

Discover how FinalMLP transforms online recommendations: unlocking personalized experiences with cutting-edge AI research
This article was co-authored by Luís Roque and Rafael Guedes
Introduction
The world has been evolving towards a digital era where everyone has nearly everything they want at a click of distance. These benefits of accessibility, comfort, and a large quantity of offers come with new challenges for the consumers. How can we help them get personalized choices instead of searching through an ocean of options? That is where recommendation systems come in.
Recommendation systems are useful for organizations to increase cross-selling and sales of long-tail items and to improve decision-making by analyzing what their customers like the most. Not only that, they can learn past customer behaviors to, given a set of products, rank them according to a specific customer preference. Organizations that use recommendation systems are a step ahead of their competition since they provide an enhanced customer experience.
In this article, we focus on FinalMLP, a new model designed to enhance click-through rate (CTR) predictions in online advertising and recommendation systems. By integrating two multi-layer perceptron (MLP) networks with advanced features like gating and interaction aggregation layers, FinalMLP outperforms traditional single-stream MLP models and sophisticated two-stream CTR models. The authors tested its effectiveness across benchmark datasets and real-world online A/B tests.
Besides providing a detailed view of FinalMLP and how it works, we also give a walkthrough on implementing and applying it to a public dataset. We test its accuracy in a book recommendation setup and evaluate its ability to explain the predictions, leveraging the two-stream architecture proposed by the authors.
As always, the code is available on our GitHub.
FinalMLP: (F)eature gating and (IN)teraction (A)ggregation (L)ayers on top of two MLPs
FinalMLP [1] is a two-stream Multi-Layer Perceptron (MLP) model built on top of DualMLP [2] to enhance it by introducing 2 new concepts:
- Gating-based feature selection increases the differentiation between the two streams, making each stream focus on learning different patterns from different sets of features. For example, one stream focuses on processing user features, and the other focuses on item features.
- Multi-Head Bilinear Fusion improves how the outputs from both streams are combined by modeling feature interactions. This might not happen using traditional approaches that rely on linear operations like summation or concatenation.
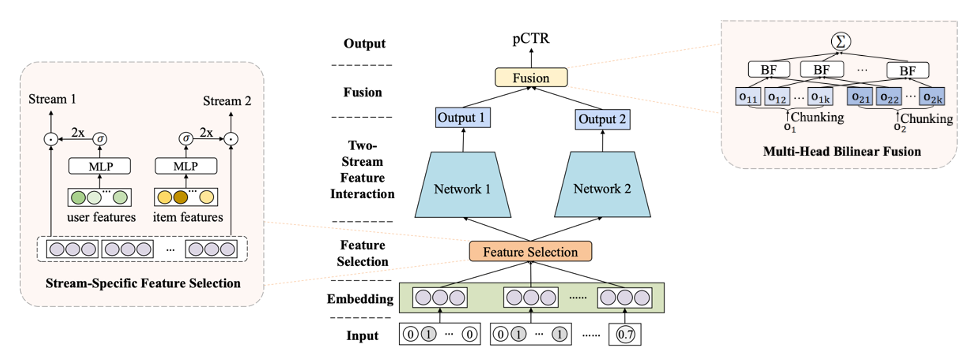
How does it work?
