

A deep exploration of TFT, its implementation using Darts and how to interpret a Transformer
This article was authored by Rafael Guedes
Introduction
Every company in the world needs forecasting to plan their operations regardless the sector in which they operate. There are several forecast use cases to solve in companies such as sales for yearly planning, customer service contacts for monthly planning of agents for each language, sku sales to plan production and/or procurement and so on.
Although, there are different use cases, all of them share one need from their stakeholders: Interpretability! If you deployed a forecast model in the past for a stakeholder, you came across to the question: ‘why is the model making such prediction?’
In this article I explore TFT, an interpretable Transformer for time series forecasting. I also provide a step-by-step implementation of TFT to forecast weekly sales in a dataset from Walmart using Darts (a forecasting library for Python). And finally, I show how to interpret the model and its performance for a 16 week horizon forecast in the Walmart dataset.
TFT: Temporal Fusion Transformers
What is it?
When it comes to time series forecasting, usually they are influenced not only by their historical values but also on other inputs. They might contain a mix of complex inputs like static covariates (i.e. time-invariant features like the brand of a product), dynamic covariates with known future inputs like the product discount and other dynamic covariates with unknown future inputs such as the number of visitors for the next weeks.
Several Deep Learning models have been proposed to tackle the presence of multiple inputs for time series forecasting but they are typically ‘black-box’ models which do not allow to understand how each component is impacting the forecast produced.
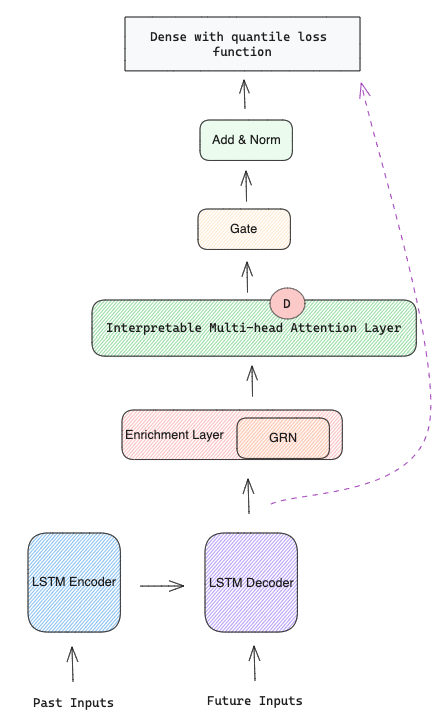
Temporal Fusion Transformers (TFT) [1] is an attention-based architecture that combines multi-horizon forecasting with interpretable insights. It has recurrent layers to learn temporal relationships at different scales, self-attention layers for interpretability, variable selection networks to perform feature selection, gating layers to suppress unnecessary components and its loss function is quantile loss to produce forecast intervals. In Figure 2 you can see TFT architecture that will be explained in more detail in the next section.
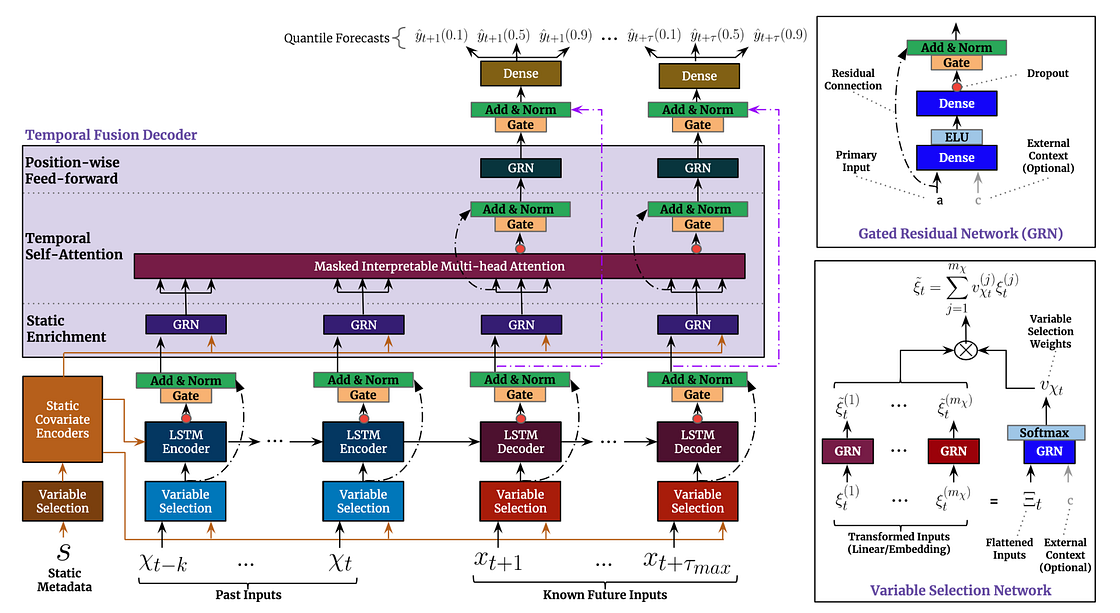
How does it work?
