

Chronos: The Rise of Foundation Models for Time Series Forecasting
Exploring Chronos: How foundational AI models are setting new standards in predictive analytics
This article was co-authored by Luís Roque and Rafael GuedesIntroduction
Time series forecasting has been evolving towards foundation models due to their success in other artificial intelligence (AI) areas. Particularly, we have been witnessing the success of such approaches in natural language processing (NLP). The cadence of the development of foundational models has been accelerating over time. A new, more powerful Large Language Model (LLM) is released every month. This is not restricted to NLP. We see a similar growing pattern in computer vision as well. Segmentation models like Meta’s Segment Anything Model (SAM) [1] can identify and accurately segment objects in unseen images. Multimodal models such as LLaVa [2] or Qwen-VL [3] can handle text and images to answer any user question. The common characteristic between these models is that they can perform accurate zero-shot inference, meaning that they do not need to be trained in your data to have an excellent performance.
Defining what a foundational model is and what makes it different from traditional approaches is probably beneficial at this point. First, a foundational model is large-scale (namely its training), which provides a broad understanding of the main patterns and important nuances we can find in the data. Secondly, it is general-purpose, i.e., the foundational model can perform various tasks without requiring task-specific training. Even though they don’t need task-specific training, they can be fine-tuned (also known as transfer learning). They are adaptable with relatively small datasets to perform better at that specific task.
Why is applying it to time series forecasting so tempting based on the above? Foremost, we design foundational models in NLP to understand and generate text sequences. Luckily, time series data are also sequential. The previous point also aligns with the fact that both problems require the model to automatically extract and learn relevant features from the sequence of the data (temporal dynamics in time series data). Additionally, the general-purpose nature of foundational models means we can adapt them to different forecasting tasks. This flexibility allows for applying a single, powerful model across various domains and forecasting challenges. Moreover, we can then fine-tune them for that specific domain and application.
TimeGPT [4] was one of the first foundation models developed for forecasting by Nixtla. Following it, other companies entered the race and developed new models, such as MOIRAI [5] from Salesforce, Lag-Llama [6], or TimesFM [7] from Google. More recently, Amazon joined them and developed Chronos [8], a foundational model for time series based on language model architectures.
In this article, we provide an in-depth explanation of the architecture behind Chronos. We also cover the main components that allow the model to perform zero-shot inference. Following this theoretical overview, we apply Chronos to a specific use case and dataset. We cover the practical implementation details and thoroughly analyze the model’s performance. Finally, we compare the performance of Chronos (tiny and large versions) with TiDE for a public dataset.
We show that Chronos is able to beat TiDE [9] in zero-shot inference for the public dataset. Moreover, we need to take into consideration that it performed zero-shot inference without any type of fine-tuning. The improvement Chronos brings to foundation models is unquestionable (you can check our previous article where we did an in-depth analysis of TimeGPT ). Also, we provide evidence that the difference between the tiny and large versions of Chronos is not significant.
As always, the code is available on our GitHub.
Chronos: Learning the Language of Time Series by Amazon
Chronos is Amazon’s most recent foundation model for time series forecasting. It consists of a probabilistic model that uses a T5 (Text-to-Text Transfer Transformer) architecture [10] to forecast future patterns.
The T5 family of models is a series of language models developed by Google. T5 approaches every NLP task as a text-to-text problem, unlike traditional models designed for specific NLP tasks such as text classification, machine translation, or text summarization. T5 is built upon the transformer architecture based on the encoder-decoder model [11]. In the context of T5, both the encoder and the decoder are made up of transformer blocks that process the input text into a continuous representation, which the decoder then uses to generate output text token by token.
The T5 model family includes several variants with different sizes. It ranges from smaller models with fewer parameters designed to be more efficient and applicable to resource-constrained environments to larger models with more parameters capable of capturing more complex patterns and nuances in the data.
The logic that led the authors of Chronos to use an approach based on T5 was thinking about the fundamental differences between an LLM that predicts the next token in a sequence and a time series model that predicts the next value in a sequence. As we discussed in the introduction, they are very similar in nature. The main difference relies on the fact that, in the LLM case, we have a finite dictionary of words that we can predict. Conversely, we have an unbounded set of continuous values in the time series case. Nevertheless, both models use the sequential structure of the data to predict future values. Therefore, the relevant question is: can we transform and make our continuous values discrete?
