

Unlock the potential of cross-language information accessibility with advanced transcription and semantic search technologies
This article was co-authored by Luís Roque and Rafael Guedes
Introduction
In our ever-connected world, where information has no borders, the ability to make it accessible to everyone, regardless of their native language or their capacity to learn a new language, is very relevant. Whether you are a content creator or lead a worldwide organization, being able to quickly and effortlessly help your followers/customers search for specific information in several languages has several benefits. For example, it can support customers with the same questions already answered in a different language.
Consider a different use case where you frequently have to attend company meetings. Often, you might be unable to participate, and many topics discussed may not be relevant to you. Wouldn’t it be convenient if you could search for the topics that interest you and receive a summary, including the start and end times of the relevant discussions? This way, instead of spending an hour in a meeting, you could spend just ten to fifteen minutes gathering the necessary information, significantly boosting your productivity. Additionally, you might have meetings recorded in Portuguese and English. Nevertheless, you are interested in conducting your search in English.
In this article, we will show you how to implement multilingual audio transcription and multilingual semantic search so that you can implement it for your use cases. For the multilingual audio transcription, we will explain how Whisper and WhisperX work, their limitations, and how to use them in Python.
Then, we introduce how multilingual semantic search models are trained and why you can get the same information from a vector database regardless of the language you queried with. We also provide a detailed implementation of semantic search resorting to Postgres and PGVector.
Finally, we show the results of the above on two use cases. We use two videos, one in Portuguese and the other in English, and we query them with the same question in Portuguese and English to check if we obtain the same answer.
As always, the code is available on our GitHub.
WhisperX: A robust architecture for audio transcription
WhisperX [1] is the evolved form of Whisper [2], a model developed by OpenAI. But what are the differences between them?
Whisper and WhisperX are speech recognition models capable of multilingual speech recognition, speech translation, spoken language identification, and voice activity detection. They rely on a transformer sequence-to-sequence architecture to represent various speech-processing tasks as a sequence of tokens to be predicted by the decoder.
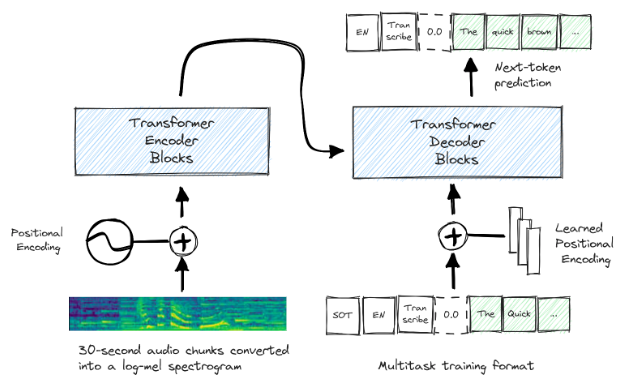
Despite the excellent performance of Whisper in different domains and languages, it needs to improve when it comes to long audio transcriptions. The main reason for this problem is due to the sliding window approach used during training. It often results in drifting and hallucinations. It also presents limitations when aligning the transcription with the audio timestamps.
WhisperX comes along to solve these problems:
- Drifting and Hallucinations are solved using Voice Activity Detection (VAD) and a custom approach to cut and merge the audio chunks. VAD detects the presence or absence of human voice and splits the input audio into segments according to that classification. After that, it cuts and merges the segments with human voice into windows of 30 seconds. It tries to define the boundaries in regions with a low probability of speech. The segments are cut in windows of 30 seconds to match the duration of the segments which Whisper was trained with.
- Transcription Alignment is solved using Forced Alignment, the last layer of the architecture. It uses a phoneme recognition model to identify the smallest unit of speech that distinguishes one word from the next, e.g., the element ‘t’ in ‘nut’. It then obtains the start and end times for each word by taking the start and end times of the first and last phonemes of the same word for a more reliable alignment.
Whisper and WhisperX in practice
We can use Whisper or WhisperX to transcribe audio with just a few lines of code. We need to install Whisper and WhisperX from git+https://github.com/openai/whisper.git and git+https://github.com/m-bain/whisperx.git, respectively.
Once the installation is done, we start by importing Whisper or WhisperX. Then, we load the model and, finally, we transcribe the audio file in .wav format. The result will be a dictionary with three keys:
‘text’ is a string with the whole transcription.
‘segments’ is a list of segments of text with the start and end time and some other metadata.
‘language’ is a string with the language of the audio.
### ----- WHISPER ----- ###
import whispermodel = whisper.load_model("large", "cpu")
result = model.transcribe("<YOUR AUDIO FILE>.wav")### ----- WHISPERX ----- ###
import whisperxmodel = whisperx.load_model("large-v2", "gpu", compute_type="float16")
audio = whisperx.load_audio("<YOUR AUDIO FILE>.wav")
result = model.transcribe(audio)
As mentioned before, Whisper has some limitations when aligning the transcription with the audio timestamps. Therefore, we use WhisperX to solve that problem.
We load the alignment model, and based on the result from Whisper or WhisperX, we correct its alignment.
from whisperx import load_align_model, align
model_a, metadata = load_align_model(language_code=result['language'], device="cpu")
result_aligned = align(result['segments'], model_a, metadata, "<YOUR AUDIO FILE>.wav", "cpu")
Semantic Search: A multilingual approach
Semantic search is a search engine technology that matches the meaning of a query, as opposed to traditional search approaches that match the keywords of a query.