TFT has 5 major components:
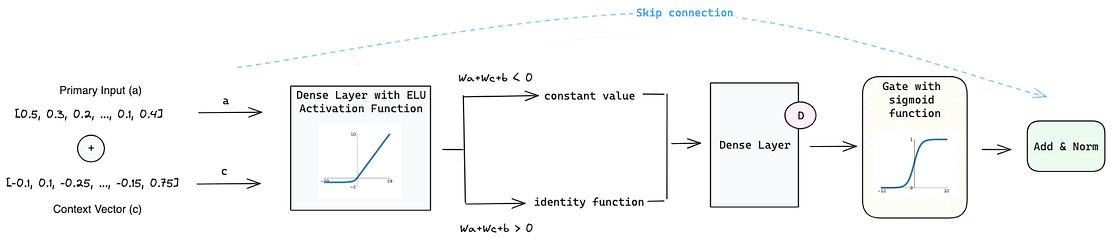
1. Gating Mechanisms powered by Gated Residual Network (GRN) that gives the flexibility to apply non-linear processing only when needed. This is important because it is hard to know in advance the non-linear relationship between dynamic covariates and the target. When we have small and noisy datasets, simpler models can be more beneficial and the non-linear processes can be skipped.
The GRN works the following way:
- It starts with a Primary Input a and a Context Vector c (which is the result of the static encoder — will be explained later).
- Those inputs go through a Dense Layer with ELU [2] activation function that acts as identity function when W2,ω a + W3,ω c + b2,ω >> 0 and as a constant when W2,ω a + W3,ω c + b2,ω << 0.
- Then its output goes through a new Dense Layer which produces the input for the Gated Linear Units (GLUs) [3]. GLU has a sigmoid activation function that is responsible for controlling how much the GRN contributes to the original input a.
- Due to the sigmoid function GLU can produce an output of 0 which will make the model skip the non-linear contribution and the Layer Normalization will just receive the original a from the skip connection.
2. Variable Selection Networks (VSN) help the model to weight the relevance and contribution of each static and dynamic covariates. Apart from providing which features are most important for the forecasting, it also performs feature selection to remove any unnecessary noisy inputs that can negatively impact performance. Each type of input (static, past and future) has its own VSN represented by different colours in Figure 2.
The input features are transformed before getting into VSN. Categorical inputs are encoded into a d-dimensional embedding vector while numerical features are linearly transformed into a d-dimensional vector.
After that, VSN unfolds into two branches:
1st Branch:
- Each transformed feature E(j) at time t are concatenated into a vector of all past inputs at time t such as [E(1)t, E(2)t, …, E(j-1)t, E(j)t], where j denotes a specific feature.
- This vector is concatenated to a Context Vector c that goes through a GRN where a non-linear transformation is applied as explained previously.
- The output of GRN is passed to a Softmax layer that produces a vector with the weights for each feature. The feature selection is performed in this step since Softmax can produce any value from 0 to 1.
