GQA is placed between MHA and MQA by dividing query values into G groups (GQA-G) that share a single key and value head. A GQA-1 means that all queries are aggregated in one group and, therefore, the same as MQA, while a GQA-H (H = number of Heads) is the equivalent of MHA, where each query is treated as a group. This approach reduces the number of keys and values heads into a single key and value per query group. It reduces the size of the key value cached and, hence, the amount of data needed to be loaded. This more moderate reduction than MQA accelerates the inference speed and reduces the memory requirements during decoding with a quality closer to MHA and nearly the same speed as MQA.
Llama 3: Size and Tokenization
Llama 3 [11] increased the context length from 4096 to 8192 and extended the GQA to the smaller model (8B). Besides that, the authors replaced the tokenizer Sentence Piece [12] with the TikToken [13] used in OpenAI models. It significantly improved model performance since it has a vocabulary size of 128k tokens instead of 32k.
The main difference between both tokenizers is that TikToken ignores byte pair encoding (BPE) [14] merging rules when an input token is part of the vocabulary. Imagine that generating is part of the vocabulary. It will be returned as a token instead of two tokens coming from the split of the word into the smallest units, generating and ing .
Llama 3: Size and Tokenization
Released in July 2024, Llama 3.1 introduces a significant leap in context length (128K tokens) and support for eight additional languages. One of the key pieces of the release was the larger model Llama 3.1 405B. Until then, open LLMs were generally released in sizes below 100B.
Lastly, a summary of the evolution can be seen in the table below:

Llama 2 vs Llama 3: Model Comparison
In this section, we will apply Llama2 and Llama 3 to a question-answering dataset under the License CC BY-SA 4.0 called SQuAD (it can be found here). This reading comprehension dataset consists of questions about a set of Wikipedia articles. Based on context, the model should be able to retrieve the correct answer to a question. The three more important fields for our use case are:
- question - the question a model should answer.
- context - background information from which the model needs to extract the answer.
- answers - the text answer to the question.
The evaluation process will consist of three quantitative metrics: one to assess the inference speed, the second to determine the answer length, and the third to evaluate accuracy. For the latter, we use RAQ [1]. RAQ ranks the answers of Llama 2 and Llama 3 using an independent LLM based on how close they are to the ground truth answer.
We start by downloading both models in a .gguf format to be able to run them in CPU, and we place them under the folder model/.
We used the instruct version of each model with a 4-bit quantization:
- nous-hermes-Llama-2-7b.Q4_K_M.gguf from https://huggingface.co/TheBloke/Nous-Hermes-Llama-2-7B-GGUF
- Meta-Llama-3-8B-Instruct-Q4_K_M.gguf from https://huggingface.co/NousResearch/Meta-Llama-3-8B-Instruct-GGUF
After that, we import all the libraries and our own generator that receives the model we want to use as an argument.
import os
import seaborn as sns
import matplotlib.pyplot as plt
import scikit_posthocs as sp
import pandas as pd
import utils
from dotenv import load_dotenv
from generator.generator import Generator
from datasets import load_dataset
Llama2 = Generator(model='Llama2')
Llama3 = Generator(model='Llama3')
load_dotenv('env/var.env')
This class is responsible for importing the model parameters defined in a config.yaml file with the following characteristics: context_length of 1024, temperature of 0.7, and max_tokens of 2000.
generator:
Llama2:
llm_path: "model/Llama-2-7b-32k-instruct.Q4_K_M.gguf"
Llama3:
llm_path: "model/Meta-Llama-3-8B-Instruct-Q4_K_M.gguf"
context_length: 1024
temperature: 0.7
max_tokens: 2000
Besides that, it also creates the Prompt Template, which uses LangChain. It formats the query and the context based on the template before passing it to the LLM to get a response.
from langchain import PromptTemplate
from langchain.chains import LLMChain
from langchain.llms import LlamaCpp
from base.config import Config
class Generator(Config):
"""Generator, aka LLM, to provide an answer based on some question and context"""
def __init__(self, model) -> None:
super().__init__()
# template
self.template = """
Use the following pieces of context to answer the question at the end.