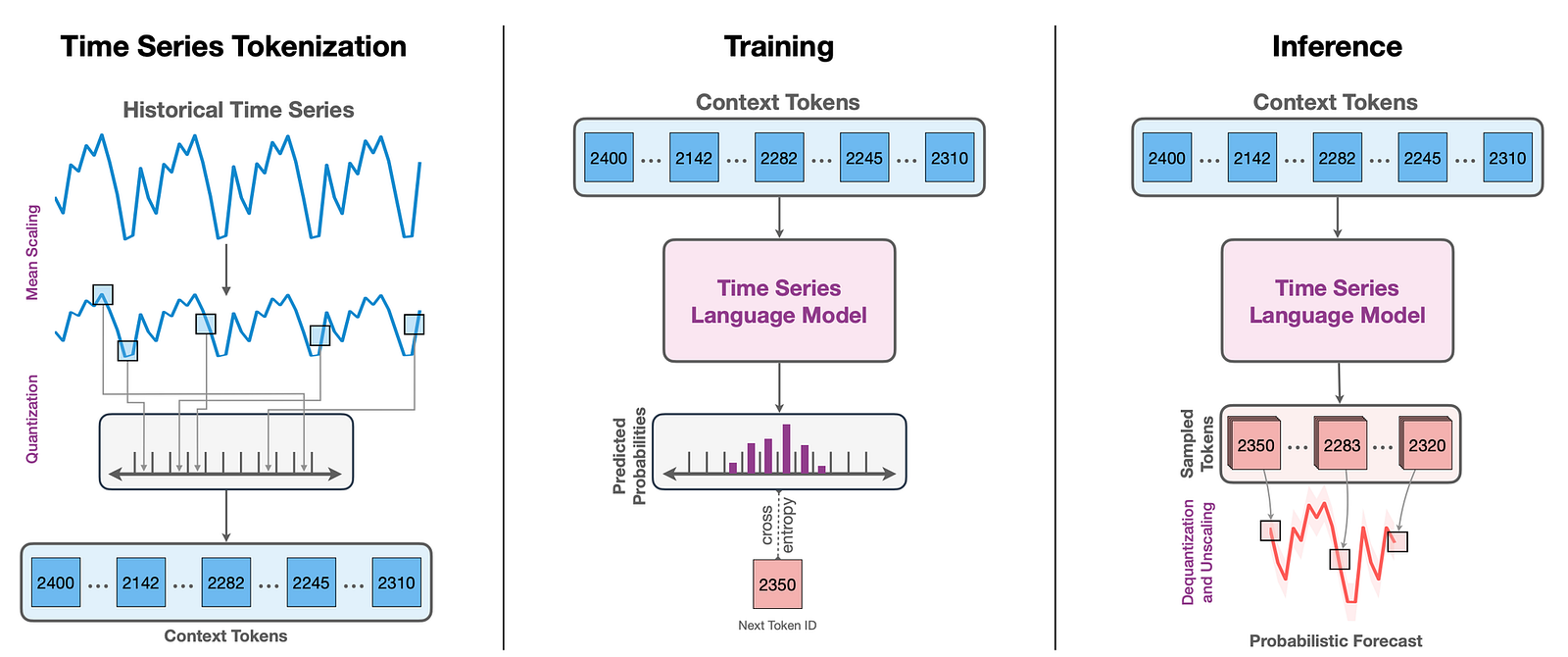
Adapting an LLM for Time Series Forecasting
Pre-Processing steps
As we mentioned before, the major difference between LLMs and forecasting models is that LLMs expect to handle a finite number of tokens. Therefore, we need to transform the unbounded set of continuous values, typical of time series data, into a finite set of tokens. This tokenization process requires 3 steps:
1.Scaling will be responsible for mapping the input data into a useful range of values to be the Quantization step (explained later). Contrary to its usual goal of facilitating the optimization of deep learning models, scaling helps us create the input tokens. The authors used mean scaling, which normalizes the input values based on the mean of the absolute values from a pre-defined context length of historical values.

2. Quantization is responsible for converting the scaled continuous values into discrete tokens through binning. The authors used uniform binning, which groups all values within a specific range to the same bin or, in other words, to the same token. In Figure 3, for simplicity, we used 4 different bins. In fact, the model uses 4096 different bins.
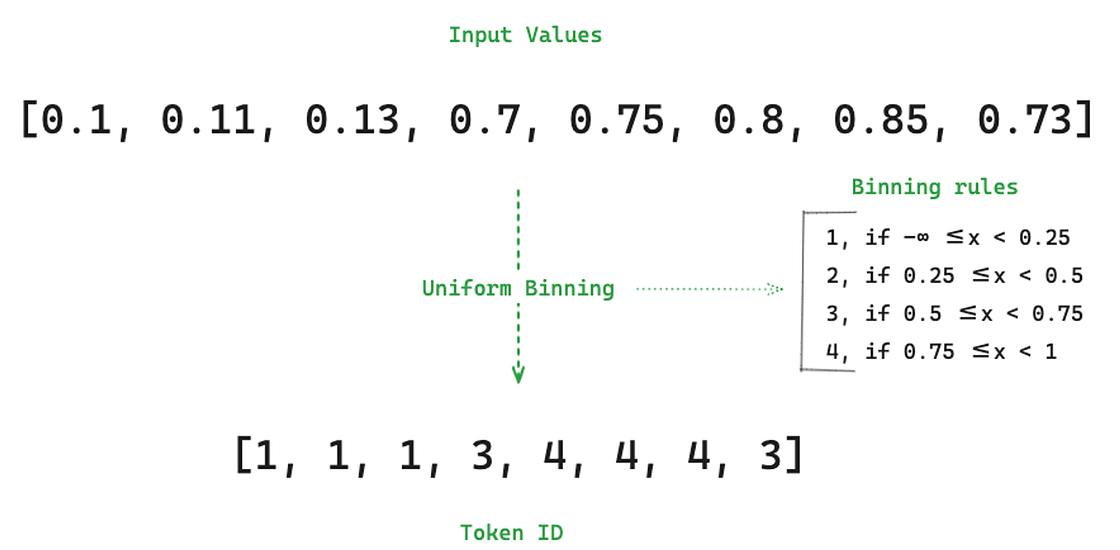
Uniform binning has a strong limitation, and therefore, we discuss some alternatives next. It suffers from the same problem as decision trees when used for time series forecasting. It cannot predict values that are outside the range of the target variable in the training set.