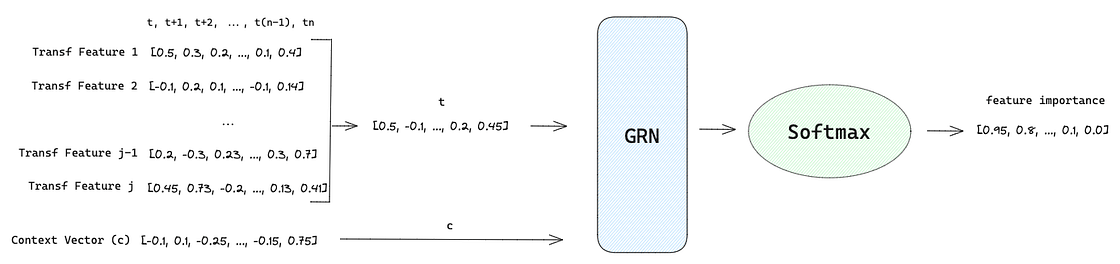
2nd Branch:
- Each transformed feature E at time t feeds an independent GRN producing the output ~E though a non-linear processing.

Combination Step:
- With the feature importance vector and the non-linear transformations of E, a element wise combination of both vectors is performed to generated a processed feature vector weight by their relevance.

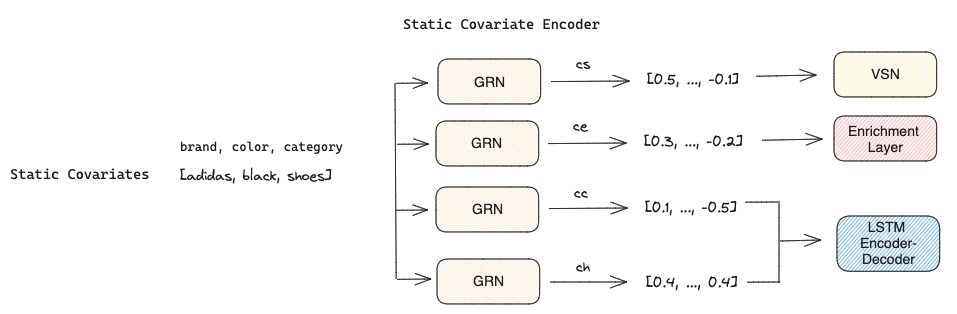
3. Static Covariate Encoders encode the static covariates into four different vectors using four different GRNs:
- Context vector s used for temporal variable selection in VSNs
- Context vector c and h used for local processing of temporal features in LSTM Encoder-Decoder
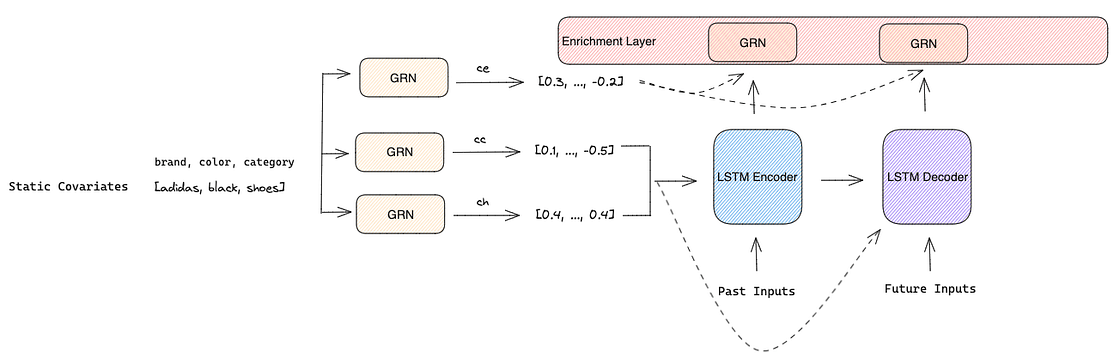
- Context vector e used to enrich temporal features with static information in the Enrichment Layer
4. Temporal Processing is important in time series because often the surrounding observations are the most useful for future predictions. This local context was already developed for attention-based architectures, however they are only suitable for observed inputs and cannot handle known future inputs at the same time.
To overcome this problem, the authors proposed a sequence-to-sequence model to handle past and future known inputs. They feed past inputs into a LSTM Encoder and known future inputs into a LSTM Decoder. Both Encoder and Decoder also use the context vectors c and h as inputs so that static metadata can influence local processing when creating the temporal features.
