

Enhancing Communication in Global Markets: Leveraging PGVector for Multilingual Semantic Search, Llama2-Powered RAG Systems, and State-of-the-Art Translation Models to Optimize Multilingual Customer Interactions
This article was co-authored by Luís Roque and Rafael Guedes
Introduction
As organizations keep evolving, there is one thing that remains constant: the pursuit of customer satisfaction. Enhancing customer experience is one of the most critical aspects of building a sustainable and successful business. The integration of AI in companies’ workflows will revolutionize this arena. It will enable personalized customer service, allowing businesses to meet, anticipate, and surpass customer expectations. Companies embracing AI for customer service early will gain a significant competitive edge.
Envision a situation where you are browsing Amazon for a specific product. Upon reaching the product’s detailed page, you face the crucial task of deciding its suitability for your needs. To do this, you begin sifting through thousands of customer reviews written in several different languages — a task that is tedious, challenging, and time-consuming. But, imagine if you had access to a chatbot capable of addressing your queries in your language. It would be using insights drawn from other customers’ feedback. This could significantly streamline everyone’s decision-making process.
In this article, we provide a detailed explanation of how multilingual translation models like mBART work and its implementation in Python. We also show how we can adapt a pre-trained multilingual model to perform language detection in a sequence of text. Finally, we create a chatbot powered by multilingual semantic search, an RAG system, and a translation model to answer customers in their language based on other customers’ product reviews.
As always, the code is available on our GitHub.
mBART: a multilingual translation model
mBART [1] is an extension of BART [2] and it consists of a multilingual sequence-to-sequence denoising auto-encoder. Its Transformer architecture comprises 12 encoder and decoder layers with an additional normalization layer. The model has a dimension of 1024 units and 16 attention heads, for a total of ~680M parameters.
Machine Translation is achieved by mBART due to its training process which has 2 steps, Pre-Training and Fine-Tuning:
- The input of the Pre-Training step is a monolingual document modified through a noise function that removes 35% of the words and a permutation of sentences to make the model learn how to recover the original text.
- The model can reconstruct the original text due to its bi-directional encoder which can read the document forward and backward for a proper interpretation.
- After that, the document is encoded into an embedding vector that is passed to the decoder to reconstruct the original text by predicting the next word based on the previous words in the sequence.
- This step is not specific for machine translation which makes mBART reusable for other NLP tasks such as summarisation.
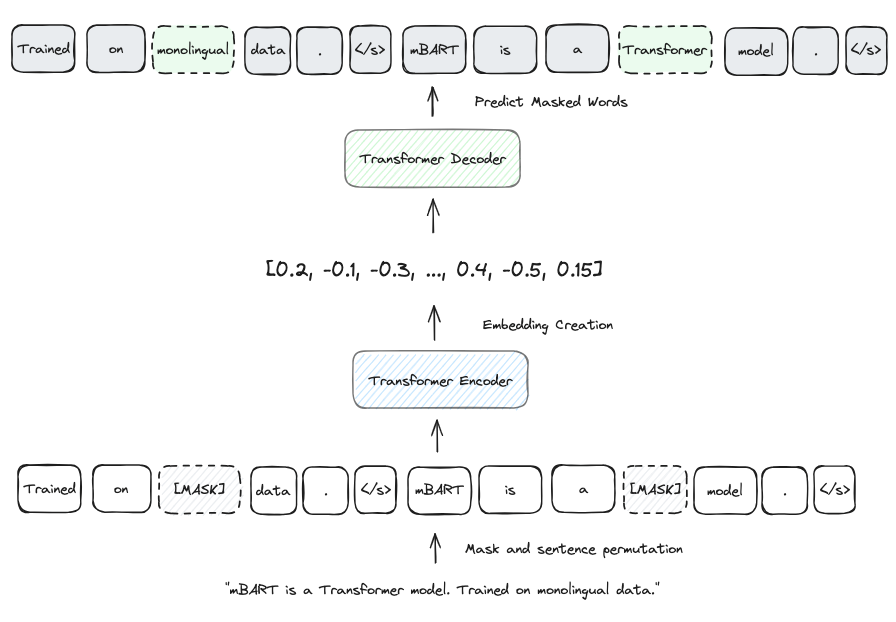
- The Fine-Tuning step is what makes mBART specialized in machine translation. This step consists of feeding the source language to the encoder and decoding the target language. The model weights are updated to minimize the difference between the predicted and the actual translation.