Another possible approach is to use quantile binning. This creates bins with the same number of samples. Nevertheless, it has its own limitations. Since it strongly assumes the distribution of values from unseen can increase the heterogeneity between the training and prediction data.
3. The authors added Special Language Tokens to represent the end of the sequence (EOS). Another interesting approach was to treat missing values using a special token (PAD). These missing values could be due to a missing observation or padding. Padding is often used to create training batches by transforming time series with different lengths to a universal fixed length.
Training Strategy
Chronos uses the same loss function as any other language model — cross-entropy. It performs regression via classification and is trained to minimize the difference between the predicted and the ground truth distribution. However, cross-entropy does not have a sense of distance, which is crucial in time series data. Two consecutive values are usually more correlated than two nonconsecutive values, and their correlation tends to decrease as they are separated further in time (also known as autocorrelation). Therefore, the model is expected to learn how to associate nearby bins together based on the distribution of bin indices in the training dataset.
The authors decided to keep the same loss function as language models because it does not require any modification to the language model architecture. This makes it easier to change the backbone architecture to use other LLMs (e.g., Mixtral [12], Llama2 [13]) and their respective utilities. It also allows the model not to be limited to assuming any specific shape for the output distribution (e.g., normal distribution). Instead, it can learn to predict future values that follow any type of distribution present in the training data.
Inference
Typically, an LLM can generate a sample of token IDs as a prediction. Therefore, to obtain a probabilistic forecast, the authors draw several samples for each step in the forecast horizon. After that, they need to reverse the quantization and scaling operations performed in the pre-processing steps to feed the language model.
Considering 4 samples drawn for t+1, firstly, they perform dequantization by mapping back the token ID to the scaled value, which is the value in the center of the interval:

Then, they unscale the values by multiplying them by the average absolute value of the context length that precedes it:

Finally, the final forecast interval is generated by taking different quantiles from the sample, e.g., Q10 for the lower bound, Q50 for the mid-value, and Q90 for the upper bound:

Other important remarks
The authors chose to use the T5 architecture since it is available in different sizes, ranging from 16M (Tiny) to 11B (XXL) parameters. However, they reduced the vocabulary size from 32,128 to 4,096, resulting in fewer parameters (ranging from 8M to 710M models — quite small compared to the NLP counterparts). They also tested GPT-2 to highlight that, following their approach, any language model can be used as a replacement for T5.
The model does not allow external information such as static (product brand, color, etc.) or dynamic (product price, macroeconomic data, etc.) covariates. Also, it treats each time series as a simple sequence without time or frequency information (hourly, daily, weekly, or monthly data), which might become a disadvantage when modeling seasonality. Another limitation is the fact that it is a univariate model only. Additionally, it can only forecast one time series at a time, which does not allow for modeling dependencies between time series.
As in other time series foundation models like TimeGPT, zero-shot inference is achieved by training the model in datasets from various domains and frequencies. Namely, the authors used datasets from domains such as energy, transport, healthcare, retail, web, weather, and finance.
Comparing Chronos vs. TiDE
In this section, we will use Chronos to forecast tourism visitors to Australia using a real-world dataset that is publicly available under the cc-by-4.0 license. Subsequently, we compare the forecasting performance of Chronos (tiny and large versions) with TiDE, using its implementation from the Python library Darts.
We enhanced the dataset with economic covariates (e.g., CPI, Inflation Rate, GDP) extracted from Trading Economics, which uses economic indicators based on official sources. We also perform some preprocessing to further increase the usability of the dataset. The final structure of the dataset is the following:
- Unique ID: A combination of encoded names for States, Zones, Regions within Australia, and the purpose of the visit (e.g., business, holiday, visiting, other).
- Time: Represents the time dimension of the dataset, dynamically adjusted for each series.
- Target: The target variable for forecasting, specifically focusing on visits.
- Dynamic Covariates: Economic indicators such as CPI, Inflation Rate, and GDP that vary over time.
- Static Covariates (Static_1 to Static_4): Extracted from the unique ID, these provide additional information for analysis, including geographic and purpose-of-visit details.
We stored the new version of the dataset here so that our experiments can be easily reproduced.
We start by importing the libraries and setting global variables. We set the date column, target column, static covariates, dynamic covariates to fill with 0, dynamic covariates to fill with linear interpolation, the frequency of our series, the forecast horizon, and the scalers to use.
%load_ext autoreload %autoreload 2 import numpy as np import pandas as pd import torch import utils from datetime import timedelta from chronos import ChronosPipeline from darts import TimeSeries from darts.dataprocessing.pipeline import Pipeline from darts.models import TiDEModel from darts.dataprocessing.transformers import Scaler from darts.utils.timeseries_generation import datetime_attribute_timeseries from darts.utils.likelihood_models import QuantileRegression from darts.dataprocessing.transformers import StaticCovariatesTransformer, MissingValuesFiller TIME_COL = "Date" TARGET = "visits" STATIC_COV = ["static_1", "static_2", "static_3", "static_4"] DYNAMIC_COV = ['CPI', 'Inflation_Rate', 'GDP'] FREQ = "MS" FORECAST_HORIZON = 8 # months SCALER = Scaler() TRANSFORMER = StaticCovariatesTransformer() PIPELINE = Pipeline([SCALER, TRANSFORMER])After that, we load our dataset and enrich it with those exogenous features as mentioned in the dataset description:
# load data and exogenous features
df = pd.read_csv('data/data.csv', parse_dates=['Date']).drop(columns=['Year', 'Month']).set_index('Date')
df = utils.preprocess_dataset(df, DYNAMIC_COV, TIME_COL, TARGET)
print(f"Distinct number of time series: {len(df['unique_id'].unique())}")
df.head()
Distinct number of time series: 304
Once the dataset is loaded, we can split the data between train and test (we decided to use the last 8 months of data for our test set). And transform the pandas' data frame into Darts TimeSeries format.
