

Meta’s open-source Seamless models: A deep dive into translation model architectures and a Python implementation guide using HuggingFace
This article was co-authored by Luís Roque and Rafael Guedes
Introduction
The growth of an organization is not limited to its country boundaries. Some organizations only sell or operate on external markets. This globalization comes with several challenges, one being how to handle different languages and make the changes from product labeling to promotional materials less expensive. The recent developments in AI come in handy because they allow a cheap and quick translation not only of text but also of audio material.
Organizations that incorporate AI in their day-to-day activities are always one step ahead of the competition, especially when getting all the components around your product ready for the new market. The timing is as important as the quality of your product or service; thereby, being able to be the first one to arrive is crucial, and technologies like speech-to-speech and text-to-text translation will help you reduce the time you need to enter a new market.
In this article, we explore Seamless, a family of three models developed by Meta to unlock cross-multilingual communication. We provide a detailed explanation of the architecture of each model and how they work. Finally, we finish with a practical implementation in Python using HuggingFace 🤗, and we expose and show how to overcome some of their limitations.
Seamless: a family of models to unlock cross-lingual communication
Seamless [1] is the first system that tries to remove language barriers and unlock expressive cross-lingual communication in real time. It is composed of multiple models from the Seamless Family, such as SeamlessM4T v2 [1], SeamlessExpressive [1], and SeamlessStreaming [1] that allow speech-to-speech and text-to-text translation over 101 input and 36 output languages. Each model will be explained in more detail in the following sections.
SeamlessM4T v2: the foundational model of the Seamless family
SeamlessM4T [2] is a Massively Multilingual and Multimodal Machine Translation model that supports speech-to-speech (S2ST), speech-to-text (S2TT), text-to-speech (T2ST), text-to-text translation (T2TT) and automatic speech recognition (ASR).
Its architecture is composed by:
1. w2v-BERT 2.0 [3] is a speech encoder model created by Google that learns how to represent speech through embeddings.
The architecture is the following:
- Speech Encoder comprises two 2D-convolution layers that extract a latent speech representation from a given raw acoustic input. The latent representation is then randomly masked and passed into a linear projection layer to produce a context vector used by the Contrastive Module (CM) and the Masked Prediction Module (MPM). At the same time, it goes through a quantization process that generates quantized vectors and their token IDs, which will be the target of the CM and MPM, respectively.
- Contrastive Module learns how to identify the quantized vector of a given context vector from a set of K distractors, i.e., a set of quantized vectors where only one is the true quantized vector of the given context vector. By minimizing this contrastive loss, the speech encoder can improve the quality of the embeddings produced.
- Masked Prediction Module is another learnable part of the model. Based on the context vector, it learns how to predict the masked token IDs, hence contributing to the quality of the speech embeddings produced.
w2v-BERT is trained to solve two self-supervised tasks at the same time. The final training loss to be minimized is defined by the sum of the contrastive loss and masked prediction loss.