Semantic search is made effective through the use of Transformers, which are crucial for their ability to convert documents in free-text form into numerical representations. These representations, called embeddings, are essentially vectors stored in vector databases like PGVector. This process enables semantic search to match queries based on meaning or intent, significantly enhancing the accuracy and relevance of search results.
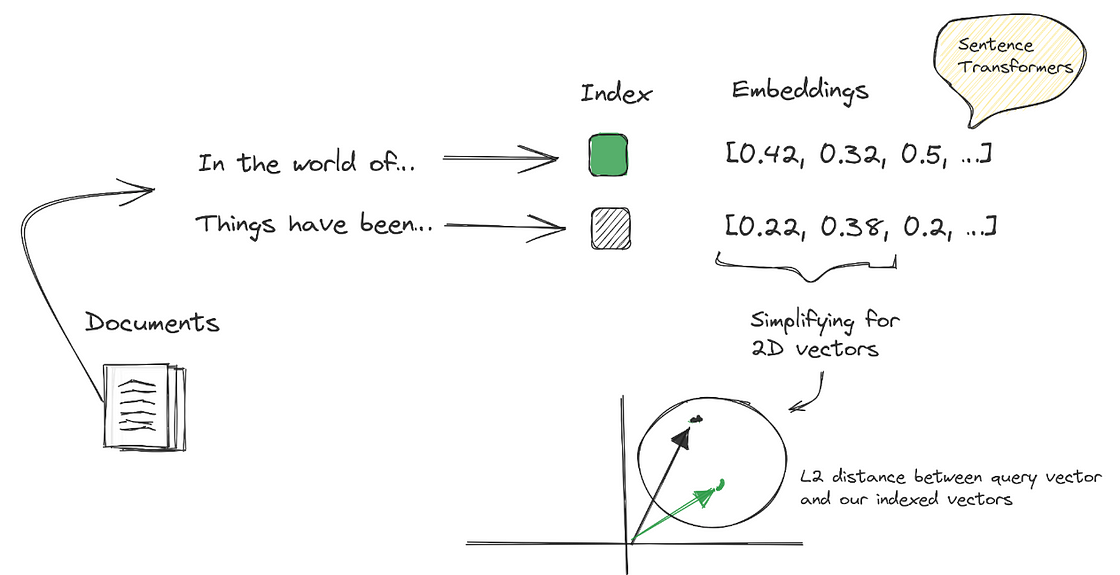
When a user submits a query, it is converted into an embedding. This embedding is then utilized by the vector database’s built-in retrieval system, typically based on the k-nearest neighbor (kNN) algorithm. The system uses this algorithm to identify and rank the k most similar documents to the user’s query based on their relevance. This process ensures that the results retrieved are closely aligned with the user’s search intent.
Latest advancements in NLP, particularly in semantic search, have made it possible to create identical embeddings for the same sentence in different languages [3]. This brings a huge advantage for organizations that operate worldwide because they can quickly and costlessly extend semantic search to a more significant set of languages. This is possible with relatively few samples and low hardware requirements, as mentioned by the authors of the approach we will follow.
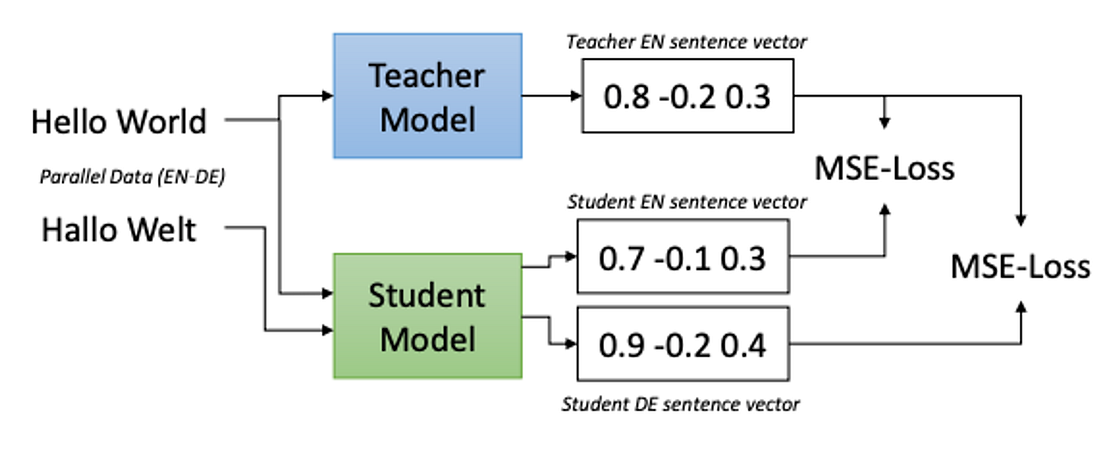
Expanding monolingual models, typically based on the English language, involves using both a Teacher and Student Model. These models play distinct yet complementary roles in adapting language models to handle multiple languages effectively.