As mentioned before, FinalMLP is a Two-Stream CTR model composed of two simple and parallel MLP networks to learn feature interactions from different views, and it consists of the following key components:
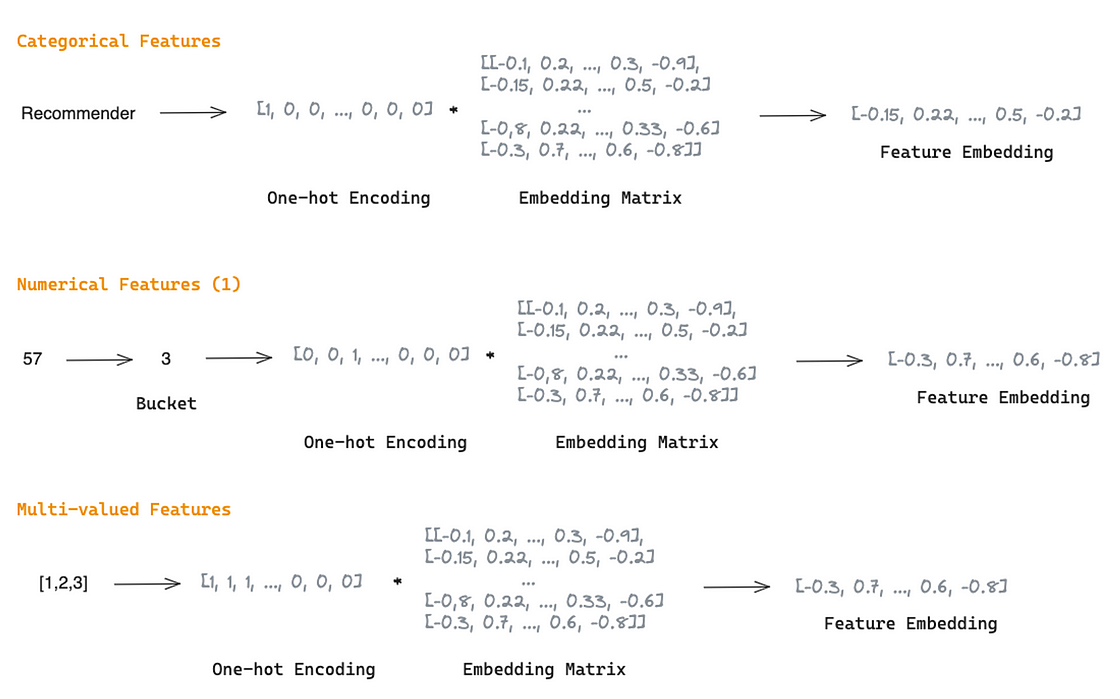
Feature Embedding Layer is a common way to map high-dimensional and sparse raw features into dense numeric representations. Regardless of whether categorical, numerical, or multi-valued, each feature is transformed into an embedding vector and concatenated before feeding the Feature Selection module.
Categorical Features are transformed into a one-hot feature vector and multiplied by a learnable embedding matrix with vocabulary size n and embedding dimension d to generate its embeddings [3].
Numerical Features can be transformed into embeddings via 1) bucketing numeric values into discrete features and, then, handling them as categorical features or 2) given a normalized scalar value xj, the embedding can be given as a multiplication of xj with vj, a shared embedding vector of all features in field j [3].
Multi-valued features can be represented as a sequence of values transformed into a one-hot encoded vector of length k (k is the maximum length of the sequence) and then multiplied by a learnable embedding matrix to generate its embeddings [3].
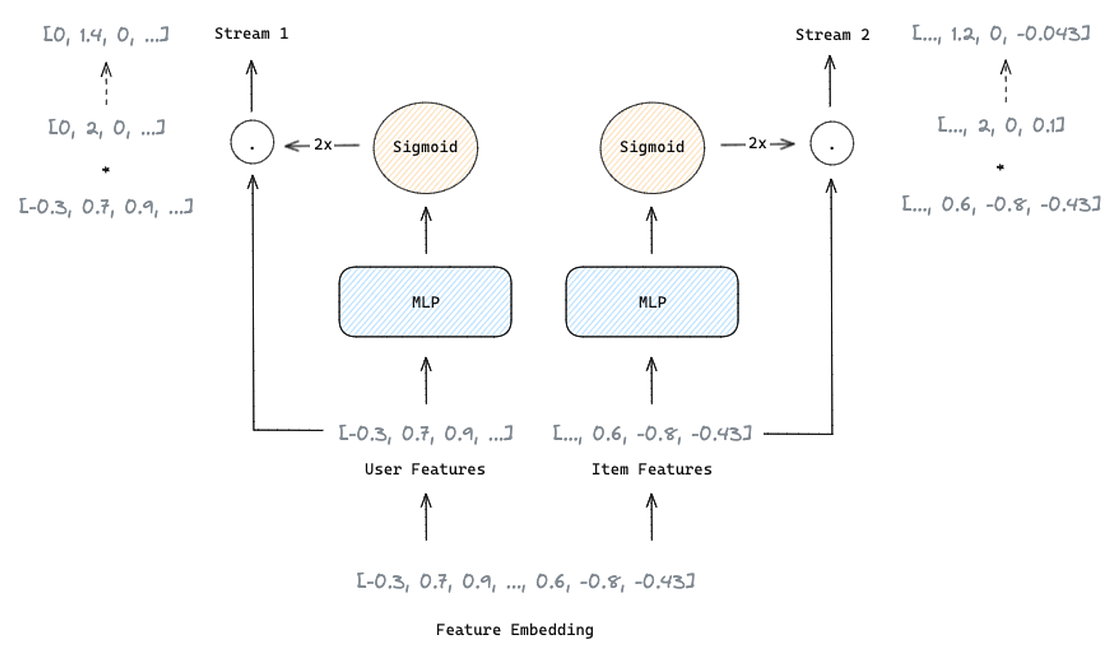
The feature Selection Layer is used to obtain feature importance weights in order to suppress noisy features and make important features have more impact on model predictions.