The authors also noticed that this model learns some kind of language structure during pre-training that is not linguistically specific, suggesting that the initialization is partially language-universal.
This phenomenon allows knowledge transfer between languages if the other language is in the monolingual pre-training set. For example, if a model is fine-tuned on Korean-English translation then the model will be able to translate Italian-English without further training (as long as Italian was present in the pre-training dataset).
mBART in practice
The setup of mBART just takes a few lines of code when using HuggingFace (HF).
We start by importing and loading the model and the tokenizer from transformers.
After that, we just need to:
- define the source language using
tokenizer.src_lang* - encode the source document
- translate the encoded document to the target language by setting the argument
forced_bos_token_id* - (the language acronym can be seen here).
In the code below, we performed the translation of two documents:
- Portuguese to English
- German to French
from transformers import MBartForConditionalGeneration, MBart50TokenizerFast
model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
tokenizer = MBart50TokenizerFast.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", use_fast=False)
doc_pt = "Este passo não é específico para tradução de máquina"
doc_de = "Dieser Schritt ist nicht spezifisch für die maschinelle Übersetzung"
# translate Portuguese to English
tokenizer.src_lang = "pt_XX"
encoded = tokenizer(doc_pt, return_tensors="pt")
generated_tokens = model.generate(**encoded, forced_bos_token_id=tokenizer.lang_code_to_id["en_XX"])
print(f"Translation PT-EN: {tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)}")
## *Translation PT-EN: ['This step is not specific to machine translation.']*
# translate German to French
tokenizer.src_lang = "de_DE"
encoded = tokenizer(article_de, return_tensors="pt")
generated_tokens = model.generate(**encoded, forced_bos_token_id=tokenizer.lang_code_to_id["fr_XX"])
print(f"Translation DE-FR: {tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)}")
## *Translation DE-FR: ['Cette étape n'est pas spécifique pour la machine translation']*
A fine-tuned version of XLM-RoBERTa for language detection
mBART requires the user to identify the source and target language, therefore, this section covers the explanation of XLM-RoBERTa and its fine-tuned version for language detection.
XLM-RoBERTa is a transformer-based multilingual masked language model trained on monolingual documents from 100 languages. It is an improved version of XLM-100 [4] due to a significant increase in the amount of training data and the use of a language-independent model for tokenization, Sentence Piece [5], that brings benefits such as efficiency and simplicity over a language-specific tokenizer.
The model has 12 layers, 768 hidden states, 3072 units in the feed-forward layers, 12 attention heads, and 270M parameters. It can be used for tasks such as machine translation, named entity recognition, and cross-lingual question answering.
Its training process is similar to mBART, the authors also mask tokens from the input documents and make the model learn how to predict those tokens. The only difference is that the authors did not use sentence permutations.
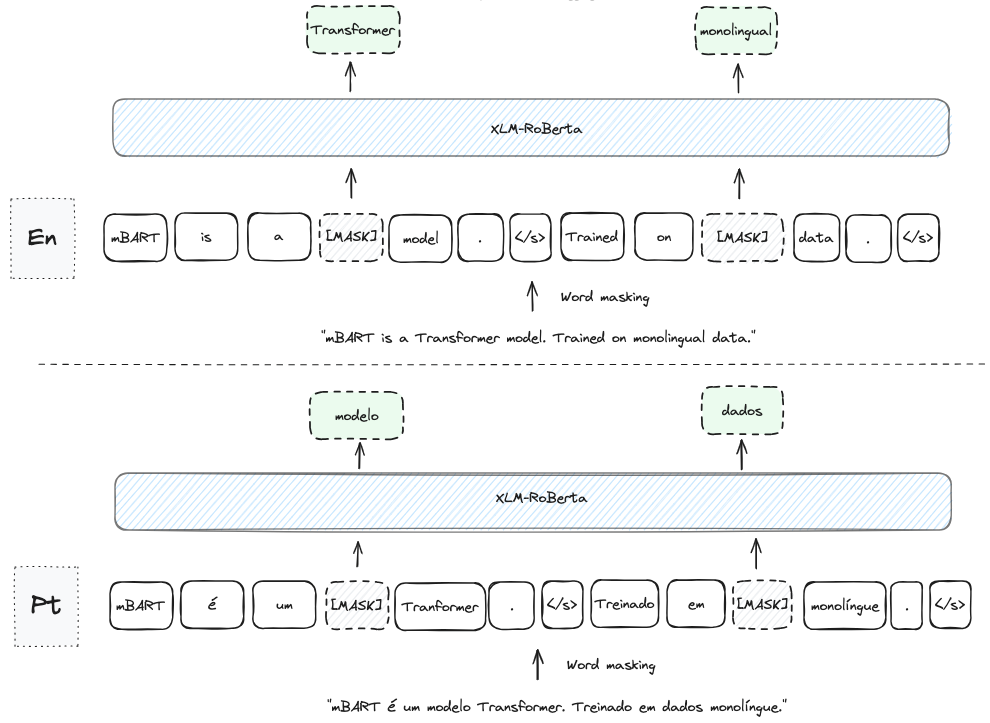
XLM-RoBERTa can also be fine-tuned for other tasks, such as language detection, by adding a classification head on top of the architecture. The model receives as input a sequence of text and classifies it based on the languages that were trained with. papluca/xlm-roberta-base-language-detection model in HF is an example of such a model trained to classify 20 different languages.