Teacher Model: This model serves as a reference point or a standard. It is typically a well-trained, high-performance model in the source language, often English. The Teacher Model has a deep understanding of the language and can produce high-quality embedding vectors accurately representing the meanings of various texts.
Student Model: The Student Model is designed to learn from the Teacher Model. Unlike the Teacher Model, which operates solely in the source language, the Student Model works with both the source and translated languages. The primary goal of the Student Model is to replicate the performance of the Teacher Model in the new language context.
The reason these models are used and why they work effectively lies in their training approach:
- Alignment of Embeddings: The Student Model is trained to minimize the mean-squared error between its embeddings and those produced by the Teacher Model. This process ensures that the embeddings produced by the Student Model in both the source and translated languages closely match those of the Teacher Model.
- Language Adaptation: This training approach enables the Student Model to adapt to a new language while maintaining the quality and characteristics of the original model. By aligning its understanding with the Teacher Model, the Student Model can effectively process and understand the translated language.
- Efficient Learning: The Student Model doesn’t have to learn from scratch. By using the already sophisticated understanding of the Teacher Model, the Student Model can achieve high performance with potentially less data and training time for the new language.
- Consistency Across Languages: This method ensures consistency in the model’s performance across different languages. It is particularly beneficial in maintaining the quality of embeddings, which are crucial for tasks like semantic search, natural language understanding, and translation.
Although several architectures can be used, the authors used Sentence-BERT [4] for the Teacher Model and XLM-RoBERTa [5] for the Student Model.
Implementing Multilingual Semantic Search with PGVector
In this section, we cover the implementation of PGVector on top of Postgres. We also deploy a pgAdmin application to query Postgres and check how our embeddings are stored.
We resort to LangChain to encode the transcription from Whisper or WhisperX, insert it into a table in Postgres, and retrieve the documents most similar to a user’s query.
Since, for our use case, we need to be able to retrieve information regardless of the language of the audio or the user’s query, we use multi-qa-mpnet-base-dot-v1 from sentence-transformers to encode the transcription. We chose this model because it performs best on multilingual semantic searches (you can check the models available for multilingual semantic searches here).
Set up PGVector
We deploy Postgres powered by PGVector using Docker. We start by defining the docker-compose.yml file with two containers, postgres and pgadmin.
Postgres:
- Image:
ankane/pgvectorallows us to deploy Postgres with PGVector extension. - Ports: 5432
- Environment: user and password to interact with Postgres and a database to store our embeddings.
pgAdmin:
- Image:
dpage/pgadmin4. - Ports: 5050
- Environment: email and password for login.
version: '3.8'
services:
postgres:
container_name: container-pg
image: ankane/pgvector
hostname: localhost
ports:
- "5432:5432"
environment:
POSTGRES_USER: admin
POSTGRES_PASSWORD: root
POSTGRES_DB: postgres
volumes:
- postgres-data:/var/lib/postgresql/data
restart: unless-stopped
pgadmin:
container_name: container-pgadmin
image: dpage/pgadmin4
depends_on:
- postgres
ports:
- "5050:80"
environment:
PGADMIN_DEFAULT_EMAIL: admin@admin.com
PGADMIN_DEFAULT_PASSWORD: root
restart: unless-stopped
volumes:
postgres-data:
Once the docker-compose file is defined, we can start our application by running docker-compose up -d command in the same directory of the docker-compose file.
With our application running, it is time to create a server in pgAdmin so that we can query our embeddings and documents. To accomplish that, we must follow these steps:
- Open the pgAdmin web interface in a web browser using http://localhost:5050/.
- Log in using the email and password we set in the
PGADMIN_DEFAULT_EMAILandPGADMIN_DEFAULT_PASSWORDenvironment variables in the docker-compose file. - Right-click on the Servers node, and select Register → Server.
- In the Create — Server dialog, insert a name for the server in the Name field.
- In the Connection tab, insert the following information:
- Host name/address:
postgres - Port:
5432 - Maintenance database: You can use the
postgresdatabase for this purpose. - Username:
POSTGRES_USERenvironment variable that we set in the docker-compose file. - Password:
POSTGRES_PASSWORDenvironment variable that we set in the docker-compose file. - Click the Save button to create the server.
With the server created, let’s populate the recently created database called postgres with embeddings and documents.
Note: This pgAdmin is optional; you can skip this step if you do not want to query the embeddings.
Populate Postgres with LangChain
Once the database is set and ready to store embeddings, it is time to define an encoder. Afterward, we use LangChain to populate and retrieve the most similar documents to a user’s query from the database.
As mentioned above, the encoder is multilingual and can be defined as:
from langchain.embeddings import HuggingFaceEmbeddings
encoder = HuggingFaceEmbeddings(
model_name=”sentence-transformers/multi-qa-mpnet-base-dot-v1″,
model_kwargs={“device”: “cpu”},
)
LangChain has integration with PGVector. Therefore, to connect LangChain with Postgres, we need to define the string connection as follows:
from langchain.vectorstores.pgvector import PGVector
CONNECTION_STRING = PGVector.connection_string_from_db_params(
driver=”psycopg2″, # driver to connect with postgres
host=”localhost”, # host defined in docker-compose.yml
port=”5432″, # port defined in docker-compose.yml
database=”postgres”, # database defined in docker-compose.yml
user=”admin”, # user defined in docker-compose.yml
password=”root”, # password defined in docker-compose.yml
)
Note that the COLLECTION_NAME must be unique because it will be used as a key by PGVector to identify the documents to retrieve from Postgres. For our use case, we can think of COLLECTION_NAME as the meeting ID, allowing us to retrieve information from the meeting the user is interested in.