As mentioned, FinalMLP uses Gating-based feature selection, an MLP with a gating mechanism. It receives the embeddings as input and produces a weighting vector with the same dimension as the input. The feature importance weights are obtained by applying a sigmoid function to the weighting vector followed by a multiplier of 2, generating a vector with a range of [0, 2]. The weighted features are then obtained via element-wise product between the feature embedding and the feature importance weights.
This process reduces the homogeneous learning between the two streams, enabling more complementary learning of feature interactions. It is applied to each stream independently to differentiate the feature inputs for each stream and to allow them to focus on the user or item dimension.
Stream-Level Fusion Layer is required to combine the outputs of both streams to obtain the final predicted probability. Usually, combining both outputs relies on a summation or concatenation operation. However, the authors of FinalMLP propose a bilinear interaction aggregation layer to combine both outputs to get information from feature interaction that a linear combination might fail to obtain.
The authors extended the Bilinear Fusion to a Multi-Head Bilinear Fusion layer inspired by the attention layer from the transformers’ architecture. It is used to reduce computation complexity and improve the model’s scalability.
The bilinear fusion equation consists of the following:
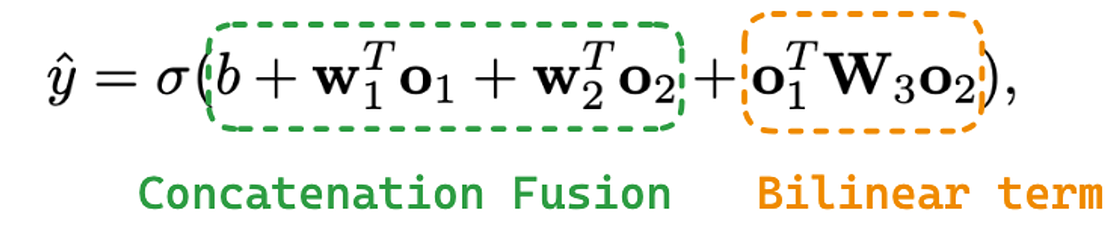
where σ is a sigmoid function, b is the bias term, and o1 is the output from one stream. w1 is a learnable weight to be applied to o1, o2 is the output from the other stream, and w2 is a learnable weight to be applied to o2. Finally*, w3* is the learnable matrix in the bilinear term that extracts feature interaction information. If w3 is set to a zero matrix, it degenerates to the traditional concatenation fusion.
The difference between Bilinear Fusion and Multi-Head Bilinear Fusion is that, instead of applying the bilinear fusion using the whole vector from both streams, it chunks the outputs o1 and o2 into k subspaces. The bilinear fusion is performed in each subspace, aggregating to feed the sigmoid function to produce the final probability.

Creating a Book Recommender model with FinalMLP
In this section, we will implement FinalMLP on a public dataset from Kaggle under the License CC0: Public Domain. This dataset contains information about the user, the book, and the rating the user gives to the book.