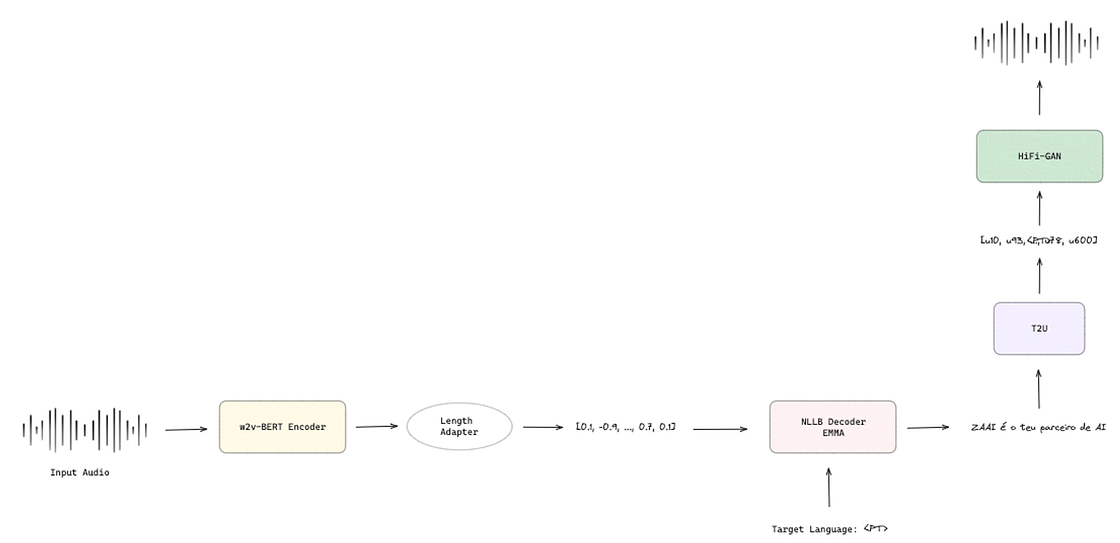
The Feature Encoder from w2v-BERT is used afterward in SeamlessM4T to create speech embeddings fed to a decoder to produce the translation. However, a gap exists between what a pre-trained text decoder expects to receive as input and what a pre-trained speech encoder can produce. To bridge the modality gap between speech and text to improve the translation, the authors use a Length Adapter [4], a Transformer based-module, to adapt speech representations to text that shrinks the speech sequence and produces features for speech-to-text translation via modeling global and local dependencies of a speech sequence. Its architecture comprises a speech encoder followed by the Length Adapter and a text decoder where the goal is to minimize the difference between the text generated and the actual text.
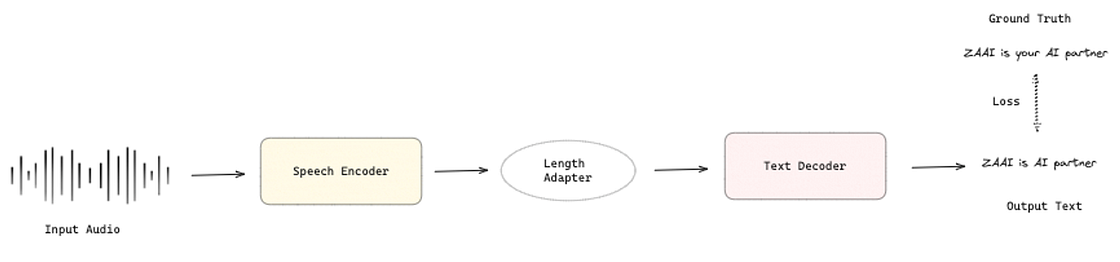
2. NLLB Encoder [5] is the encoder of a sequence-to-sequence multilingual machine translation model based on an encoder-decoder Transformer architecture that, given a sequence of text and the source language, produces a sequence of embeddings.

3. NLLB Decoder [5] is the decoder of the same model that, given the embeddings produced by the NLLB Encoder and the target language, produces the translated text. For the specific case of SeamlessM4T, the NLLB Decoder can also receive the speech embeddings produced by w2v-BERT, as shown in Figure 5.

4. Text-to-Unit (T2U) [6] is a multilingual encoder-decoder Transformer model trained to convert text into discrete acoustic units that a unit vocoder model can consume to produce the final speech in the target language.
The difference between SeamlessM4T v1 and v2 relies on this model. The authors tried to solve the problem of hallucination and output truncation when there was a length mismatch between discrete acoustic units and text tokens. For that, they implemented a non-autoregressive T2U decoder to perform a character-to-unit alignment and a decouple generation based on output length, which not only solved the problem but also improved inference time by 3x, enabling real-time translations.
The T2U encoder receives the output of the NLLB text decoder and encodes it into a subword-length embedding. The problem is that this embedding representation does not contain all the necessary acoustic details to decode into discrete acoustic units. Thereby, the authors upsampled the representation to character length and then to unit length. After the subword-to-character upsampling, an encoder model receives as input the character-length sequence and predicts the duration of each acoustic unit to be used by the T2U decoder together with unit-length embedding to produce the final discrete acoustic units.