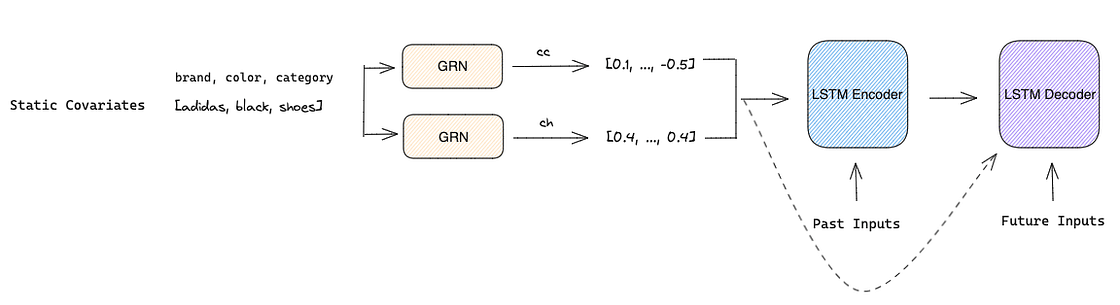
The output of both Encoder and Decoder is combined with the context vector e and sent to an individual GRN with shared weights in the Enrichment Layer that enhances temporal features with static metadata.
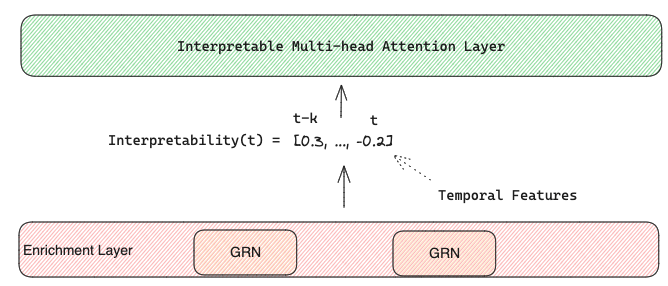
Finally, the final temporal features enriched with static metadata are fed to an interpretable multi-head attention layer that learns the relevance of each time step t in respect to the rest of the input sequence that precedes it.
5. Quantile Prediction is achieved by the prediction of various percentiles at each time step. The forecast is generated using a linear transformation of the output from the temporal fusion decoder.
How to use and interpret TFT in practice
This section covers a step by step implementation of TFT using the same dataset from my previous post about TiDE which is a weekly sales dataset from Walmart available on kaggle (License CC0: Public Domain).
I will use the implementation in Darts to train, predict and interpret TFT.
The dataset has 2 years and 8 months of weekly sales and 16 columns:
- Store — store number and one of the static covariates
- Dept — department number and another static covariate
- Type — type of store and another static covariate
- Size — size of the store and the last static covariate
- Date — the temporal index of the time series which is weekly and it will be used to extract dynamic covariates like the week number and the month
- Weekly_Sales — the target variable
- IsHoliday — a dynamic covariate that identifies if there is a holiday in a specific week
- Temperature — a dynamic covariate with the average temperature in a specific week
- Fuel_Price — a dynamic covariate with the price of fuel in a specific week
- MarkDown 1,2,3,4 and 5 —a dynamic covariate with average discounts in a specific week
- CPI — a dynamic covariate with the consumer price index
- Unemployment — a dynamic covariate with the unemployment rate
We start by importing the libraries and defining global variables like the date column, target column, static covariates, dynamic covariates to fill with 0, dynamic covariates to fill with linear interpolation, the frequency of our series, the forecast horizon and the scalers to use:
import pandas as pd
import numpy as np
from datetime import timedelta
import matplotlib.pyplot as plt
from darts import TimeSeries
from darts.dataprocessing.pipeline import Pipeline
from darts.models import TFTModel
from darts.dataprocessing.transformers import Scaler
from darts.utils.timeseries_generation import datetime_attribute_timeseries
from darts.utils.likelihood_models import QuantileRegression
from darts.dataprocessing.transformers import StaticCovariatesTransformer, MissingValuesFiller
TIME_COL = "Date"
TARGET = "Weekly_Sales"
STATIC_COV = ["Store", "Dept", "Type", "Size"]
DYNAMIC_COV_FILL_0 = ["IsHoliday", 'MarkDown1', 'MarkDown2', 'MarkDown3', 'MarkDown4', 'MarkDown5']
DYNAMIC_COV_FILL_INTERPOLATE = ['Temperature', 'Fuel_Price', 'CPI', 'Unemployment']
FREQ = "W-FRI"
FORECAST_HORIZON = 16 # weeks
SCALER = Scaler()
TRANSFORMER = StaticCovariatesTransformer()
PIPELINE = Pipeline([SCALER, TRANSFORMER])The default scaler is MinMax Scaler, but we can use any we want from scikit-learn as long as it has fit(), transform() and inverse_transform() methods. The same happens for the transformer which by default is Label Encoder from scikit-learn.