The dataset is composed of the following:
User-ID— identifies a userLocation— comma-separated string with the city, state, and country of the userAge— user’s ageISBN— book identifiersBook-Rating— user’s rating for a specific bookBook-Title— title of the bookBook-Author— author of the bookYear-of-Publication— the year when the book was publishedPublisher— The editor who published the book
We will rank the books based on their relevance for each user. After that, we use Normalized Discounted Cumulative Gain (nDCG) to compare our ranking with the actual ranking (sorting the books based on the rating given by the user).
nDCG is a metric for evaluating the quality of recommendation systems by measuring the ranking of results based on their relevance. It considers the relevance of each item and its position in the result list, giving more importance to higher ranks. nDCG is calculated by comparing the Discounted Cumulative Gain (DCG), which discounts gains of lower-ranked items, to the ideal DCG (iDCG), the highest possible DCG given a perfect ranking. This normalized score ranges between 0 and 1, where 1 represents the ideal ranking order. Thus, nDCG gives us a way to understand how effectively a system presents relevant information to users.
We start by importing the libraries:
%matplotlib inline
%load_ext autoreload
%autoreload 2
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import random
from sklearn.metrics import ndcg_score
from sklearn.decomposition import PCA
from sentence_transformers import SentenceTransformer
import os
import logging
from fuxictr.utils import load_config, set_logger, print_to_json
from fuxictr.features import FeatureMap
from fuxictr.pytorch.torch_utils import seed_everything
from fuxictr.pytorch.dataloaders import H5DataLoader
from fuxictr.preprocess import FeatureProcessor, build_dataset
import src
import gc
import os
Then, we load the three datasets and merge them into a single dataset:
books_df = pd.read_csv('data/book/Books.csv')
users_df = pd.read_csv('data/book/Users.csv')
ratings_df = pd.read_csv('data/book/Ratings.csv')
df = pd.merge(users_df, ratings_df, on='User-ID', how='left')
df = pd.merge(df, books_df, on='ISBN', how='left')After that, we perform some exploratory data analysis to identify issues with the data:
1. Remove observations where the user did not rate the book.
df = df[df['Book-Rating'].notnull()]
2. Check missing values and replace missing Book-Author and Publisher with unknown category.
print(df.columns[df.isna().any()].tolist())
df['Book-Author'] = df['Book-Author'].fillna('unknown')
df['Publisher'] = df['Publisher'].fillna('unknown')
3. Remove observations with missing information about the book.
df = df[df['Book-Title'].notnull()]
4. Replace non-integer Year-of-Publication with null values.
df['Year-Of-Publication'] = pd.to_numeric(df['Year-Of-Publication'], errors='coerce')
5. Check Age, Year-of-Publication and Book-Rating distributions to identify anomalies.
plt.rcParams["figure.figsize"] = (20,3)
sns.histplot(data=df, x='Age')
plt.title('Age Distribution')
plt.show()
sns.histplot(data=df, x='Year-Of-Publication')
plt.title('Year-Of-Publication Distribution')
plt.show()
sns.histplot(data=df, x='Book-Rating')
plt.title('Book-Rating Distribution')
plt.show()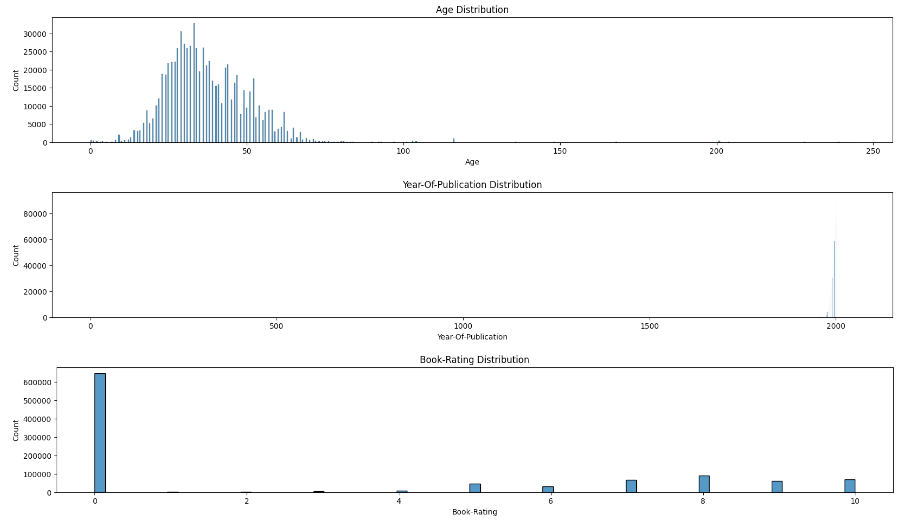
Finally, we clean up the data by:
- Replacing
age > 100(which seems an error) with missing values to be handled later. - Limiting the upper bound to 2021 because it was when the dataset was published in Kaggle and replacing
Year-of-Publication <= 0with missing values to be handled later. - Removing observations with
rating = 0, since those books were read by the user but not rated. - Creating 3 new features (
city,state,country) fromLocation. Since, city is too noisy, we will not use it. - Create a binary label for FinalMLP where we consider books with a rate higher than 7 relevant for the user.