{context}
Question: {question}
Answer:
"""
# load llm from local file
self.llm = LlamaCpp(
model_path=f"{self.parent_path}/{self.config['generator'][model]['llm_path']}",
n_ctx=self.config["generator"]["context_length"],
temperature=self.config["generator"]["temperature"],
)
# create prompt template
self.prompt = PromptTemplate(
template=self.template, input_variables=["context", "question"]
)
def get_answer(self, context: str, question: str) -> str:
"""
Get the answer from llm based on context and user's question
Args:
context: most similar document retrieved
question: user's question
Returns:
llm answer
"""
query_llm = LLMChain(
llm=self.llm,
prompt=self.prompt,
llm_kwargs={"max_tokens": self.config["generator"]["max_tokens"]},
)
return query_llm.run({"context": context, "question": question})
With the LLMs loaded, we fetch the SQuAD dataset from HuggingFace and shuffle it to ensure enough variety regarding the question theme.
squad = load_dataset("squad", split="train")
squad = squad.shuffle()
Now, we can loop over 30 questions and contexts and record the above metrics.
for i in range(30):
context = squad[i]['context']
query = squad[i]['question']
answer = squad[i]['answers']['text'][0]
# Llama 2
answer_Llama2, words_per_second, words = utils.get_llm_response(Llama2, context, query)
Llama2_metrics["words_per_second"].append(words_per_second)
Llama2_metrics["words"].append(words)
# Llama 3
answer_Llama3, words_per_second, words = utils.get_llm_response(Llama3, context, query)
Llama3_metrics["words_per_second"].append(words_per_second)
Llama3_metrics["words"].append(words)
# RAQ
llm_answers_dict = {'Llama2': answer_Llama2, 'Llama3': answer_Llama3}
rank = utils.get_gpt_rank(answer, llm_answers_dict, os.getenv("OPENAI_API_KEY"))
Llama2_metrics["rank"].append(rank.index('1')+1)
Llama3_metrics["rank"].append(rank.index('2')+1)
The function get_llm_response receives the loaded LLM, the context, and the question and returns the LLM answer and quantitative metrics.
def get_llm_response(model: Generator, context: str, query: str) -> Tuple[str, int, int]:
"""
Generates an answer from a given LLM based on context and query
returns the answer and the number of words per second and the total number of words
Args:
model: LLM
context: context data
query: question
Returns:
answer, words_per_second, words
"""
init_time = time.time()
answer_llm = model.get_answer(context, query)
total_time = time.time()-init_time
words_per_second = len(re.sub("[^a-zA-Z']+", ' ', answer_llm).split())/total_time
words = len(re.sub("[^a-zA-Z']+", ' ', answer_llm).split())
return answer_llm, words_per_second, words
After completing the evaluation, we plotted the metrics and observed that Llama 3 is faster than Llama 2, generating approximately 1.1 words per second on average, compared to Llama 2’s 0.25 words per second. Regarding answer length, Llama 3 produces longer answers, with an average of 70 words, while Llama 2 7B generates responses averaging 15 words. Finally, according to the Relative Answer Quality (RAQ) framework, Llama 3 achieved the best average rank, approximately 1.25, while Llama 2 performed worse, with an average rank of around 1.8.

Table 2 presents the results of the Dunn post-hoc test, which compares the performance of different language models. Each cell indicates whether the difference in performance between the respective models is statistically significant at a 5% significance level. “Significant” denotes a statistically significant difference (p-value ≤ 0.05), while “Not Significant” indicates no statistically significant difference (p-value > 0.05). According to the Dunn test results, Llama 3’s performance is significantly different from that of Llama 2.
p_values = sp.posthoc_dunn([Llama2_metrics['rank'], Llama3_metrics['rank']], p_adjust='holm') p_values > 0.05

Finally, in qualitative terms, we analyze the answers of both models to one of the questions. They both managed to correctly answer the question, ‘What percentage of improvement over energy code requirements will be the goal of all new construction and renovations?’ based on the following context:
Context: ‘Northwestern requires that all new buildings be LEED-certified. Silverman Hall on the Evanston campus was awarded Gold LEED Certification in 2010; Wieboldt Hall on the Chicago campus was awarded Gold LEED Certification in 2007, and the Ford Motor Company Engineering Design Center on the Evanston campus was awarded Silver LEED Certification in 2006. New construction and renovation projects will be designed to provide at least a 20% improvement over energy code requirements where technically feasible. The university also released at the beginning of the 2008–09 academic year the Evanston Campus Framework Plan, which outlines plans for future development of the Evanston Campus. The plan not only emphasizes the sustainable construction of buildings, but also discusses improving transportation by optimizing pedestrian and bicycle access. Northwestern has had a comprehensive recycling program in place since 1990. Annually more than 1,500 tons are recycled at Northwestern, which represents 30% of the waste produced on campus. Additionally, all landscape waste at the university is composted.