COLLECTION_NAME = "Meeting ID"
With the encoder, connection, and collection name defined, we transform the transcription from Whisper or WhisperX into Documents (the expected format from LangChain). We also create and populate a table with the embeddings.
from langchain.docstore.document import Document
# Transform transcription into documents and add the start and end time of each sequence
docs = [Document(page_content=f’start {item[“start”]} – end {item[“end”]}: {item[“text”]}’) for item in result[‘segments’]]
db = PGVector.from_documents(
embedding=encoder,
documents=docs,
collection_name=COLLECTION_NAME,
connection_string=CONNECTION_STRING,
pre_delete_collection=True, # deletes previous records, useful for testing
)
After creating and populating the table, we can query the database and get the most similar documents using LangChain:
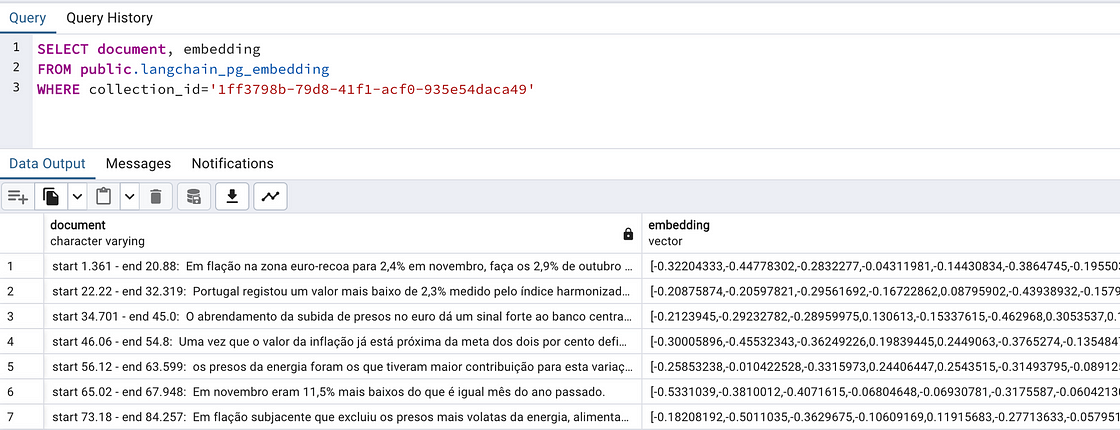
similar_docs = db.similarity_search("<USER QUERY>")Or we can also go to pdAdmin and query Postgres to check how the embeddings and the documents look like:
Does Multilingual Semantic Search work?
We converted two videos of Luis talking about two different subjects into audio. In the first, Luis talks about his previous startup in Portuguese; in the second, he talks about Probabilistic Deep Learning. We then query both using Portuguese and English and compare the retrieved documents.
For the Portuguese use case, we used the following queries
- Portuguese:
marcas e investimentos - English:
brands and investments
As a result, 4 out of the top 4 most relevant documents retrieved were the same in both cases:
start 81.401 — end 85.26: uma marca baseada em Berlim, portanto ao invés de esperarmos que esse investimento chegasse,
start 111.902 — end 117.26: para maturar o produto, para investir em tecnologia e para investir no business development.
start 88.58 — end 93.039: Estas duas rondas de investimento que nós já fizemos com uma capacidade também diferente start
28.6 — end 32.64: Portanto, damos toda a componente de infraestrutura logística que uma marca precisa.
For the English use case, we used the following queries
- Portuguese:
modelos de aprendizagem profunda - English:
deep learning models
We had to retrieve eight documents for the Portuguese query to find the relevant documents. This happens because, in Portuguese, we usually do not translate ‘Deep Learning’; we use the English expression. Thus, the model probably did not have enough data to train with.
start 45.28 — end 51.9: when we are using deep learning models, usually we are relying on maximum likelihood estimation
On the other hand, the following queries had the same top 4 results
- Portuguese:
distribuição normal - English:
normal distribution
It shows that for terms often translated, such as ‘normal distribution’ to ‘distribuição normal’, our approach produces the relevant outputs.
Conclusion
Multilingual audio transcription and semantic search are valuable assets to build a more connected world. Our examples are just the tip of the iceberg; many more technologies can be combined to tackle different use cases.
Consider a scenario where a Retrieval-Augmented Generation (RAG) system is employed for customer support. Usually, in a customer support system, customers ask questions in any language. We could encode these questions with a multilingual model and use a retriever to pull relevant past responses from customer care experts for context. The Large Language Model (LLM) uses this context to generate an answer translated into the customer’s language. This system efficiently reduces the workload on customer care experts and provides quick, real-time customer support.
While our approach offers extensive possibilities, it is not a one-size-fits-all solution. For instance, in our experiments, the retriever failed to semantically link ‘Deep Learning’ with its Portuguese equivalent, ‘Aprendizagem Profunda.’ Overcoming such limitations requires fine-tuning with specific data or implementing rule-based mechanisms to improve document retrieval accuracy, especially across different languages.