df['Age'] = np.where(df['Age'] > 100, None, df['Age'])
df['Year-Of-Publication'] = np.where(df['Year-Of-Publication'].clip(0, 2021) <= 0, None, df['Year-Of-Publication'])
df = df[df['Book-Rating'] > 0]
df['city'] = df['Location'].apply(lambda x: x.split(',')[0].strip()) # too noisy, we will not use
df['state'] = df['Location'].apply(lambda x: x.split(',')[1].strip())
df['country'] = df['Location'].apply(lambda x: x.split(',')[2].strip())
df['label'] = (df['Book-Rating'] > 7)*1
With the dataset cleaned, we split the data into train, validation, and test by randomly selecting 70% of the users for training, 10% for validation, and 20% for testing.
# create list with unique users
users = df['User-ID'].unique()
# shuffle list
random.shuffle(users)
# create list of users to train, to validate and to test
train_users = users[:int(0.7*len(users))]
val_users = users[int(0.7*len(users)):int(0.8*len(users))]
test_users = users[int(0.8*len(users)):]
# train, val and test df
train_df = df[df['User-ID'].isin(train_users)]
val_df = df[df['User-ID'].isin(val_users)]
test_df = df[df['User-ID'].isin(test_users)]Before feeding the data into the model, we will apply some pre-processing to the data:
We create embeddings using a multilingual encoder for the textual feature Book-Title, and we reduce the dimensionality using PCA with 80% of the variance explained.
We use a multilingual encoder because the title is written in different languages. Note that we extract distinct Book-Title first in order to not bias the dimensionality reduction if a book was read by more users than another book.
# create embeddings
train_embeddings = utils.create_embeddings(train_df.copy(), "Book-Title")
val_embeddings = utils.create_embeddings(val_df.copy(), "Book-Title")
test_embeddings = utils.create_embeddings(test_df.copy(), "Book-Title")
# reduce dimensionality with PCA
train_embeddings, pca = utils.reduce_dimensionality(train_embeddings, 0.8)
val_embeddings = pca.transform(val_embeddings)
test_embeddings = pca.transform(test_embeddings)
# join embeddings to dataframes
train_df = utils.add_embeddings_to_df(train_df, train_embeddings, "Book-Title")
val_df = utils.add_embeddings_to_df(val_df, val_embeddings, "Book-Title")
test_df = utils.add_embeddings_to_df(test_df, test_embeddings, "Book-Title")
We fill missing values of numerical features with median values and normalize the data using MinMaxScaler.
# set numerical columns
NUMERICAL_COLUMNS = [i for i in train_df.columns if "Book-Title_" in i] + ['Age', 'Year-Of-Publication']
# define preprocessing pipeline and transform data
pipe = utils.define_pipeline(NUMERICAL_COLUMNS)
train_df[NUMERICAL_COLUMNS] = pipe.fit_transform(train_df[NUMERICAL_COLUMNS])
val_df[NUMERICAL_COLUMNS] = pipe.transform(val_df[NUMERICAL_COLUMNS])
test_df[NUMERICAL_COLUMNS] = pipe.transform(test_df[NUMERICAL_COLUMNS])With all the data ready to be fed to FinalMLP, we must create two yaml config files: dataset_config.yaml and model_config.yaml.