- Using the function TimeSeries.from_group_dataframe, we can easily define the static covariates, our target, the column with the time reference, and the frequency of the series.
- We also used the fill_missing_dates argument to fill the target variable with 0 in case some of our series have a gap between weeks.
# 8 months to test
train = df[df[TIME_COL] <= (max(df[TIME_COL])-pd.DateOffset(months=FORECAST_HORIZON))]
test = df[df[TIME_COL] > (max(df[TIME_COL])-pd.DateOffset(months=FORECAST_HORIZON))]
# read train and test datasets and transform train dataset
train_darts = TimeSeries.from_group_dataframe(
df=train,
group_cols=STATIC_COV,
time_col=TIME_COL,
value_cols=TARGET,
freq=FREQ,
fill_missing_dates=True,
fillna_value=0)
# since we have several time series not all of them have the same number of weeks in the forecast set
print(f"Weeks for training: {len(train[TIME_COL].unique())} from {min(train[TIME_COL]).date()} to {max(train[TIME_COL]).date()}")
print(f"Weeks for testing: {len(test[TIME_COL].unique())} from {min(test[TIME_COL]).date()} to {max(test[TIME_COL]).date()}")
Months for training: 220 from 1998–01–01 to 2016–04–01 Months for testing: 8 from 2016–05–01 to 2016–12–01
We have the historical data in a TimeSeries format, so now it is time to create the dynamic covariates in the same format.
# create dynamic covariates for each serie in the training darts
dynamic_covariates = []
for serie in train_darts:
# add the month and week as a covariate
covariate = datetime_attribute_timeseries(
serie,
attribute="month",
one_hot=True,
cyclic=False,
add_length=FORECAST_HORIZON,
)
static_1 = serie.static_covariates['static_1'].item()
static_2 = serie.static_covariates['static_2'].item()
static_3 = serie.static_covariates['static_3'].item()
static_4 = serie.static_covariates['static_4'].item()
# create covariates to fill with interpolation
dyn_cov_interp = TimeSeries.from_dataframe(df[(df['static_1'] == static_1) & (df['static_2'] == static_2) & (df['static_3'] == static_3) & (df['static_4'] == static_4)], time_col=TIME_COL, value_cols=DYNAMIC_COV, freq=FREQ, fill_missing_dates=True)
covariate = covariate.stack(MissingValuesFiller().transform(dyn_cov_interp))
dynamic_covariates.append(covariate)
Weeks for training: 126 from 2010–02–05 to 2012–06–29
Weeks for testing: 17 from 2012–07–06 to 2012–10–26
After splitting the data and creating the covariates, we can forecast the 304 series using TiDE:
# scale covariates
dynamic_covariates_transformed = SCALER.fit_transform(dynamic_covariates)
# scale data and transform static covariates
data_transformed = PIPELINE.fit_transform(train_darts)
TiDE_params = {
"input_chunk_length": 12, # number of months to lookback
"output_chunk_length": FORECAST_HORIZON,
"num_encoder_layers": 2,
"num_decoder_layers": 2,
"decoder_output_dim": 1,
"hidden_size": 15,
"temporal_width_past": 4,
"temporal_width_future": 4,
"temporal_decoder_hidden": 26,
"dropout": 0.1,
"batch_size": 16,
"n_epochs": 15,
"likelihood": QuantileRegression(quantiles=[0.25, 0.5, 0.75]),
"random_state": 42,
"use_static_covariates": True,
"optimizer_kwargs": {"lr": 1e-3},
"use_reversible_instance_norm": False,
}
model = TiDEModel(**TiDE_params)
model.fit(data_transformed, future_covariates=dynamic_covariates_transformed, verbose=False)
pred = SCALER.inverse_transform(model.predict(n=FORECAST_HORIZON, series=data_transformed, future_covariates=dynamic_covariates_transformed, num_samples=50))
tide_forecast = utils.transform_predictions_to_pandas(pred, TARGET, train_darts, [0.25, 0.5, 0.75])
Once the forecast has finished, we will use the same data to forecast with Chronos. Since Chronos is not a multivariate time series model, we need to forecast each series individually. First, we load both models, the tiny and the large version, and we loop over the 304 series available in the dataset.