References
[1] Max Bain, Jaesung Huh, Tengda Han, Andrew Zisserman. WhisperX: Time-Accurate Speech Transcription of Long-Form Audio. arXiv:2303.00747, 2023
[2] Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever. Robust Speech Recognition via Large-Scale Weak Supervision. ********arXiv:2212.04356, 2022
[3] Nils Reimers, Iryna Gurevych. Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation. arXiv:2004.09813, 2020.
[4] Nils Reimers, Iryna Gurevych. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv:1908.10084, 2019.
[5] Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, Veselin Stoyanov. Unsupervised Cross-lingual Representation Learning at Scale. arXiv:1911.02116, 2019.
More articles: https://zaai.ai/lab/
A deep exploration of TiDE, its implementation using Darts and a real life use case comparison with DeepAR and TFT (a Transformer architecture)
This article was authored by Rafael Guedes
Introduction
As industries continue to evolve, the importance of an accurate forecasting becomes a non-negotiable asset whether you work in e-commerce, healthcare, retail or even in agriculture. The importance of being able to foresee what comes next and plan accordingly to overcome future challenges is what can make you ahead of competition and thrive in an economy where margins are tight and the customers are more demanding than ever.
Transformer architectures have been the hot topic in AI for the past few years, specially due to their success in Natural Language Processing (NLP) being one of the most successful use cases the chatGPT that took the attention of everyone regardless if you were an AI enthusiastic or not. But NLP is not the only subject where Transformers have been shown to outperform the state-of-the-art solutions, in Computer Vision as well with Stable Diffusion and its variants.
But can Transformers outperform state-of-the-art models in time series? Although many efforts have been made to develop Transformers for time series forecasting, it seems that for long term horizons, simple linear models can outperform several Transformer based approaches.
In this article I explore TiDE, a simple deep learning model which is able to beat Transformer architectures in long term forecasting. I also provide a step-by-step implementation of TiDE to forecast weekly sales in a dataset from Walmart using Darts a forecasting library for Python. And finally, I compare the performance of TiDE, DeepAR and TFT in a real life use case from my company.
As always, the code is available on Github.
Time-series Dense Encoder Model (TiDE)
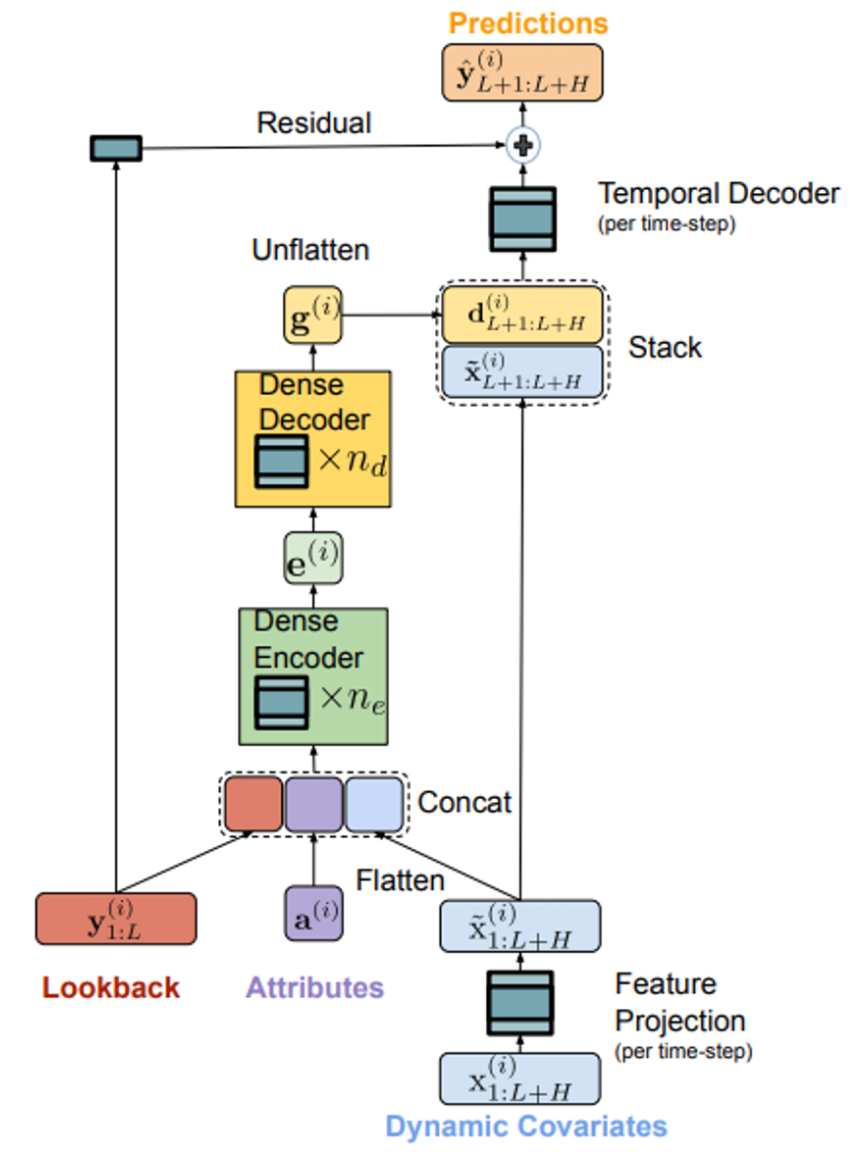
TiDE is a novel time-series encoder-decoder model that has shown to outperform state-of-the-art Transformer models in long-time horizon forecast [1]. It is a multivariate time-series model that is able to use static covariates (e.g. brand of a product) and dynamic covariates (e.g. price of a product) which can be known or unknown for the forecast horizon.