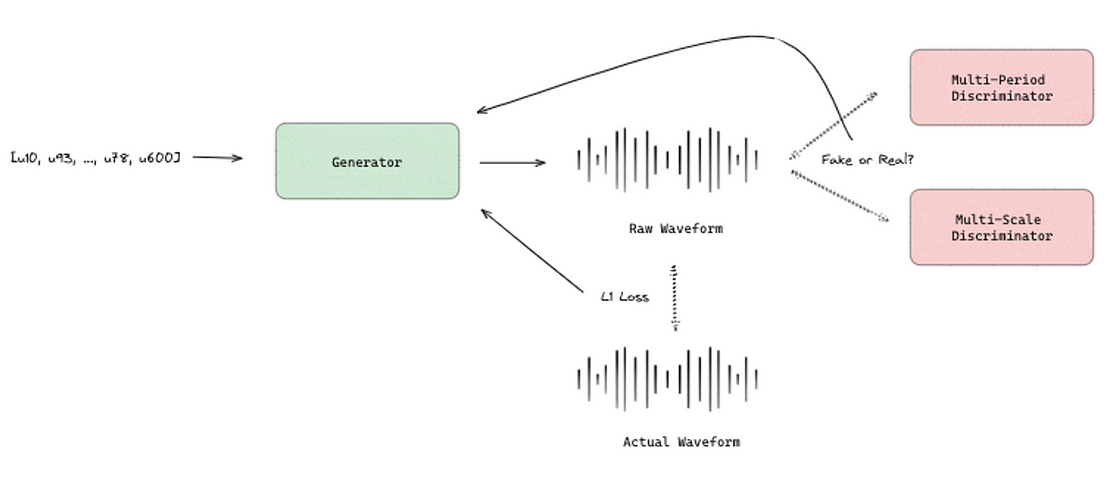
5. HiFi-GAN [7], as the name indicates, is a Generative Adversarial Network with a generator and a discriminator with two modules.
The generator is a Convolutional Neural Network that takes in discrete units of sound information as its input. Once it receives these sound units, it employs a set of operations called transposed convolutions. These methods allows it to increase the size of the input data, a process known as upsampling. The purpose of this upsampling is to ensure that the final output produced by the generator matches the detailed time-based structure of raw audio signals, often referred to as temporal resolution. This ensures that the generated audio closely mimics the complexity and nuances of natural sound waves.
HiFi-GAN has two loss functions: one is to fake the discriminator by updating the sample quality to be classified as real, and the other one is the distance between the Mel-spectrogram waveform generated and the ground truth waveform.
The multi-period discriminator is used to evaluate the periodic signals, and the multi-scale discriminator is used to evaluate the consecutive patterns and long-term dependencies of the audio produced by the generator.