# load model
pipeline_tiny = ChronosPipeline.from_pretrained(
"amazon/chronos-t5-tiny",
device_map="cuda",
torch_dtype=torch.bfloat16,
)
pipeline_large = ChronosPipeline.from_pretrained(
"amazon/chronos-t5-large",
device_map="cuda",
torch_dtype=torch.bfloat16,
)
# run forecast
forecast_tiny = []
forecast_large = []
for ts in train_darts:
# tiny
lower, mid, upper = utils.chronos_forecast(pipeline_tiny, ts.pd_dataframe().reset_index(), FORECAST_HORIZON, TARGET)
forecast_tiny.append(utils.convert_forecast_to_pandas([lower, mid, upper], test[test['unique_id'] == list(ts.static_covariates_values())[0][0]+list(ts.static_covariates_values())[0][1]+list(ts.static_covariates_values())[0][2]+list(ts.static_covariates_values())[0][3]]))
# large
lower, mid, upper = utils.chronos_forecast(pipeline_large, ts.pd_dataframe().reset_index(), FORECAST_HORIZON, TARGET)
forecast_large.append(utils.convert_forecast_to_pandas([lower, mid, upper], test[test['unique_id'] == list(ts.static_covariates_values())[0][0]+list(ts.static_covariates_values())[0][1]+list(ts.static_covariates_values())[0][2]+list(ts.static_covariates_values())[0][3]]))
# convert list to data frames
forecast_tiny = pd.concat(forecast_tiny)
forecast_large = pd.concat(forecast_large)
Once the forecast has finished, we can plot the ground truth values and the predictions. We decided to check the top 3 series in terms of volume:
# get series ordered by volume in a descending way
series = test.groupby('unique_id')[TARGET].sum().reset_index().sort_values(by=TARGET, ascending=False)['unique_id'].tolist()
for ts in series[:3]:
utils.plot_actuals_forecast(df[df["unique_id"]==ts], forecast_tiny[forecast_tiny["unique_id"] == ts], ts)
utils.plot_actuals_forecast(df[df["unique_id"]==ts], forecast_large[forecast_large["unique_id"] == ts], ts)
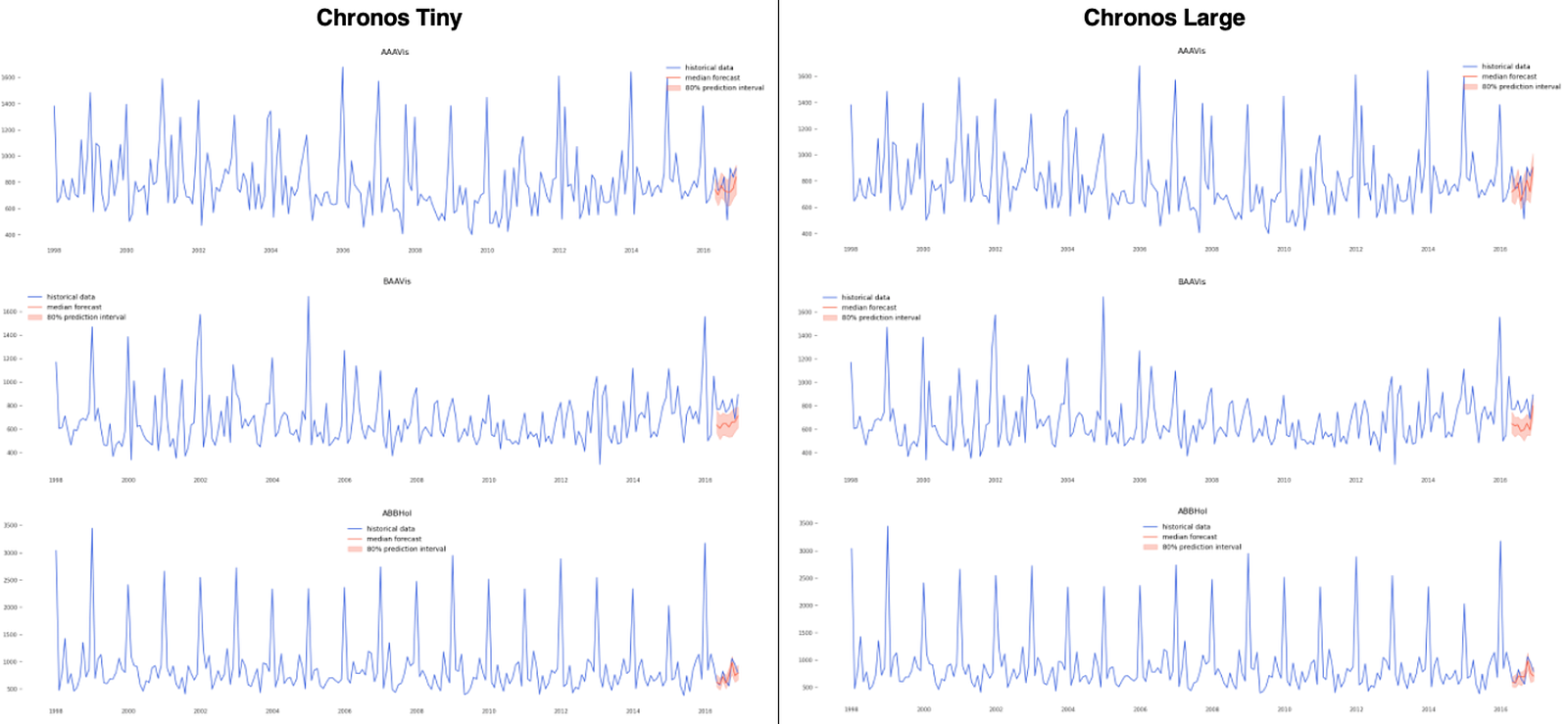
Figure 7 shows that there are no significant differences between the large and tiny versions of Chronos. The
results
are impressive for both variants for ABBHol where they manage to capture perfectly the
seasonality of
the data and the time of peaks and drops without any external information.
Having obtained the forecast from Chronos, we can now load the forecast generated by TiDE and compute forecasting performance metrics for comparison. For better interpretability, we have used the Mean Absolute Percentage Error (MAPE) as our comparison metric.