Unlike the complex architecture of Transformers, TiDE is based on a simple Encoder-Decoder architecture with only Multi-Layer Perceptron (MLP) and without any Attention layer.
The Encoder is responsible for mapping the past and the covariates of a time-series into a dense representation of features through two key steps:
- Feature Projection which reduces the dimensionality of the dynamic covariates for the whole look-back and the horizon. and;
- Dense Encoder which receives the output of the Feature Projection concatenated with static covariates and the past of the time-series and maps them into an embedding.
The Decoder receives the embedding from the encoder and converts it into future predictions through two operations:
- Dense Decoder which maps the embedding into a vector per time-step in the horizon; and
- Temporal Decoder which combines the output of the Dense Decoder with the projected features of that time-step to produce the predictions.
The Residual Connection linearly maps the look-back to a vector with the size of the horizon which is added to the output of the Temporal Decoder to produce the final predictions.
How to use TiDE in practice
This section covers a step by step implementation of TiDE using a weekly sales dataset from Walmart available on kaggle (License CC0: Public Domain) and resorting to a package called Darts.
Darts is a Python library for forecasting and anomaly detection [2] that contains several models such as naive models to serve as baseline, traditional models like ARIMA or Holt-Winters, deep learning models like TiDE or TFT or tree based models like LightGBM or Random Forest. It also supports both univariate and multivariate models and some of them offer probabilistic forecasting solutions.
The training dataset has 2 years and 8 months of weekly sales and 5 columns:
- Store — store number and one of the static covariates
- Dept — department number and the other static covariates
- Date — the temporal index of the time series which is weekly and it will be used to extract dynamic covariates like the week number and the month
- Weekly_Sales — the target variable
- IsHoliday — another dynamic covariate that identifies if there is a holiday in a certain week
The test dataset has the same columns except for the target (Weekly_Sales).
We start by importing the libraries we need and defining some global variables like the date column, target column, static covariates, the frequency of our series and the scaler to use:
# Libraries
import pandas as pd
import numpy as np
from darts import TimeSeries
from darts.models import TiDEModel
from darts.dataprocessing.transformers import Scaler
from darts.utils.timeseries_generation import datetime_attribute_timeseries
from darts.utils.likelihood_models import QuantileRegression
from darts.dataprocessing.transformers import StaticCovariatesTransformer# Global Variables
TIME_COL = "Date"
TARGET = "Weekly_Sales"
STATIC_COV = ["Store", "Dept"]
FREQ = "W-FRI"
SCALER = Scaler()
TRANSFORMER = StaticCovariatesTransformer()The default scaler is MinMax Scaler, but we can use any we want from scikit-learn as long as it has fit(), transform() and inverse_transform() methods. The same happens for the transformer which by default is Label Encoder from scikit-learn.
After that, we load our training dataset and we convert the pandas data frame into TimeSeries which is the expected format from Darts.
I did not performed an EDA since my goal is just to show you how to implement it, but I noticed some negative values which might indicate returns. Nevertheless, I considered them as errors and I replaced them with 0.
I also used the argument fill_missing_dates to add missing weeks and I filled those dates also with 0.
# read train and test datasets and transform train dataset
train = pd.read_csv('data/train.csv')
train["Date"] = pd.to_datetime(train["Date"])
train[TARGET] = np.where(train[TARGET] < 0, 0, train[TARGET])
train_darts = TimeSeries.from_group_dataframe(
df=train,
group_cols=STATIC_COV,
time_col=TIME_COL,
value_cols=TARGET,
static_cols=STATIC_COV,
freq=FREQ,
fill_missing_dates=True,
fillna_value=0)We also load our test dataset so that we define what is our forecast horizon and what are the holidays in the forecast horizon.