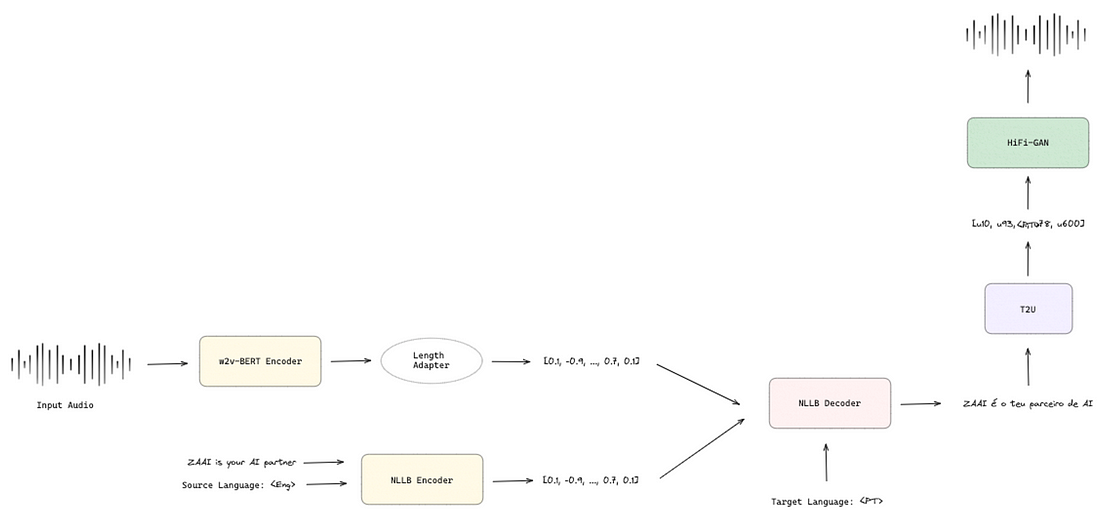
These 5 components are joined together, as shown in Figure 8. The model can receive audio or text converted into speech embeddings using w2v-BERT or the NLLB encoder. The NLLB decoder receives these speech or text embeddings. It translates the original input into text in the target language, achieving speech-to-text and text-to-text translation as promised. Regarding speech-to-speech and text-to-speech translation, the translated text is sent to T2U, encodes the text, predicts and aligns the duration of each unit, and decodes the acoustic units that are the input of HiFi-GAN to generate the final audio.
SeamlessExpressive
SeamlessExpressive was created to model prosody due to its importance in human communication. How people speak can change the meaning of the same sentence; for example, the loudness and duration of a speech are used by humans to express themselves in different situations.
The foundation model for SeamlessExpressive is SeamlessM4T v2 to achieve high-quality translation. However, it has two modifications to the original model. The T2U model has an additional expressivity encoder to guide acoustic unit generation with rhythm, speaking rate, and pauses. The HiFi-GAN vocoder receives the output from T2U after passing them through PRETSSEL. PRETSSEL is an expressive unit-to-speech generator conditioned by the source speech to transfer tones, emotional expression, and vocal style to the waveform generation. The SeamlessExpressive is only available in 6 languages (English, French, Spanish, German, Mandarin and Italian).
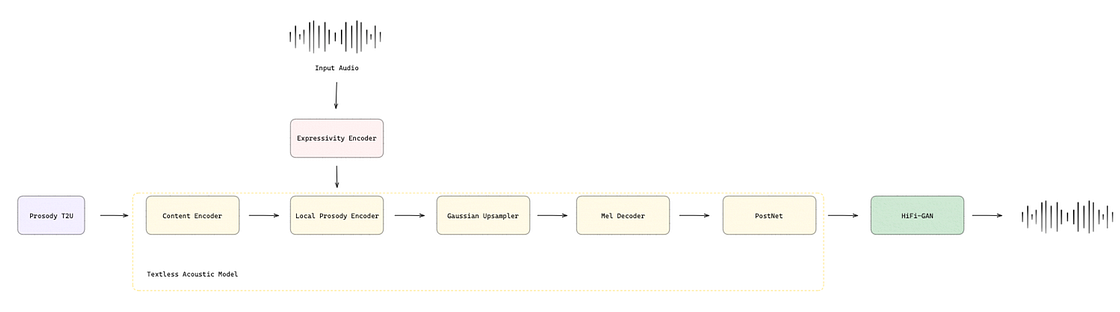
The expressivity encoder in Prosody T2U receives the original speech in the source language as input and encodes it into a 512-dimensional embedding vector containing high-level paralinguistic representations. This expressivity embedding vector is concatenated to the subword-length embedding before the subword-to-character upsampler, as shown in Figure 9.