Nevertheless, as shown below, Llama 2 contradicts itself by starting to say that the answer is not in the context and ending with a passage from the context with the answer. Conversely, Llama 3 identifies the answer in the context and provides a concise and correct answer.
Llama 2 answer: ‘It is not mentioned in the given passage what percentage improvement over energy code requirements will be the goal of all new construction and renovations. However, it is mentioned that “New construction and renovation projects will be designed to provide at least a 20% improvement over energy code requirements where technically feasible.’
Llama 3 answer: ‘According to the provided context, all new construction and renovation projects will aim to provide at least a 20% improvement over energy code requirements where technically feasible.’
Conclusions
The evolution of the Llama models shows a steady trajectory of innovation aimed at improving efficiency, performance, and versatility in LLMs. Starting with Llama 1, which introduced foundational changes like input normalization with RMSNorm and smoother activation functions, each subsequent version has built upon these advancements.
Llama 2 refined this approach by optimizing inference efficiency with GQA, setting the stage for even greater improvements in Llama 3. Llama 3 expanded on these capabilities by extending GQA to smaller models, adopting a more efficient tokenizer with a much larger vocabulary, doubling context lengths, and significantly increasing training data.
The recent release of Llama 3.1 marks a new milestone. It further extends context lengths to 128K tokens, adds support for more languages, and introduces the largest open model so far — the 405B model.
These enhancements across the Llama versions have led to models with superior adaptability across diverse applications. So far, the Llama models have been downloaded over 300 million times, and the integration of Llama models into thousands of products that leverage private LLM capabilities is only starting. Ironically, Llama now leads the way in advancing open AI, taking up the position once held by OpenAI when it was, in fact, more open.
About me
Serial entrepreneur and leader in the AI space. I develop AI products for businesses and invest in AI-focused startups. Founder @ ZAAI | LinkedIn | X/Twitter
References
[1] Luís Roque, Rafael Guedes. “Research to Production: Relative Answer Quality (RAQ) and NVIDIA NIM.” Towards Data Science. Medium, 2024.
[2] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. “Llama: Open and Efficient Foundation Language Models.” arXiv preprint arXiv:2302.13971, 2023.
[3] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. “Attention Is All You Need.” arXiv preprint arXiv:1706.03762, 2017.
[4] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, Dario Amodei. “Language Models are Few-Shot Learners.” arXiv preprint arXiv:2005.14165, 2020.
[5] Biao Zhang, Rico Sennrich. “Root Mean Square Layer Normalization.” arXiv preprint arXiv:1910.07467, 2019.
[6] Noam Shazeer. “GLU Variants Improve Transformer.” arXiv preprint arXiv:2002.05202, 2020.
[7] Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, Yunfeng Liu. “RoFormer: Enhanced Transformer with Rotary Position Embedding.” arXiv preprint arXiv:2104.09864, 2021.
[8] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom. “Llama 2: Open Foundation and Fine-Tuned Chat Models.” arXiv preprint arXiv:2307.09288, 2023.
[9] Noam Shazeer. “Fast Transformer Decoding: One Write-Head is All You Need.” arXiv preprint arXiv:1911.02150, 2019.
[10] Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, Sumit Sanghai. “GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints.” arXiv preprint arXiv:2305.13245, 2023.
[11] Meta AI. “Introducing Llama 3.” Meta AI Blog, 2024.
[12] Taku Kudo, John Richardson. “SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing.” arXiv preprint arXiv:1808.06226, 2018.
[13] OpenAI. “TikToken.” GitHub
[14] Rico Sennrich, Barry Haddow, Alexandra Birch. “Neural Machine Translation of Rare Words with Subword Units.” arXiv preprint arXiv:1508.07909, 2015.
All images are by the authors unless noted otherwise.