

Leveraging ChromaDB, Langchain, and ChatGPT: Enhanced Responses and Cited Sources from Large Document Databases
This article was authored by Luis Roque.
Introduction
Document-oriented agents are starting to get traction in the business landscape. Companies increasingly leverage these tools to capitalize on internal documentation, enhancing their business processes. A recent McKinsey report [1] underscores this trend, suggesting generative AI could boost the global economy by $2.6–4.4 trillion annually and automate up to 70% of current work activities. The study identifies customer service, sales and marketing, and software development as the main sectors that will be affected by the transformation. Most of the change is coming from the fact that the information that powers these areas within a company can be more accessible to both employees and customers through the usage of solutions such as document-oriented agents.
With the current technology, we are still facing some challenges. Even if you consider the new Large Language Models (LLMs) with 100k token limits, the models still have limited context windows. While 100k tokens seem to be a high number, it is a tiny number when we look at the size of the databases powering, for example, a customer service department. Another problem that often arises is the inaccuracies in model outputs. In this article, we’ll provide a step-by-step guide to building a document-oriented agent that can handle documents of any size and deliver verifiable answers.
We use a vector database — ChromaDB — to augment our model context length capabilities and Langchain to facilitate integrations between the different components in our architecture. As our LLM, we use OpenAI’s chatGPT. Since we want to serve our application, we use FastAPI to create endpoints for users to interact with our agent. Finally, our application is containerized using Docker, which allows us to easily deploy it in any type of environment.
As always, the code is available on my Github.
Vector Databases: The Essential Core of Semantic Search Applications
Vector databases are essential to unlocking the power of generative AI. These types of databases are optimized to handle vector embeddings — data representations containing rich semantic information from the original data. Unlike traditional scalar-based databases, which struggle with the complexity of vector embeddings, vector databases index these embeddings, associating them with their source content and allowing for advanced features like semantic information retrieval and long-term memory in AI applications.
Vector databases are not the same as vector indices, such as Facebook’s AI Similarity Search (FAISS) — which we already covered in this series in a previous article [2]. They allow data insertion, deletion, and updating, store associated metadata, and support real-time data updates without needing full re-indexing — a time-consuming and computationally expensive process.
Rather than exact matches, vector databases employ similarity metrics to find vectors closest to a query. They use Approximate Nearest Neighbor (ANN) search algorithms for optimized search. Some examples of such algorithms are: Random Projection, Product Quantization, or Hierarchical Navigable Small World. These algorithms compress the original vector, speeding up the query process. Furthermore, similarity measures like Cosine similarity, Euclidean distance, and Dot product compare and identify the most relevant results for a query.
Figure 2 succinctly illustrates the similarity search process in vector databases. Starting with ingestion of raw documents (i), the data is broken into manageable chunks (ii) and converted into vector embeddings (iii). These embeddings are indexed for quick retrieval (iv), and similarity metrics between the chunks vectors and the user query are computed (v). The process ends with the most relevant data chunks being output (vi), offering users insights aligned with their original query.
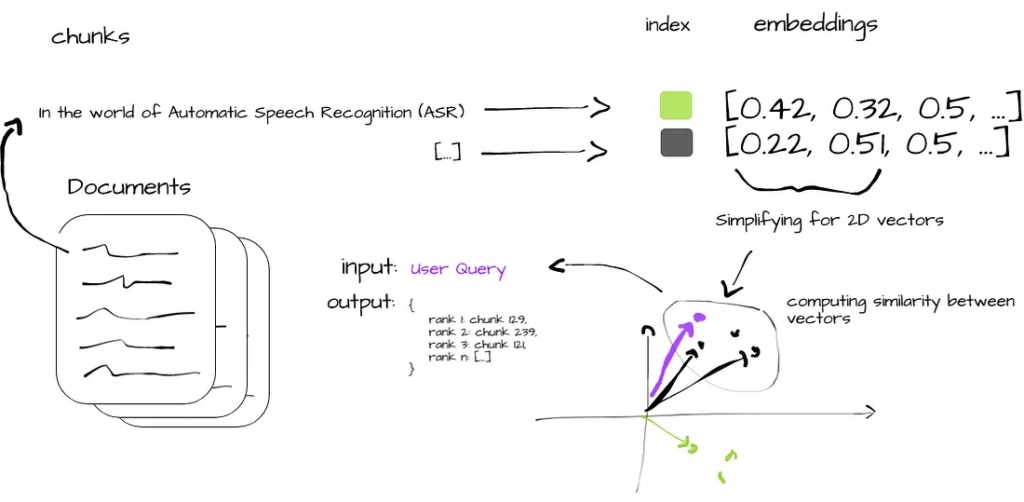
The similarity search process: i) ingestion of raw documents, ii) process into chunks, iii) creation of embeddings, iv) indexing, v) compute of similarity metrics and, finally, vi) producing the output chunks (image by author)
Building a Document-Oriented Agent
We start by loading all necessary models and data at server startup.
We load our data from a predefined directory and process them into manageable chunks. These chunks are designed to be sized so that we can pass the chunks to the LLM as we got the results from the similarity search procedure. This process utilizes the DirectoryLoader to load documents into memory and the RecursiveCharacterTextSplitter to break them down into manageable chunks. It splits documents at a character level, with a default chunk size of 1000 characters and a chunk overlap of 20 characters. The chunk overlap ensures there is contextual continuity between chunks, minimizing the risk of losing meaningful context at the chunk borders.
def load_docs(directory: str):
"""
Load documents from the given directory.