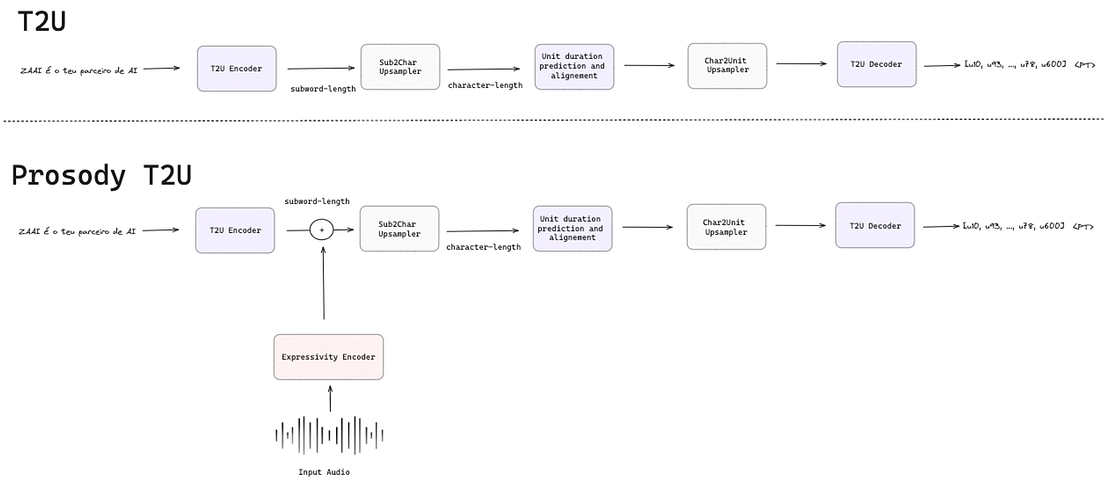
PRETSSEL produces the discrete acoustic units to be fed into HiFi-GAN based on the output of Prosody T2U and the expressivity embedding vector. These two inputs are processed by a textless acoustic model that is a non-autoregressive Transformer model with four components. Content Encoder extracts high-level context representations from the Prosody T2U output. A Local Prosody Encoder uses the expressivity embedding vector to predict local prosody features and energy contours and adds them to the context encoder output.
After that, a Gaussian Up-sampler is adopted to upsample the unit level to the frame level using unit duration. Finally, a Mel-decoder generates the Mel filterbank features from the upsampled sequences. The Mel filterbank is a signal processing concept, particularly used in speech and audio processing. It consists of filters that simulate the human ear’s sound response based on the Mel scale — a perceptual pitch scale reflecting how listeners perceive pitch differences. This approach better matches human hearing than linear frequency bands, making it highly effective for sound feature extraction. A PostNet then processes these generated features to predict a more natural Mel filterbank by compensating the residual signal that the decoder could not capture.
SeamlessStreaming
SeamlessStreaming builds on top of the SeamlessM4T v2 by adding real-time speech-to-speech and speech-to-text translation capabilities. It retains the core architecture of SeamlessM4T v2 but introduces a significant update to the Text Decoder component: the Efficient Monotonic Multihead Attention (EMMA). EMMA combines the advanced processing power of Transformer models with a focus on maintaining the sequential integrity of translations.
The authors adopted EMMA as their simultaneous policy responsible for deciding whether to predict the next token or pause the prediction to consume more context. In other words, it is a stepwise probability function that, given a partial input and a partial output, predicts the probability of generating the next work prediction or pausing to receive more context.
Seamless S2ST: translate your video adverts automatically
In this section, we will implement SeamlessM4T v2 for Speech-to-Speech translation. We recorded a video about ZAAI (our AI consultancy company) in English, and we want to translate it into Portuguese.
We start by importing the libraries and setting up the DEVICE to cuda if GPU is available:
from IPython.display import Audio
from moviepy.video.io.ffmpeg_tools import ffmpeg_extract_subclip
import utils
from transformers import AutoProcessor, pipeline, SeamlessM4Tv2Model
import torchaudio
import torch
import numpy as np
import scipy
DEVICE = "cuda:0" if torch.cuda.is_available() else "cpu"After that, we load the SeamlessM4T v2 model and its data processor from HuggingFace 🤗 (HF) "facebook/seamless-m4t-v2-large":
processor = AutoProcessor.from_pretrained("facebook/seamless-m4t-v2-large")
model = SeamlessM4Tv2Model.from_pretrained("facebook/seamless-m4t-v2-large").to(DEVICE)Ideally, we would load the audio of the video, convert the sample rate to 16 kHz to match the sample rate of the training data, and, with 2 lines of code, perform S2ST.