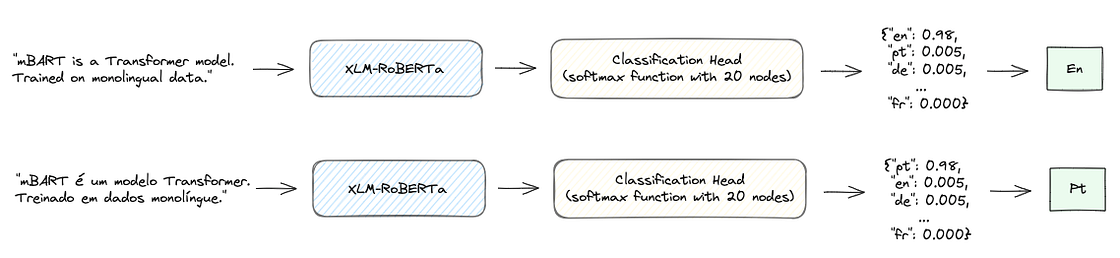
XLM-RoBERTa for language detection in practice
As mentioned before XLM-RoBERTa for language detection is available in HF through the trained model papluca/xlm-roberta-base-language-detection .
To use it, we just need to import pipeline from transformers and define it as a pipeline for ‘text-classification’ with the respective model.
Then, we just pass a list of documents and the model returns the language of each document together with a score that measures the certainty of the prediction.
from transformers import pipeline
model = pipeline("text-classification", model="papluca/xlm-roberta-base-language-detection")
texts = [
"Este passo não é específico para tradução de máquina",
"Dieser Schritt ist nicht spezifisch für die maschinelle Übersetzung",
"This step is not specific to machine translation.",
"Cette étape n'est pas spécifique pour la machine translation"
]
model(texts)
#[{'label': 'pt', 'score': 0.9957656860351562},
# {'label': 'de', 'score': 0.9934625625610352},
# {'label': 'en', 'score': 0.9935802221298218},
# {'label': 'fr', 'score': 0.9938964247703552}]
Multilingual chatbot to support customer purchasing
In this section, we will show you how to combine multilingual semantic search, RAG systems, and translation models to clarify customer doubts when purchasing a product based on customer reviews.
First, we will set up our PGvector database to support the multilingual semantic search (we have explained how it works and how to set it up in this article). Nevertheless, to recap, we need docker and the following docker-compose.yaml file:
version: '3.8'
services:
postgres:
container_name: container-pg
image: ankane/pgvector
hostname: localhost
ports:
- "5432:5432"
env_file:
- ./src/env/postgres.env
volumes:
- postgres-data:/var/lib/postgresql/data
restart: unless-stopped
networks:
- zaai_network
volumes:
postgres-data:
networks:
zaai_network:
You also need to create an .env file under src/env/ with the following:
POSTGRES_DB=postgres
POSTGRES_USER=admin
POSTGRES_PASSWORD=root
After that, just run the command docker-compose up -d and the PGVector database is ready.