dataset_config.yaml is responsible for defining what features will be used in the model. Also, it defines their data type (they are handled differently in the Embedding layer) and the paths to the training, validation, and test sets. You can see the main parts of the configuration file below:
FinalMLP_book:
data_root: ./data/book/
feature_cols:
- active: true
dtype: float
name: [Age, Book-Title_0, Book-Title_1, Book-Title_2, Book-Title_3, Book-Title_4, Book-Title_5, Book-Title_6, Book-Title_7,
Book-Title_8, ...]
type: numeric
- active: true
dtype: str
name: [Book-Author, Year-Of-Publication, Publisher, state, country]
type: categorical
fill_na: unknown
label_col: {dtype: float, name: label}
min_categr_count: 1
test_data: ./data/book/test.csv
train_data: ./data/book/train.csv
valid_data: ./data/book/valid.csvmodel_config.yaml is responsible for setting the hyperparameters of the model. You also have to define what stream will handle user features and what stream will handle item features. The file should be defined as follows:
FinalMLP_book:
dataset_id: FinalMLP_book
fs1_context: [Age, state, country]
fs2_context: [Book-Author, Year-Of-Publication, Publisher, Book-Title_0, Book-Title_1, Book-Title_2, Book-Title_3,
Book-Title_4, Book-Title_5, ...]
model_root: ./checkpoints/FinalMLP_book/
We go back to Python and load the recently created configuration files. Then, we create feature mappings (i.e., how many categories do we have in each categorical feature, how should it replace missing values in the different features if they exist, etc). We convert the CSVs into h5 files.
# Get model and dataset configurations
experiment_id = 'FinalMLP_book'
params = load_config(f"config/{experiment_id}/", experiment_id)
params['gpu'] = -1 # cpu
set_logger(params)
logging.info("Params: " + print_to_json(params))
seed_everything(seed=params['seed'])
# Create Feature Mapping and convert data into h5 format
data_dir = os.path.join(params['data_root'], params['dataset_id'])
feature_map_json = os.path.join(data_dir, "feature_map.json")
if params["data_format"] == "csv":
# Build feature_map and transform h5 data
feature_encoder = FeatureProcessor(**params)
params["train_data"], params["valid_data"], params["test_data"] = \\
build_dataset(feature_encoder, **params)
feature_map = FeatureMap(params['dataset_id'], data_dir)
feature_map.load(feature_map_json, params)
logging.info("Feature specs: " + print_to_json(feature_map.features))After that, we can start the training process of our model.
model_class = getattr(src, params['model'])
model = model_class(feature_map, **params)
model.count_parameters() # print number of parameters used in model
train_gen, valid_gen = H5DataLoader(feature_map, stage='train', **params).make_iterator()
model.fit(train_gen, validation_data=valid_gen, **params)
Finally, we can predict unseen data; we just need to change the batch size to 1 to score all observations.
# to score all observations
params['batch_size'] = 1
test_gen = H5DataLoader(feature_map, stage='test', **params).make_iterator()
test_df['score'] = model.predict(test_gen)
We chose a customer with more than one book rated and different ratings for each book to enable a proper rank without ties. Its nDCG score was 0.986362 since we have misplaced 2 books with a distance of 1 position.
We also used Recall to evaluate FinalMLP. Recall is a metric measuring the ability of a system to identify all relevant items from a set, represented as the fraction of relevant items retrieved out of the total relevant items available. When we specify Recall@K, such as Recall@3, we focus on the system’s ability to identify relevant items within the top K recommendations. This adaptation is crucial for evaluating recommendation systems where users primarily focus on the top recommendations. The selection of K (e.g., 3) depends on typical user behavior and the application’s context.
If we look at Recall@3 for this customer, we have 100% since the three more relevant books were placed in the top 3 positions.
true_relevance = np.asarray([test_df[test_df['User-ID'] == 1113]['Book-Rating'].tolist()])
y_relevance = np.asarray([test_df[test_df['User-ID'] == 1113]['score'].tolist()])
ndcg_score(true_relevance, y_relevance)
We also calculated the nDCG score for the remaining test set and compared the FinalMLP performance against the CatBoost Ranker, as shown in Figure 7. Although both models performed quite well, FinalMLP for this test set performed slightly better, with an average nDCG per user of 0.963298 while CatBoost Ranker ‘only’ achieved 0.959977.