The problem is that the model is not prepared to receive long input audio, and, as you can see in our example, it converted a 30s audio into an 11s translated audio where the time reduction is not due to lack of speech.
# convert video to wav
utils.convert_to_wav("data/ZAAI_intro.mp4")
# load audio
audio, orig_freq = torchaudio.load("data/ZAAI_intro.wav")
# convert into 16 kHz waveform array to match the training data
audio = torchaudio.functional.resample(audio, orig_freq=orig_freq, new_freq=16_000)
# encode the speech into a speech embedding
audio_inputs = processor(audios=audio, sampling_rate=16000, return_tensors="pt").to(DEVICE)
# translate the audio from english to portuguese and generate a new waveform array
audio_array_from_audio = model.generate(**audio_inputs, tgt_lang="por", speaker_id=2)[0].cpu().numpy().squeeze()To overcome this problem, we decided to create chunks of 10 seconds, apply the S2ST, and, in the end, concatenate all the NumPy arrays. Although the result is much better, it is not perfect, as you can see below. The problem is that we are creating chunks that do not consider if the audio is in the middle of a sentence, likely degrading the final result. Ideally, we would create chunks based on speech pauses.
final_array = []
for i in range(0, 30, 10):
# cut the video in chunks of 5 seconds and convert the audio into wav format
# the division of the video in chunks is due to a model limitation that cannot handle long audio inputs
ffmpeg_extract_subclip("data/ZAAI_intro.mp4", 0 + i, 10 + i, targetname="data/chunk.mp4")
utils.convert_to_wav("data/chunk.mp4")
# load audio
audio, orig_freq = torchaudio.load("data/chunk.wav")
# convert into 16 kHz waveform array to match the training data
audio = torchaudio.functional.resample(audio, orig_freq=orig_freq, new_freq=16_000)
# encode the speech into a speech embedding
audio_inputs = processor(
audios=audio,
sampling_rate=16000,
return_tensors="pt",
).to(DEVICE)
# translate the audio from english to portuguese and generate a new waveform array
audio_array_from_audio = (
model.generate(**audio_inputs, tgt_lang="por", speaker_id=2)[0]
.cpu()
.numpy()
.squeeze()
)
# append the different chunks
final_array.append(audio_array_from_audio)
torch.cuda.empty_cache()Seamless4MT v2 and Whisper for S2ST
Seamless4MT v2 for S2ST is not perfect yet. Therefore, we decided to improve the result by using T2ST. We used Whisper, a multilingual audio transcription model, to convert the audio into text (if you want to know more details about Whisper, you can check our article). Then, we use Seamless4MT v2 to translate the English transcription into Portuguese and generate the final speech.
We load the Whisper pipeline from HF open/whisper-medium, and we set chunk_length_s to 30 seconds. This is important because Whisper was trained with chunks of 30 seconds, so if you have a bigger audio file and do not adjust this parameter, your transcription will be truncated.
pipe = pipeline(
"automatic-speech-recognition",
model="openai/whisper-medium",
chunk_length_s=30,
device=DEVICE,
)Whisper can automatically translate the transcription from English to Portuguese, but since we want SeamlessM4T v2 to perform the translation, we avoid it by setting pipe.model.config.forced_decoder_ids to None .