# read test dataset and determine Forecast Horizon
test = pd.read_csv('data/test.csv')
test["Date"] = pd.to_datetime(test["Date"])
FORECAST_HORIZON = len(test['Date'].unique())After that, for each serie in the training set we create dynamic covariates (week, month and a binary column that idenitfies the presence of a holiday in a specific week):
# we get the holiday data that we have in both train and test dataset
holidays_df = pd.concat([train[["Date", "IsHoliday"]], test[["Date", "IsHoliday"]]]).drop_duplicates()
# convert bool to numeric
holidays_df["IsHoliday"] = holidays_df["IsHoliday"]*1
# create dynamic covariates for each serie in the training darts
dynamic_covariates = []
for serie in train_darts:
# add the month and week as a covariate
covariate = datetime_attribute_timeseries(
serie,
attribute="month",
one_hot=True,
cyclic=False,
add_length=FORECAST_HORIZON,
)
covariate = covariate.stack(
datetime_attribute_timeseries(
serie,
attribute="week",
one_hot=True,
cyclic=False,
add_length=FORECAST_HORIZON,
)
)# create holidays with dates for training and test
holidays_serie = pd.merge(pd.DataFrame(covariate.time_index).rename(columns={'time':'Date'}), holidays_df, on='Date', how='left')
covariate = covariate.stack(
TimeSeries.from_dataframe(holidays_serie, time_col="Date", value_cols="IsHoliday", freq=FREQ)
)
dynamic_covariates.append(covariate)Now, that we have all the data ready we just need to scale our data:
# scale covariates
dynamic_covariates_transformed = SCALER.fit_transform(dynamic_covariates)
# scale data
data_transformed = SCALER.fit_transform(train_darts)
# transform static covariates
data_transformed = TRANSFORMER.fit_transform(data_transformed)Finally, we are ready to make predictions!
In our case, we will predict for the next 38 weeks the weekly sales for the same series that we trained with, however you can also forecast for time series that are not part of your training set as long as they have the same static covariates. For that, you have to repeat the same process of data preparation.
TiDE_params = {
"input_chunk_length": 4, # number of weeks to lookback
"output_chunk_length": FORECAST_HORIZON,
"num_encoder_layers": 1,
"num_decoder_layers": 1,
"decoder_output_dim": 1,
"hidden_size": 15,
"temporal_width_past": 4,
"temporal_width_future": 4,
"temporal_decoder_hidden": 26,
"dropout": 0.1,
"batch_size": 16,
"n_epochs": 5,
"likelihood": QuantileRegression(quantiles=[0.25, 0.5, 0.75]),
"random_state": 42,
"use_static_covariates": True,
"optimizer_kwargs": {"lr": 1e-3},
"use_reversible_instance_norm": False,
}model = TiDEModel(**TiDE_params)
model.fit(data_transformed, future_covariates=dynamic_covariates_transformed, verbose=False)
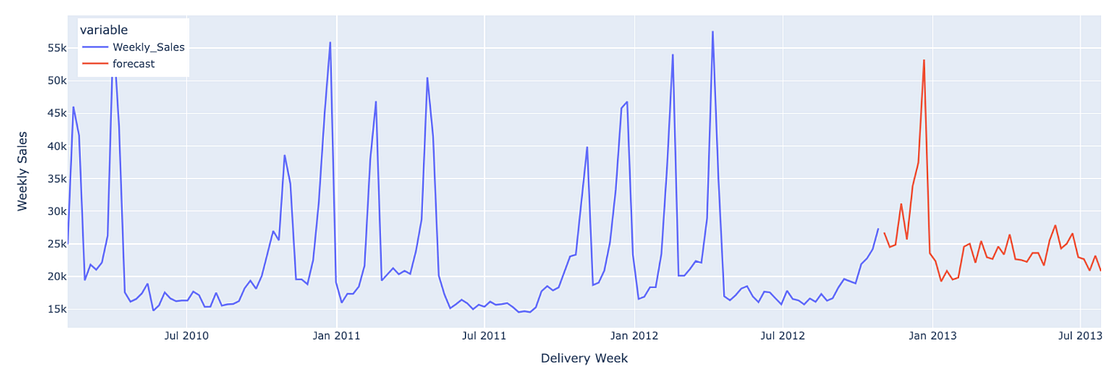
pred = SCALER.inverse_transform(model.predict(n=FORECAST_HORIZON, series=data_transformed, future_covariates=dynamic_covariates_transformed, num_samples=50))Here we have an example of the forecast for Store 1 and Dept 1, where we can see that the model was able to forecast a spike in the week of Black Friday and Thanksgiving from 2012 due to the three dynamic covariates that we had (week, month and the binary column which identifies a holiday in a certain week). We can also see that there are several spikes across the year that comes probably from discounts or marketing campaigns that can be handled by dynamic covariates to improve our forecast and that data is also available on kaggle.
TiDE vs DeepAR and TiDE vs TFT in a real life use case
In my company, we deployed, in the end of 2022, a new forecasting model which aimed to predict the volume of orders of 264 time series for the next 16 weeks.
The model that beat the one in production at that time was DeepAR, a deep learning architecture available in the Python library GluonTS [3]. Like TiDE, DeepAR allows the use of static and dynamic covariates.
Although DeepAR was providing us good results, it suffered from a problem on longer horizons (+8 weeks) that we called ‘Exploding Predictions’. From one week to the other, with just one more week of data, the model would make a total different forecast from the previous week with volumes higher than normal.
Nevertheless, we came up with mechanisms to control this and change one particular hyper parameter (context length, that DeepAR is really sensitive to) to avoid this kind of situations, but lately it has been shown to not be enough and we had to closely monitor every week the results and change other hyper parameters to come up with a reasonable forecast.