After that, we load our dataset and we enrich it with those exogenous features as I mentioned in the dataset description:
# load data and exogenous features
df = pd.read_csv('data/train.csv')
store_info = pd.read_csv('data/stores.csv')
exo_feat = pd.read_csv('data/features.csv').drop(columns='IsHoliday')
# join all data frames
df = pd.merge(df, store_info, on=['Store'], how='left')
df = pd.merge(df, exo_feat, on=['Store', TIME_COL], how='left')Once the dataset is loaded we need to apply some preprocessing to clean up the data:
- We set the time column as pd.datetime
- We convert negative values to 0 (those negative values might indicate returns but I did not spend a lot of time looking into it since it is out of the scope for this article)
- We fill missing values in Markdown columns with 0, since we assume that when the value is missing is due to lack of promotions
- We convert the boolean column that identifies a holiday in a specific week to a binary column
- We transform the Size static covariate from continuous to categorical. When the size is lower than the percentile 25 then is ‘small’, when is higher than the percentile 75 then is ‘large’ and, finally, when it is between the percentile 25 and 75 then is ‘medium’.
- Finally, we forecast only the 7 stores with the highest volume of sales to reduce run time (I ran it once with all stores and it took me 11 hours to train the TFT model 😅).
df[TIME_COL] = pd.to_datetime(df[TIME_COL])
df[TARGET] = np.where(df[TARGET] < 0, 0, df[TARGET]) # remove negative values
df[['MarkDown1', 'MarkDown2', 'MarkDown3', 'MarkDown4','MarkDown5']] = df[['MarkDown1', 'MarkDown2', 'MarkDown3', 'MarkDown4','MarkDown5']].fillna(0) # fill missing values with nan
df["IsHoliday"] = df["IsHoliday"]*1 # convert boolean into binary
df["Size"] = np.where(df["Size"] < store_info["Size"].quantile(0.25), "small",
np.where(df["Size"] > store_info["Size"].quantile(0.75), "large",
"medium")) # make size a categorical variable
# reduce running time by forecasting only top 7 stores
top_7_stores = df.groupby(['Store']).agg({TARGET: 'sum'}).reset_index().sort_values(by=TARGET, ascending=False).head(7)
df = df[df['Store'].isin(top_7_stores['Store'])]With the data cleaned, we can split the data between train and test (I decided to use the last 16 weeks of data for our test set). And transform the pandas data frame into Darts TimeSeries format.
- Using the function TimeSeries.from_group_dataframe we can easily define the static covariates, our target, the column with the time reference and the frequency of the series.
- I also used the fill_missing_dates argument to fill the target variable with 0 in case some of our series have a gap between weeks.
# 16 weeks to for test
train = df[df[TIME_COL] <= (max(df[TIME_COL])-timedelta(weeks=FORECAST_HORIZON))]
test = df[df[TIME_COL] > (max(df[TIME_COL])-timedelta(weeks=FORECAST_HORIZON))]
# read train and test datasets and transform train dataset
train_darts = TimeSeries.from_group_dataframe(
df=train,
group_cols=STATIC_COV,
time_col=TIME_COL,
value_cols=TARGET,
freq=FREQ,
fill_missing_dates=True,
fillna_value=0)We have the historical data in a TimeSeries format, so now it is time to create the dynamic covariates in the same format:
- As before, we used the fill_missing_dates argument with fillna_value=0 for those dynamic covariates that I believe lack of data can be replaced with 0.