# to avoid direct translation
pipe.model.config.forced_decoder_ids = NoneFinally, we can obtain the transcription by just running these 3 lines of code:
# same as before, convert the sample rate to 16000
audio, orig_freq = torchaudio.load("data/ZAAI_intro.wav")
audio = torchaudio.functional.resample(audio, orig_freq=orig_freq, new_freq=16_000) # must be a 16 kHz waveform array
# perform the transcription
prediction = pipe(audio.numpy()[0], batch_size=8)["text"]With the English transcription, we would expect to pass this text as input to SeamlessM4T v2 and obtain a perfect T2ST, which did not happen. As before, SeamlessM4T v2 is not ready to handle big chunks of input text; therefore, to overcome this flaw, we loop over all the sentences in our text and pass one at a time to SeamlessM4T v2 to perform T2ST.
# T2ST
audio_array = []
for i in prediction.split('.'):
text_inputs = processor(text=i, src_lang="eng", return_tensors="pt").to(DEVICE)
audio_array_from_text = model.generate(**text_inputs, tgt_lang="por")[0].cpu().numpy().squeeze()
audio_array.append(audio_array_from_text)
audio_array = np.concatenate(audio_array)
# you can also check the translated test by running this
for i in prediction.split('.'):
text_inputs = processor(text=i, src_lang="eng", return_tensors="pt").to(DEVICE)
output_tokens = model.generate(**text_inputs, tgt_lang="por", generate_speech=False)
translated_text_from_text = processor.decode(output_tokens[0].tolist()[0], skip_special_tokens=True)
print(translated_text_from_text)
Olá a todos, sou o Luís, fundador e sócio da Zai. Estamos na beira da inovação e tecnologia de IA. Temos duas áreas principais em que nos concentramos Em primeiro lugar, construímos projetos de consultoria altamente complexos para clientes empresariais, desbloqueando valor real com IA gerativa, previsão de séries temporais, sistemas de recomendação, modelos de marketing E a segunda área principal é que financiamos startups de núcleo de IA onde os ajudamos a desenvolver a tecnologia, mas também em sua estratégia de lançamento no mercado
The result is better, as you can see, by running the code in our notebook and listening to the outputted audio file.
Conclusion
Economic globalization means cross-border trade of goods and services, which brings new challenges for companies, such as understanding different cultures and being able to communicate in different languages.
In this article, we showed how companies could save financial resources by translating advertisements using AI and open-source solutions. Although the core model of this article, SeamlessM4T v2, did not work perfectly due to the inability to handle large sequences of audio and text, we managed to solve those flaws by combining Whisper for transcription and SeamlessM4T v2 for text-to-speech translation. Another possibility for companies, but involving more costs and time, would be fine-tuning SeamlessM4T v2 in speech-to-speech translation based on previous advertisements.
All in all, companies like Meta and OpenAI seem focused on trying to remove language barriers as much as possible to bring together the ever-connected world we live in today further. And we will continue our mission of sharing these initiatives and showing how they can solve day-to-day problems by implementing them in practical use cases.
About me
Serial entrepreneur and leader in the AI space. I develop AI products for businesses and invest in AI-focused startups.
References
[1] Loïc Barrault, Yu-An Chung, Mariano Coria Meglioli, David Dale, Ning Dong, Mark Duppenthaler, Paul-Ambroise Duquenne, Brian Ellis, Hady Elsahar, Justin Haaheim, John Hoffman, Min-Jae Hwang, Hirofumi Inaguma, Christopher Klaiber, Ilia Kulikov, Pengwei Li, Daniel Licht, Jean Maillard, Ruslan Mavlyutov, Alice Rakotoarison, Kaushik Ram Sadagopan, Abinesh Ramakrishnan, Tuan Tran, Guillaume Wenzek, Yilin Yang, Ethan Ye, Ivan Evtimov, Pierre Fernandez, Cynthia Gao, Prangthip Hansanti, Elahe Kalbassi, Amanda Kallet, Artyom Kozhevnikov, Gabriel Mejia Gonzalez, Robin San Roman, Christophe Touret, Corinne Wong, Carleigh Wood, Bokai Yu, Pierre Andrews, Can Balioglu, Peng-Jen Chen, Marta R. Costa-jussà, Maha Elbayad, Hongyu Gong, Francisco Guzmán, Kevin Heffernan, Somya Jain, Justine Kao, Ann Lee, Xutai Ma, Alex Mourachko, Benjamin Peloquin, Juan Pino, Sravya Popuri, Christophe Ropers, Safiyyah Saleem, Holger Schwenk, Anna Sun, Paden Tomasello, Changhan Wang, Jeff Wang, Skyler Wang, Mary Williamson. Seamless: Multilingual Expressive and Streaming Speech Translation. arXiv:2312.05187, 2023.