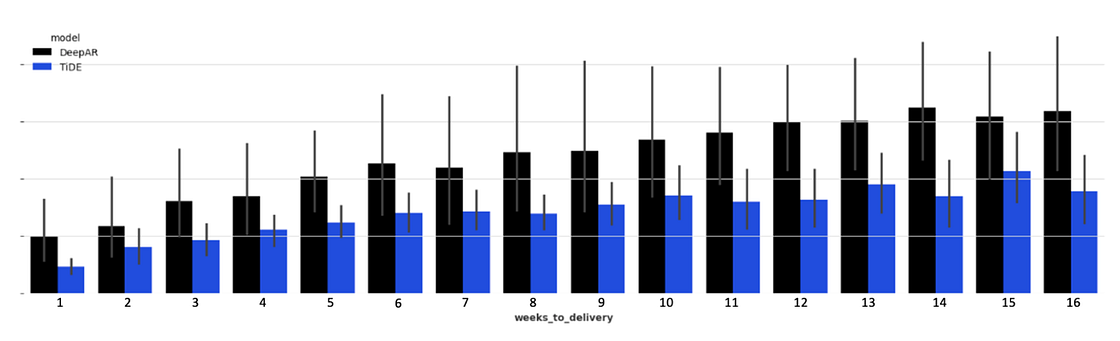
So we decided to start a new round of research to find a model that is more stable and reliable and it was when we found TiDE. We optimised TiDE in terms of hyper parameters, which dynamic and static covariates to use, which series would go to training and which would not, etc. And we compared both optimised models, DeepAR and TiDE, in 26 different cut off dates for a entire year of data from July 2022 to July 2023.
The results showed that TiDE was not just better than DeepAR in the short and long term (as you can see in Figure 4) but it did not suffer from the initial problem we wanted to solve of ‘Exploding Predictions’.
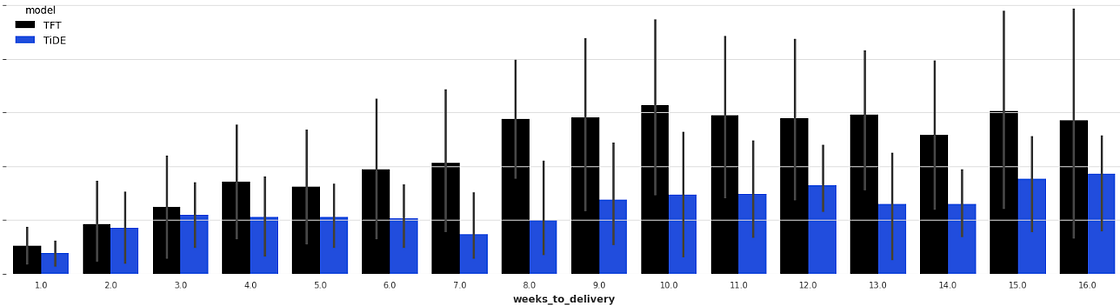
During our model research we also compared TiDE with TFT [4], a Transformer architecture to verify what the authors in [1] stated about TiDE beating Transformer architectures in long term forecasting. And, as we can see from Figure 5, TiDE was able to beat TFT, specially in the long term (6+ weeks).
Conclusion
Transformer architectures will be the foundation for the next big revolution in the history of humanity. Although they are amazing for NLP and Computer Vision, they cannot outperform simpler models on long term forecasting as stated by the authors in [1].
In this article we compared TFT, a Transformer architecture, and DeepAR with TiDE, and we verified that, for our use case, TiDE was able to beat both models.
Nevertheless, if Transformer architectures were robust enough for long term forecasting, why would Google develop a new non Transformer time series model? TSMixer [5] is the latest model developed by Google for time series that beats transformers (including TFT) in M5 competition.
For now, simpler models seem to be better for forecasting but let’s see what the future holds in this subject and if Transformers can be improved to provide better results on the long term!
References
[1] Abhimanyu Das, Weihao Kong, Andrew Leach, Shaan Mathur, Rajat Sen, Rose Yu. Long-term Forecasting with TiDE: Time-series Dense Encoder. arXiv:2304.08424, 2023
[2] Julien Herzen, Francesco Lässig, Samuele Giuliano Piazzetta, Thomas Neuer, Léo Tafti, Guillaume Raille, Tomas Van Pottelbergh, Marek Pasieka, Andrzej Skrodzki, Nicolas Huguenin, Maxime Dumonal, Jan Kościsz, Dennis Bader, Frédérick Gusset, Mounir Benheddi, Camila Williamson, Michal Kosinski, Matej Petrik, Gaël Grosch. Darts: User-Friendly Modern Machine Learning for Time Series, 2022
[3] Alexander Alexandrov, Konstantinos Benidis, Michael Bohlke-Schneider, Valentin Flunkert, Jan Gasthaus, Tim Januschowski, Danielle C. Maddix, Syama Rangapuram, David Salinas, Jasper Schulz, Lorenzo Stella, Ali Caner Türkmen, Yuyang Wang. GluonTS: Probabilistic Time Series Models in Python. arXiv:1906.05264, 2019
[4] Bryan Lim, Sercan O. Arik, Nicolas Loeff, Tomas Pfister. Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting. arXiv:1912.09363, 2019
[5] Si-An Chen, Chun-Liang Li, Nate Yoder, Sercan O. Arik, Tomas Pfister. TSMixer: An All-MLP Architecture for Time Series Forecasting. arXiv:2303.06053, 2023
More articles: https://zaai.ai/lab/