In terms of interpretability, this model performs feature selection, which allows us to extract the weighting vectors. However, it is not straightforward to interpret and understand the importance of each feature. Note that after the embedding layer, we end up with a 930-dimensional vector, making it harder to map it back to the original features. Nevertheless, we can try to understand the importance of each stream by extracting the absolute value of the output of each stream after the linear processing given by the linear terms mentioned previously and shown in Equation 2.
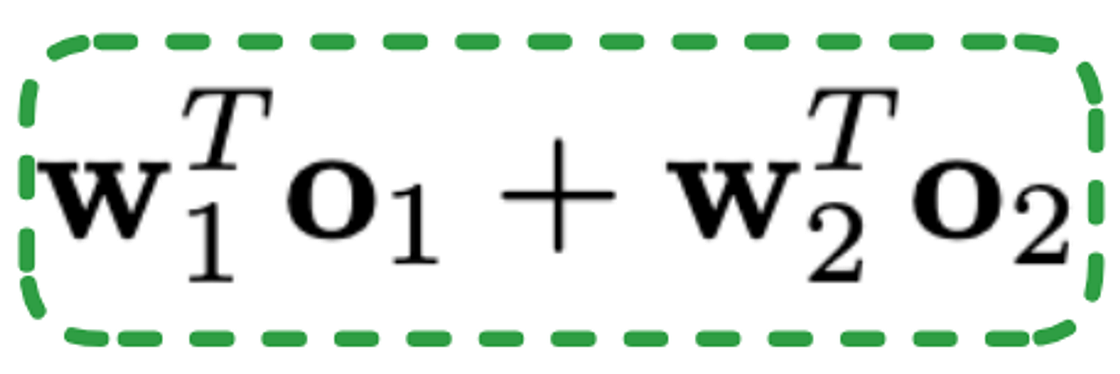
For that, we need to change the InteractionAggregation module and add the following lines of code to extract the linear transformed values after each step:
...
self.x_importance = []
self.y_importance = []
def forward(self, x, y):
self.x_importance.append(torch.sum(torch.abs(self.w_x(x))))
self.y_importance.append(torch.sum(torch.abs(self.w_y(y))))
...
Once trained, we can predict and plot the absolute values resulting from the linear transformation of each stream. As shown in Figure 8, the Item Stream has more importance than the User Stream. This happens because we have many more features about the item but also due to the user features being quite general.

Conclusion
Recommendation systems enhance user experience by providing personalized recommendations and empowering organizations to make data-driven decisions that drive growth and innovation.
In this article, we presented one of the most recent models developed for recommendation systems. FinalMLP is a deep learning model with two independent networks. Each network focuses its learning on one of the two different perspectives: the user and the item. The different patterns learned from each network are then fed to a fusion layer that is responsible for combining the learnings of each network. It creates a single view of the user-item pair interaction to produce the final score. The model performed well in our use case, beating the CatBoost Ranker.
Note that the selection of the algorithm might depend on the problem that you are trying to solve and your dataset. It is always good practice to test several methods against each other. You can also consider testing xDeepFM, AutoInt, DHEN, or DLRM.
About me
Serial entrepreneur and leader in the AI space. I develop AI products for businesses and invest in AI-focused startups.
References
[1] Kelong Mao, Jieming Zhu, Liangcai Su, Guohao Cai, Yuru Li, Zhenhua Dong. FinalMLP: An Enhanced Two-Stream MLP Model for CTR Prediction. arXiv:2304.00902, 2023.
[2] Jiajun Fei, Ziyu Zhu, Wenlei Liu, Zhidong Deng, Mingyang Li, Huanjun Deng, Shuo Zhang. DuMLP-Pin: A Dual-MLP-dot-product Permutation-invariant Network for Set Feature Extraction. arXiv:2203.04007, 2022.
[3] Jieming Zhu, Jinyang Liu, Shuai Yang, Qi Zhang, Xiuqiang He. BARS-CTR: Open Benchmarking for Click-Through Rate Prediction. arXiv:2009.05794, 2020.
More articles: https://zaai.ai/lab/