- For those which should be replaced with interpolation like Temperature, Fuel Price, CPI and Unemployment, we don’t set the fillna_value argument and we use MissingValuesFiller() function to linear interpolate missing values.
# create dynamic covariates for each serie in the training darts
dynamic_covariates = []
for serie in train_darts:
# add the month and week as a covariate
covariate = datetime_attribute_timeseries(
serie,
attribute="month",
one_hot=True,
cyclic=False,
add_length=FORECAST_HORIZON,
)
covariate = covariate.stack(
datetime_attribute_timeseries(
serie,
attribute="week",
one_hot=True,
cyclic=False,
add_length=FORECAST_HORIZON,
)
)
store = serie.static_covariates['Store'].item()
dept = serie.static_covariates['Dept'].item()
# create covariates to fill with 0
covariate = covariate.stack(
TimeSeries.from_dataframe(df[(df['Store'] == store) & (df['Dept'] == dept)], time_col=TIME_COL, value_cols=DYNAMIC_COV_FILL_0, freq=FREQ, fill_missing_dates=True, fillna_value=0)
)
# create covariates to fill with interpolation
dyn_cov_interp = TimeSeries.from_dataframe(df[(df['Store'] == store) & (df['Dept'] == dept)], time_col=TIME_COL, value_cols=DYNAMIC_COV_FILL_INTERPOLATE, freq=FREQ, fill_missing_dates=True)
covariate = covariate.stack(MissingValuesFiller().transform(dyn_cov_interp))
dynamic_covariates.append(covariate)We are 2 steps away from fitting and predicting with TFT! We just need to scale the covariates, the historical data and to encode the static covariates.
# scale covariates
dynamic_covariates_transformed = SCALER.fit_transform(dynamic_covariates)
# scale data and transform static covariates
data_transformed = PIPELINE.fit_transform(train_darts)We are ready to train and predict with TFT:
TFT_params = {
"input_chunk_length": 52, # number of weeks to lookback
"output_chunk_length": FORECAST_HORIZON,
"hidden_size": 2,
"lstm_layers": 2,
"num_attention_heads": 1,
"dropout": 0.1,
"batch_size": 16,
"n_epochs": 3,
"likelihood": QuantileRegression(quantiles=[0.25, 0.5, 0.75]),
"random_state": 42,
"use_static_covariates": True,
"optimizer_kwargs": {"lr": 1e-3},
}
tft_model = TFTModel(**TFT_params)
tft_model.fit(data_transformed, future_covariates=dynamic_covariates_transformed, verbose=False)
pred = PIPELINE.inverse_transform(tft_model.predict(n=FORECAST_HORIZON, series=data_transformed, num_samples=50, future_covariates=dynamic_covariates_transformed))
TFT: InterpretabilityTFT is an interpretable Transformer and Darts provide that functionality with just few lines!
We start by defining our explainer that receives as input the model that we just trained and the historical data of the series we want to interpret together with its dynamic covariates. In our case, we will interpret the forecast for Store 2 — Dept 2.
from darts.explainability import TFTExplainer
explainer = TFTExplainer(
tft_model,
background_series=data_transformed[1],
background_future_covariates=dynamic_covariates_transformed[1],
)
explainability_result = explainer.explain()After that, we can interpret the model through its 2 variants:
Variable Network Selection
- Encoder Importance shows that seasonality features (week and month) have the highest importance for our model, followed by IsHoliday and Markdown5.