To populate the database, we will use a dataset from Amazon (License CC0: Public Domain) with customer reviews for several products, but we will use only the first 10 products to make things faster to experiment with.
- We use our Encoder class that uses a multilingual model from HF called
"sentence-transformers/multi-qa-mpnet-base-dot-v1". - The VectorDatabase class will use the encoder to convert the documents into embeddings and store them in PGVector using LangChain.
- We created a new column
full_reviewthat concatenates the title and the review from the customer to enrich our reviews. - Then, we loop over 10 different product IDs, convert them into Documents (the format expected from LangChain), and store them in PGVector.
from encoder.encoder import Encoder
from retriever.vector_db import VectorDatabase
from langchain.docstore.document import Document
import pandas as pd
encoder = Encoder()
vectordb = VectorDatabase(encoder.encoder)
df = pd.read_csv('data/data.csv')
# create new column that concatenates title and review
df['full_review'] = df[['reviews.title', 'reviews.text']].apply(
lambda row: ". ".join(row.values.astype(str)), axis=1
)
for product_id in df['asins'].unique()[:10]:
# create documents to store in Postgres
docs = [
Document(page_content=item)
for item in df[df['asins'] == product_id]["full_review"].tolist()
]
passages = vectordb.create_passages_from_documents(docs)
vectordb.store_passages_db(passages, product_id
5. When storing the reviews for each product, we assign the product ID as the key (collection_name), so that when our chatbot is looking for context regarding a product, it knows which information is related to each product and retrieves the correct one.
def store_passages_db(self, passages: list, id: str) -> None:
"""
Store passages in vector database in embedding format
Args:
passages (list): list of passages
id (str): id to identify the use case
"""
PGVector.from_documents(
embedding=self.encoder,
documents=passages,
collection_name=id,
connection_string=self.conn_str,
pre_delete_collection=True,
)
With our vector database populated, we can now create a Streamlit application to ask questions about products.
We start by importing the libraries and initiating our classe
# import libraries import streamlit as st from encoder.encoder import Encoder from retriever.vector_db import VectorDatabase from generator.generator import Generator from translator.translator import Translator from classifier.language_classifier import LanguageDetector # init classes generator = Generator() encoder = Encoder() vectordb = VectorDatabase(encoder.encoder) translator = Translator() lang_classifier = LanguageDetector()
Then, we create our application to render a layout similar to chatGPT with messages from the user and the system.
# create the app
st.title("Welcome")
# create the message history state
if "messages" not in st.session_state:
st.session_state.messages = []
# render older messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# render the chat input
prompt = st.chat_input("Enter your message...")
if prompt:
st.session_state.messages.append({"role": "user", "content": prompt})
# render the user's new message
with st.chat_message("user"):
st.markdown(prompt)
When the user inserts their message (prompt), we perform several steps:
- Since we do not have a landing page where we can retrieve the product ID, the user needs to insert a message of this type:
Product_id|Query. With this format, we can split the string using the character|and get the product ID and the question. - Then, we use XLM-RoBERTa to detect the customer language.
- We retrieve the 4 documents most similar to the user question and we do not translate the question to English since we are using multilingual semantic search.
- From the documents retrieved, we detect which ones are not in English and translate them to pass as context to the RAG system (for further details check our article about RAG systems).
- Before sending the query with the context, we translate it so that the LLM receives all information in English.
- Finally, we generate the answer and translate it into the customer’s language.
# render the assistant's response
with st.chat_message("assistant"):
# get the product id and the customer question
ID = prompt.split('|')[0]
QUERY = prompt.split('|')[1]
# detect customer language to reply back in same language
user_detected_language = lang_classifier.detect_language(QUERY)
# retrieve context about the product
context = vectordb.retrieve_most_similar_document(QUERY, k=4, id=ID)
# convert all context into english for our LLM
english_context = []
for doc in context:
detected_language = lang_classifier.detect_language(doc)
if detected_language != 'en_XX':
doc = translator.translate(doc, detected_language, 'en_XX')
english_context.append(doc)
context = '\\n'.join(english_context)
# translate customer query to english
if user_detected_language != 'en_XX':
QUERY = translator.translate(QUERY, user_detected_language, 'en_XX')
# generate anwser with our LLM based on customer query and context
answer = generator.get_answer(context, QUERY)
# if the customer language is not english, then translate it
if user_detected_language != 'en_XX':
answer = translator.translate(answer, 'en_XX', user_detected_language)
# show answer to customer
st.markdown(answer)
# add the full response to the message history
st.session_state.messages.append({"role": "assistant", "content": answer})
In Figure 6, you can see the final result of our Streamlit application. We asked ‘What do people like about the product B00QJDU3KY ?’ and ‘What do people dislike about the product B00QJDU3KY ?’ in French. Our chatbot correctly answered both questions in French, even though the reviews were written in different languages.