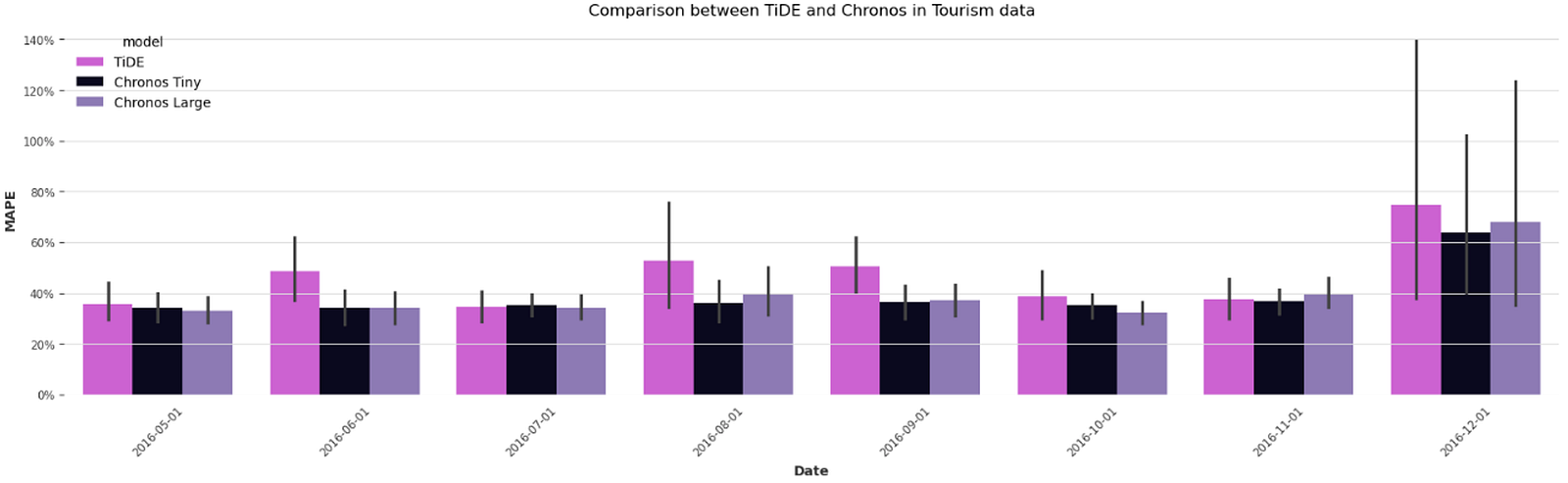
As shown in Figure 8, Chronos Large beat TiDE in 6 out of the 8 months. TiDE also had a higher MAPE for 7 out of 8 months for the top 100 time series than the Tiny version of Chronos. Although we did not perform any kind of hyperparameter tuning for TiDE, it is still impressive that Chronos, in a zero-shot inference setting, managed to have better results than a powerful model like TiDE trained specifically on this dataset.
Chronos vs. TimeGPT vs. TiDE: a comparison in a real use case
In this section, we use Chronos to forecast sales using a real-world dataset from one of our clients. Subsequently, we compare the forecasting performance of Chronos (tiny and large versions) with TimeGPT and TiDE, using the same cutoff date for analysis.
The dataset contains 195 unique time series, each detailing weekly sales data specifically for the United States market. In addition to historical sales data, the dataset has information on two types of marketing events. We incorporate US public holidays and binary seasonal features to augment the dataset, in this case, week and month identifiers. The forecasting horizon is 17 weeks, i.e., we want to predict 17 weeks into the future.
The code used is the same as in the previous section. Figure 9 shows that the tiny version of Chronos cannot predict the drops as well as the large version. However, Chronos Large is surprisingly good at accurately predicting which weeks we should expect a drop and the magnitude of the respective drop. Remember that the predictions are generated only based on historical information and without external features such as public holidays.