[2] Loïc Barrault, Yu-An Chung, Mariano Cora Meglioli, David Dale, Ning Dong, Paul-Ambroise Duquenne, Hady Elsahar, Hongyu Gong, Kevin Heffernan, John Hoffman, Christopher Klaiber, Pengwei Li, Daniel Licht, Jean Maillard, Alice Rakotoarison, Kaushik Ram Sadagopan, Guillaume Wenzek, Ethan Ye, Bapi Akula, Peng-Jen Chen, Naji El Hachem, Brian Ellis, Gabriel Mejia Gonzalez, Justin Haaheim, Prangthip Hansanti, Russ Howes, Bernie Huang, Min-Jae Hwang, Hirofumi Inaguma, Somya Jain, Elahe Kalbassi, Amanda Kallet, Ilia Kulikov, Janice Lam, Daniel Li, Xutai Ma, Ruslan Mavlyutov, Benjamin Peloquin, Mohamed Ramadan, Abinesh Ramakrishnan, Anna Sun, Kevin Tran, Tuan Tran, Igor Tufanov, Vish Vogeti, Carleigh Wood, Yilin Yang, Bokai Yu, Pierre Andrews, Can Balioglu, Marta R. Costa-jussà, Onur Celebi, Maha Elbayad, Cynthia Gao, Francisco Guzmán, Justine Kao, Ann Lee, Alexandre Mourachko, Juan Pino, Sravya Popuri, Christophe Ropers, Safiyyah Saleem, Holger Schwenk, Paden Tomasello, Changhan Wang, Jeff Wang, Skyler Wang. SeamlessM4T: Massively Multilingual & Multimodal Machine Translation. arXiv:2308.11596, 2023.
[3] Yu-An Chung, Yu Zhang, Wei Han, Chung-Cheng Chiu, James Qin, Ruoming Pang, Yonghui Wu. W2v-BERT: Combining Contrastive Learning and Masked Language Modeling for Self-Supervised Speech Pre-Training. arXiv:2108.06209, 2021.
[4] Jinming Zhao, Hao Yang, Ehsan Shareghi, Gholamreza Haffari. M-Adapter: Modality Adaptation for End-to-End Speech-to-Text Translation. arXiv:2207.00952, 2022.
[5] Marta R. Costa-jussà, James Cross, Onur Çelebi, Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula, Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Hoffman, Semarley Jarrett, Kaushik Ram Sadagopan, Dirk Rowe, Shannon Spruit, Chau Tran, Pierre Andrews, Necip Fazil Ayan, Shruti Bhosale, Sergey Edunov, Angela Fan, Cynthia Gao, Vedanuj Goswami, Francisco Guzmán, Philipp Koehn, Alexandre Mourachko, Christophe Ropers, Safiyyah Saleem, Holger Schwenk, Jeff Wang. No Language Left Behind: Scaling Human-Centered Machine Translation. arXiv:2207.04672, 2022.
[6] Hirofumi Inaguma, Sravya Popuri, Ilia Kulikov, Peng-Jen Chen, Changhan Wang, Yu-An Chung, Yun Tang, Ann Lee, Shinji Watanabe, Juan Pino. UnitY: Two-pass Direct Speech-to-speech Translation with Discrete Units. arXiv:2212.08055, 2023.
[7] Jungil Kong, Jaehyeon Kim, Jaekyoung Bae. HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis. arXiv:2010.05646, 2020.
More articles: https://zaai.ai/lab/