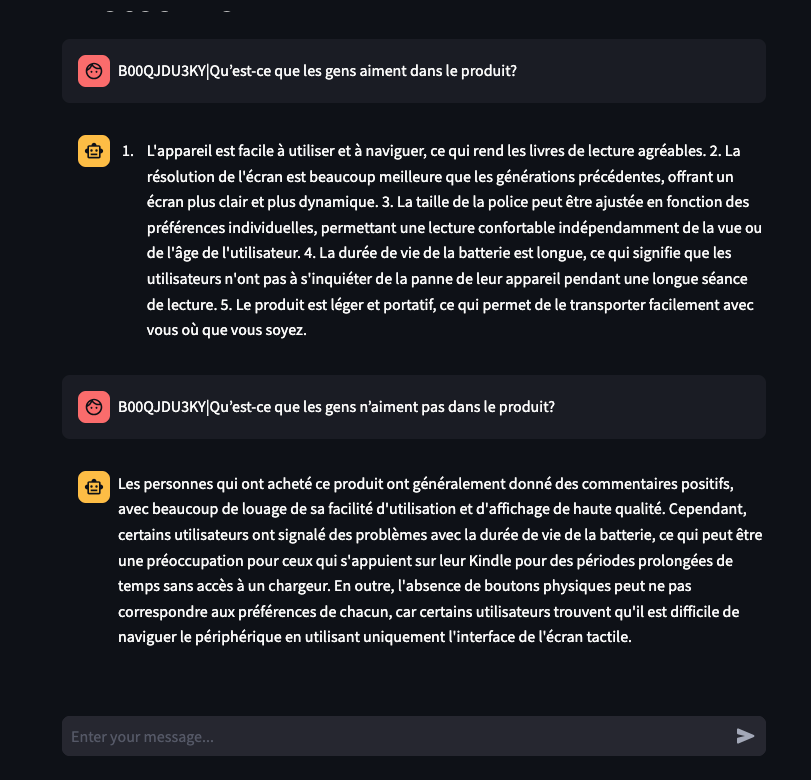
If you access our code in Github you can set everything up by cloning our repo, adding the data, env files, and the Llama model (check the ReadMe for more details). Then, run the command docker-compose up --build . Afterward, just go to your browser and enter this link (http://localhost:8501/).
Conclusion
Customer support will undergo substantial changes in 2024; this is one of our predictions for the year. We expect solutions like the one presented in the article to be implemented by leading customer-facing brands. It will alter the standards that customers expect when interacting with their favorite brands. This shift will likely create a trickle-down effect, encouraging medium-sized and smaller brands to adopt these new AI technologies.
In this article, we combined several LLM techniques explored in previous articles, such as multilingual semantic search and RAG systems with translation models, to create a multilingual chatbot. We showed how to build an application with a layout similar to chatGPT for this use case. We have tested several language combinations and, while it worked well in the French-English case, we noticed that mBART fails in some language combinations. It was not capable of translating, for example, English to Portuguese, as promised by the authors.
Nevertheless, it is just a matter of changing mBART to a different translation model for the use case shared in this article to be implemented in more language combinations. You can test, for example, this new model released by Meta that can perform machine translation in 96 different languages.
References
[1] Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer. Multilingual Denoising Pre-training for Neural Machine Translation. arXiv:2001.08210, 2020
[2] Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. arXiv:1910.13461, 2019
[3] Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, Veselin Stoyanov. Unsupervised Cross-lingual Representation Learning at Scale. arXiv:1911.02116, 2020
[4] Guillaume Lample, Alexis Conneau. Cross-lingual Language Model Pretraining. arXiv:1901.07291, 2019
[5] Taku Kudo, John Richardson. SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. arXiv:1808.06226, 2018
More articles: https://zaai.ai/lab