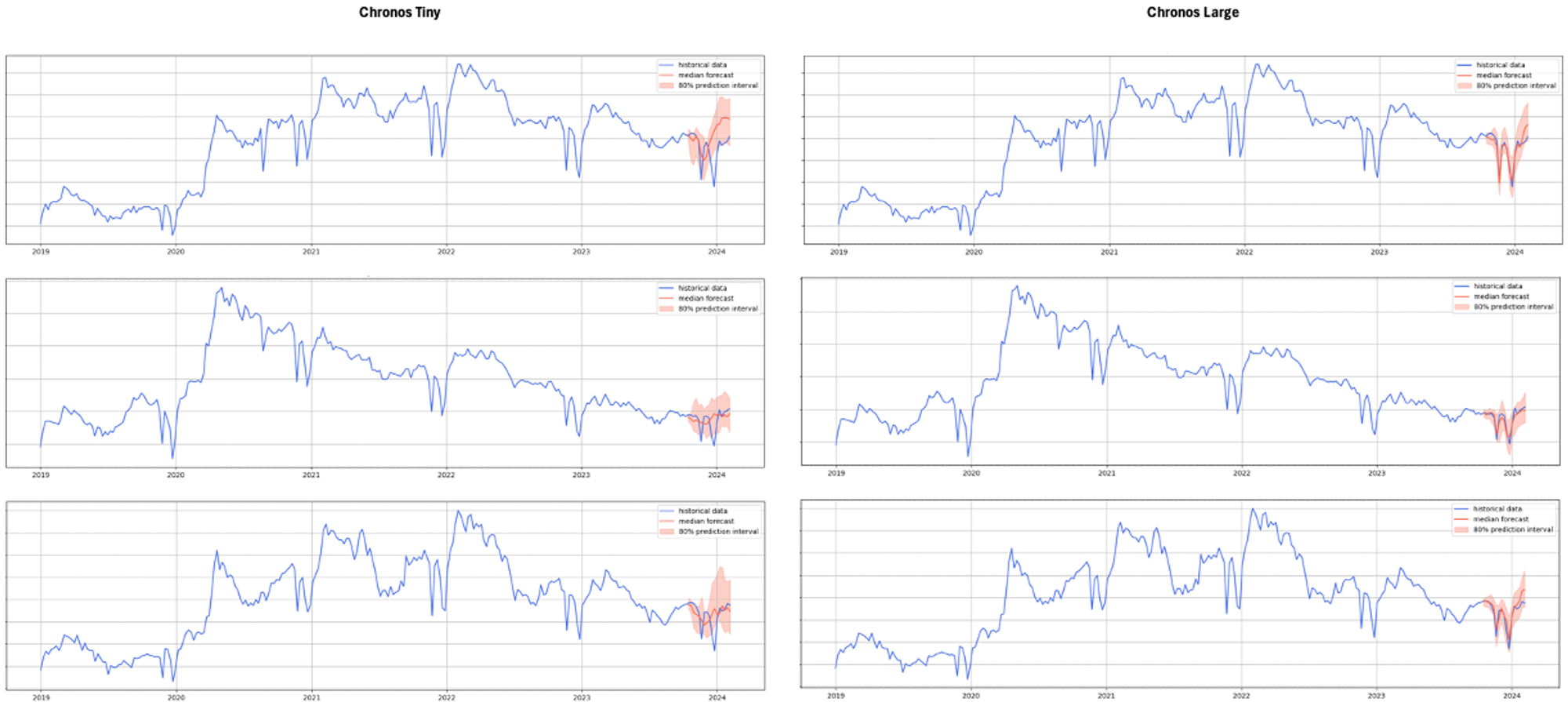
As shown in Figure 9, Chronos Large beat TiDE in 6 out of the 8 months. TiDE also had a higher MAPE for 7 out of 8 months for the top 100 time series than the Tiny version of Chronos. Although we did not perform any kind of hyperparameter tuning for TiDE, it is still impressive that Chronos, in a zero-shot inference setting, managed to have better results than a powerful model like TiDE trained specifically on this dataset.
Having obtained the forecast from Chronos, we can now load the forecast generated by TiDE and TimeGPT and compute the forecasting performance metrics for comparison.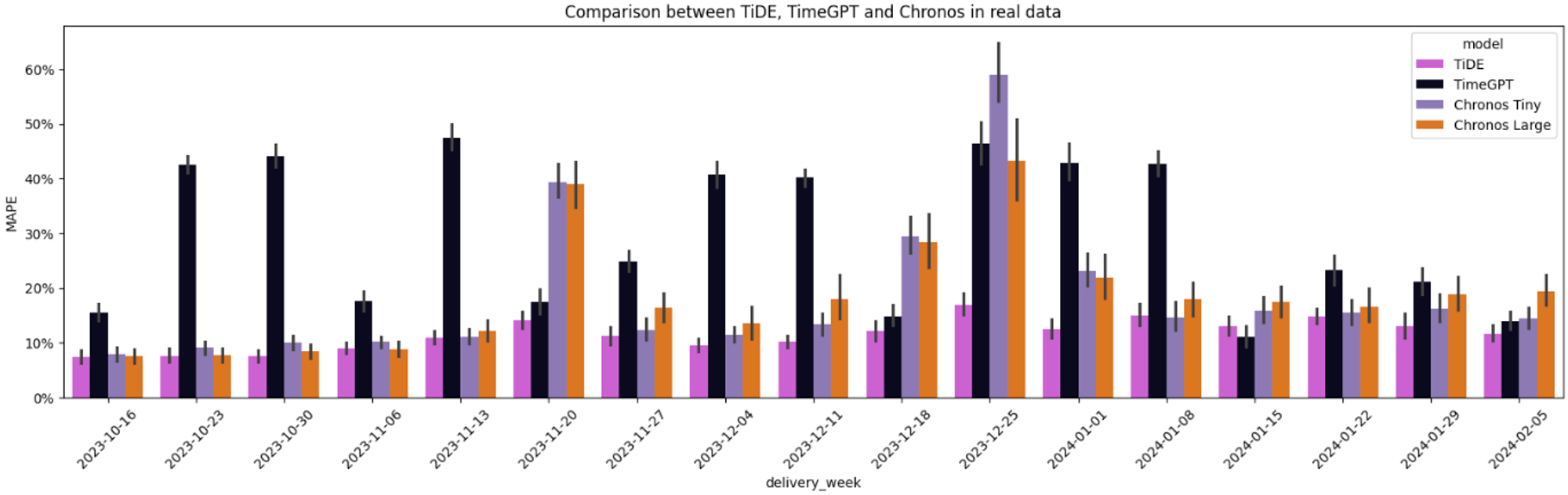
Figure 10 shows TiDE has a lower average MAPE than Chronos across the whole horizon for the 195-time series.
Compared to the other foundation model (TimeGPT), Chronos achieved a lower MAPE in 12 out of 17 weeks. It is impressive since it does not have access to as much information as TimeGPT, namely, public holidays and marketing events. Of those 5 weeks where Chronos did not beat TimeGPT, 3 had a public holiday (Thanksgiving, Christmas, and New Year), which shows that if Chronos could process external information, the results could have been improved.