plt.rcParams["figure.figsize"] = (10,5)
plt.barh(data=explainer._encoder_importance.melt().sort_values(by='value').tail(10), y='variable', width='value')
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.title('Encoder Importance')
plt.show()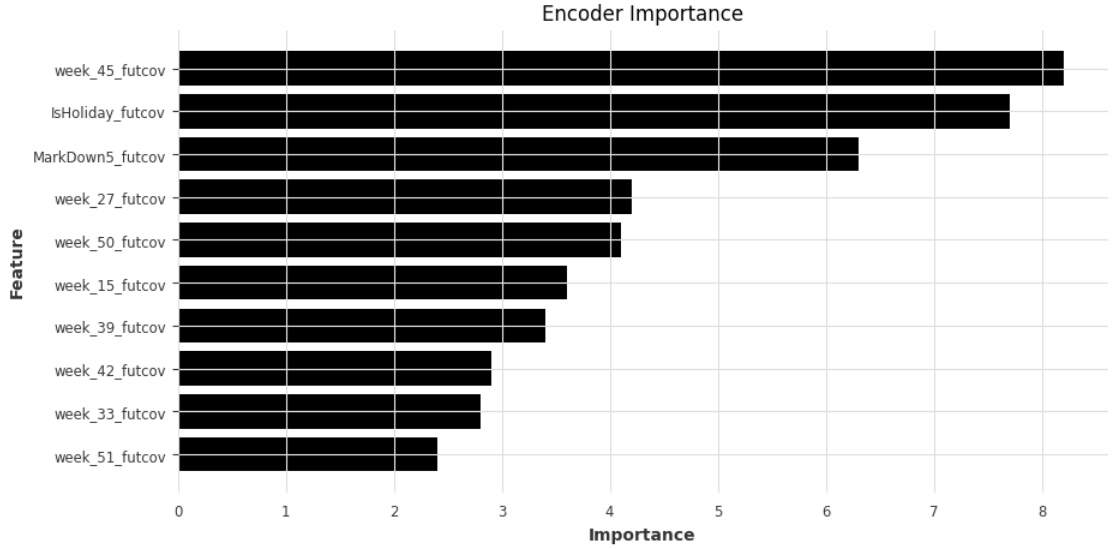
- Decoder Importance shows that seasonality features (week and month) have the highest importance for our model.
plt.rcParams["figure.figsize"] = (10,5)
plt.barh(data=explainer._decoder_importance.melt().sort_values(by='value').tail(10), y='variable', width='value')
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.title('Decoder Importance')
plt.show()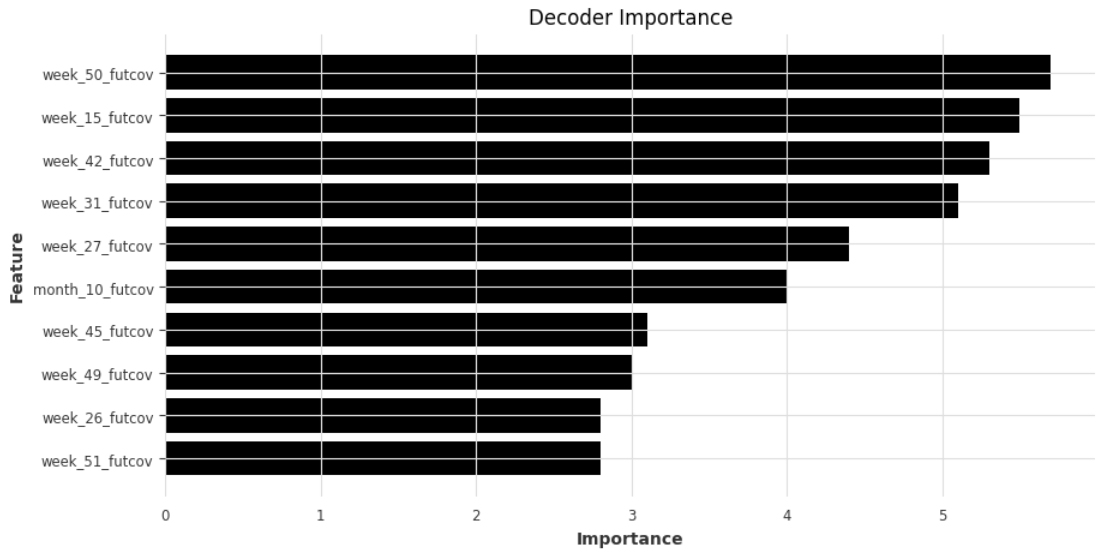
- Static Covariate Importance shows that the feature we created based on store Size is the most important static covariate.
plt.rcParams["figure.figsize"] = (10,5)
plt.barh(data=explainer._static_covariates_importance.melt().sort_values(by='value').tail(10), y='variable', width='value')
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.title('Static Cov Importance')
plt.show()
Temporal Multi-Head Attention Layer
This plot shows the importance of historical data for each time step in the forecast horizon and, as expected, closer we are from the cut off date, higher is the importance of past values.