Finally, comparing both Chronos models, tiny and large, it is surprising that the tiny version performed much better in the long term than the large one, beating it in 9 out of 17 weeks.
Conclusion
This article explored Chronos, the most recent foundation model for time series forecasting. This type of model promises to perform accurately in zero-shot inference, which is especially useful for organizations lacking the specialized expertise to develop SOTA models in-house. Our analysis shows Chronos beating TiDE in the public dataset with significant differences in MAPE. Also, the results show no significant difference between the two Chronos versions (Tiny and Large).
Regarding the private dataset, where we have an optimized TiDE version, Chronos did not manage to beat it. Nevertheless, we need to consider that it performed zero-shot inference, and the difference between both models in most weeks is not significant. One interesting possibility would be to compare a fine-tuned Chronos version in our own data against TiDE. Still, Chronos performs significantly better than TimeGPT and is the first time series foundation model that seems promising.
The AI race to develop foundational models for time series forecasting is just starting, and we will closely monitor its progress and report here. Stay tuned!
About me
Serial entrepreneur and leader in the AI space. I develop AI products for businesses and invest in AI-focused startups.
Founder @ ZAAI | LinkedIn | X/Twitter
References
[1] Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A. C., Lo, W.-Y., Dollár, P., & Girshick, R. (2023). Segment Anything. arXiv. https://arxiv.org/abs/2304.02643
[2] Liu, H., Li, C., Wu, Q., & Lee, Y. J. (2023). Visual Instruction Tuning. arXiv. https://arxiv.org/abs/2304.08485
[3] Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., & Zhou, J. (2023). Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond. arXiv. https://arxiv.org/abs/2308.12966
[4] Garza, A., & Mergenthaler-Canseco, M. (2023). TimeGPT-1. arXiv. https://arxiv.org/abs/2310.03589
[5] Woo, G., Liu, C., Kumar, A., Xiong, C., Savarese, S., & Sahoo, D. (2024). Unified Training of Universal Time Series Forecasting Transformers. arXiv. https://arxiv.org/abs/2402.02592
[6] Rasul, K., Ashok, A., Williams, A. R., Ghonia, H., Bhagwatkar, R., Khorasani, A., Darvishi Bayazi, M. J., Adamopoulos, G., Riachi, R., Hassen, N., Biloš, M., Garg, S., Schneider, A., Chapados, N., Drouin, A., Zantedeschi, V., Nevmyvaka, Y., & Rish, I. (2024). Lag-Llama: Towards Foundation Models for Probabilistic Time Series Forecasting. arXiv. https://arxiv.org/abs/2310.08278
[7] Das, A., Kong, W., Sen, R., & Zhou, Y. (2024). A decoder-only foundation model for time-series forecasting. arXiv. https://arxiv.org/abs/2310.10688
[8] Ansari, A. F., Stella, L., Turkmen, C., Zhang, X., Mercado, P., Shen, H., Shchur, O., Rangapuram, S. S., Arango, S. P., Kapoor, S., Zschiegner, J., Maddix, D. C., Mahoney, M. W., Torkkola, K., Wilson, A. G., Bohlke-Schneider, M., & Wang, Y. (2024). Chronos: Learning the Language of Time Series. arXiv. https://arxiv.org/abs/2403.07815
[9] Das, A., Kong, W., Leach, A., Mathur, S., Sen, R., & Yu, R. (2023). Long-term Forecasting with TiDE: Time-series Dense Encoder. arXiv. https://arxiv.org/abs/2304.08424
[10] Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., & Liu, P. J. (2019). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv. https://arxiv.org/abs/1910.10683
[11] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2023). Attention Is All You Need. arXiv. https://arxiv.org/abs/1706.03762
[12] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., Bikel, D., Blecher, L., Ferrer, C. C., Chen, M., Cucurull, G., Esiobu, D., Fernandes, J., Fu, J., Fu, W., Fuller, B., Gao, C., Goswami, V., Goyal, N., Hartshorn, A., Hosseini, S., Hou, R., Inan, H., Kardas, M., Kerkez, V., Khabsa, M., Kloumann, I., Korenev, A., Koura, P. S., Lachaux, M.-A., Lavril, T., Lee, J., Liskovich, D., Lu, Y., Mao, Y., Martinet, X., Mihaylov, T., Mishra, P., Molybog, I., Nie, Y., Poulton, A., Reizenstein, J., Rungta, R., Saladi, K., Schelten, A., Silva, R., Smith, E. M., Subramanian, R., Tan, X. E., Tang, B., Taylor, R., Williams, A., Kuan, J. X., Xu, P., Yan, Z., Zarov, I., Zhang, Y., Fan, A., Kambadur, M., Narang, S., Rodriguez, A., Stojnic, R., Edunov, S., & Scialom, T. (2023). Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv. https://arxiv.org/abs/2307.09288
[13] Jiang, A. Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D. S., de las Casas, D., Bou Hanna, E., Bressand, F., Lengyel, G., Bour, G., Lample, G., Lavaud, L. R., Saulnier, L., Lachaux, M.-A., Stock, P., Subramanian, S., Yang, S., Antoniak, S., Le Scao, T., Gervet, T., Lavril, T., Wang, T., Lacroix, T., & El Sayed, W. (2024). Mixtral of Experts. arXiv. https://arxiv.org/abs/2401.04088
More articles: https://zaai.ai/lab/