explainer.plot_attention(explainability_result, plot_type="all", show_index_as='time')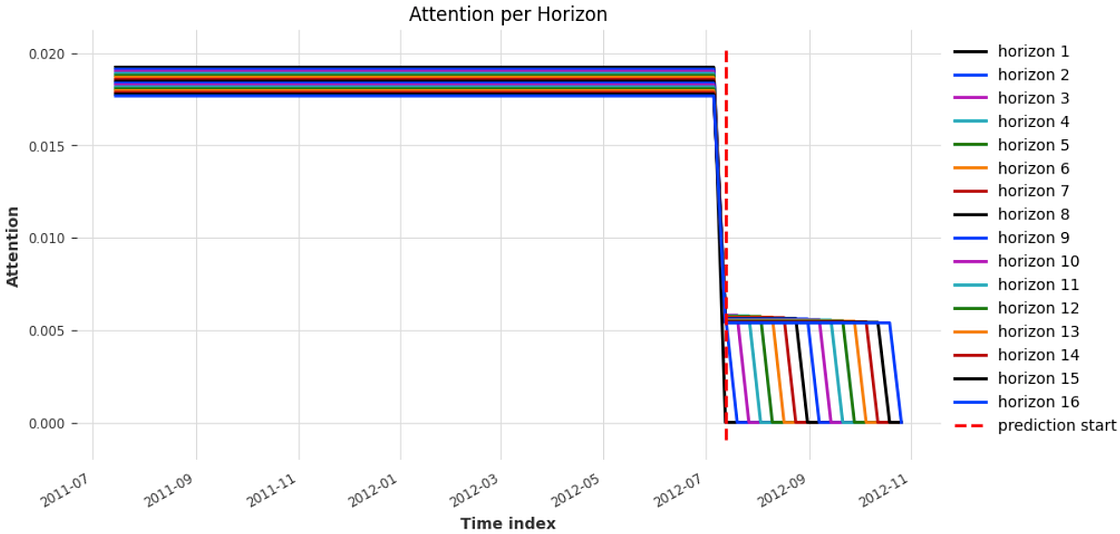
TFT: Performance
For Store 2 and Dept 2, our model had a performance of 3.58% MAPE and 3220.08 RMSE in the test set.
It managed to correctly predict most of the drops and spikes, and only 2 actual values are outside of the quantile ranges as you can see in Figure 16.
from darts.metrics import mape, rmse
def eval_model(val_series, pred_series):
# plot actual series
plt.figure(figsize=(9, 6))
val_series[: pred_series.end_time()].plot(label="actual")
# plot prediction with quantile ranges
pred_series.plot(
low_quantile=0.25, high_quantile=0.75, label=f"{int(0.25 * 100)}-{int(0.75 * 100)}th percentiles"
)
plt.title(f"MAPE: {round(mape(val_series, pred_series),2)}% | RMSE: {round(rmse(val_series, pred_series),2)}")
plt.legend()
eval_model(test_darts[1], pred[1])
Conclusion
The complexity of state-of-the-art models have been increasing over time which makes difficult to explain how they work for audiences that does not have a background in AI.
Regardless the type of model you deploy in your organisation, whether it is a simple classifier or a complex LLM, your stakeholders will always ask you at some point ‘why is the model making such prediction?’. Therefore, when it comes to research a model to solve a business problem, it is not just a matter of accuracy but also a matter of interpretability.
In this article, we explored a Transformer model for time series that is able to provide insights of what is impacting the predictions and how to interpret them.
References
[1] Bryan Lim, Sercan O. Arik, Nicolas Loeff, Tomas Pfister. Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting. arXiv:1912.09363, 2020.
[2] Djork-Arné Clevert, Thomas Unterthiner, Sepp Hochreiter. Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs).
arXiv:1511.07289, 2016.
[3] Yann N. Dauphin, Angela Fan, Michael Auli, David Grangier. Language Modeling with Gated Convolutional Networks. arXiv:1612.08083, 2017.
More articles: https://zaai.ai/lab/