"""
loader = DirectoryLoader(directory)
documents = loader.load()
return documents
def split_docs(documents, chunk_size=1000, chunk_overlap=20):
"""
Split the documents into chunks.
"""
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
docs = text_splitter.split_documents(documents)
return docsThen, we generate vector embeddings from these chunks using the SentenceTransformerEmbeddings method and index them in ChromaDB, our vector database. These embeddings are stored in the database and serve as our searchable data. The database does not live in memory; notice that we are persisting it on disk, which reduces our memory overhead. Next, we load the chat model, specifically OpenAI’s gpt-3.5-turbo, which serves as our LLM.
@app.on_event("startup")
async def startup_event():
"""
Load all the necessary models and data once the server starts.
"""
app.directory = '/app/content/'
app.documents = load_docs(app.directory)
app.docs = split_docs(app.documents)
app.embeddings = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
app.persist_directory = "chroma_db"
app.vectordb = Chroma.from_documents(
documents=app.docs,
embedding=app.embeddings,
persist_directory=app.persist_directory
)
app.vectordb.persist()
app.model_name = "gpt-3.5-turbo"
app.llm = ChatOpenAI(model_name=app.model_name)
app.db = Chroma.from_documents(app.docs, app.embeddings)
app.chain = load_qa_chain(app.llm, chain_type="stuff", verbose=True)Finally, the “/query/{question}” endpoint receives user queries. It runs a similarity search on the database, using the question as input. If matching documents exist, they are fed into the LLM, and the answer is generated. The answer and the sources (the original documents and their metadata) are returned, ensuring that the provided information is easily verifiable.
@app.get("/query/{question}")
async def query_chain(question: str):
"""
Queries the model with a given question and returns the answer.
"""
matching_docs_score = app.db.similarity_search_with_score(question)
if len(matching_docs_score) == 0:
raise HTTPException(status_code=404, detail="No matching documents found")
matching_docs = [doc for doc, score in matching_docs_score]
answer = app.chain.run(input_documents=matching_docs, question=question)
# Prepare the sources
sources = [{
"content": doc.page_content,
"metadata": doc.metadata,
"score": score
} for doc, score in matching_docs_score]
return {"answer": answer, "sources": sources}We containerized the application using Docker, which ensures isolation and environment consistency, regardless of the deployment platform. The Dockerfile below details our setup:
FROM python:3.9-buster
WORKDIR /app
COPY . /app
RUN pip install - no-cache-dir -r requirements.txt
EXPOSE 1010
CMD ["uvicorn", "main:app", " - host", "0.0.0.0", " - port", "1010"]The application runs in a Python 3.9 environment and we need to install all necessary dependencies from a requirements.txt file:
langchain==0.0.221
uvicorn==0.22.0
fastapi==0.99.1
unstructured==0.7.12
sentence-transformers==2.2.2
chromadb==0.3.26
openai==0.27.8
python-dotenv==1.0.0The application is then served through Uvicorn on port 1010.
Note that we need to configure our environment variables. Our application requires the OPENAI_API_KEY for the ChatOpenAI model. The best practice for sensitive information like API keys is to store them as environment variables rather than hardcoding them into the application.
We use the python-dotenv package to load environment variables from a .env file at the project root. In a production environment, we would want to use a more secure method, such as Docker secrets or a secure vault service.
Experiment: Understanding the Effectiveness of Document-Oriented Agents
The experiment primary goal was to assess our document-oriented agent’s effectiveness in providing comprehensive and accurate responses to user queries.
We use a series of our Medium articles as our knowledge base. These articles, covering a variety of AI and machine learning topics, are ingested and indexed in our Chroma vector database. The selected articles were:
-
- “Whisper JAX vs PyTorch: Uncovering the Truth about ASR Performance on GPUs”
-
- “Testing the Massively Multilingual Speech (MMS) Model that Supports 1162 Languages”
-
- “Harnessing the Falcon 40B Model, the Most Powerful Open-Source LLM”
-
- “The Power of OpenAI’s Function Calling in Language Learning Models: A Comprehensive Guide”
The articles were broken into manageable chunks, converted into vector embeddings, and indexed in our database, thus forming the backbone of the agent’s knowledge.
The user query was executed by calling the API endpoint of our application, which is implemented using FastAPI and deployed via Docker. The query we used for the experiment was: “What is Falcon-40b and can I use it for commercial use?”.
curl --location 'http://0.0.0.0:1010/query/What is Falcon-40b and can I use it for commercial use'In response to our query, the LLM explained what Falcon-40b is and confirmed that it can be used commercially. The information was backed up by four different source chunks, all coming from the article: “Harnessing the Falcon 40B Model, the Most Powerful Open-Source LLM”. Each source chunk was also added to the response, as we saw above, so that the user could verify the original text supporting the answer of the LLM. The chunks were also scored on their relevance to the query, which gives us an additional perspective on the importance of that section to the overall answer of the agent.
{
"answer": "Falcon-40B is a state-of-the-art language model developed by the Technology Innovation Institute (TII). It is a transformer-based model that performs well on various language understanding tasks. The significance of Falcon-40B is that it is now available for free commercial and research use, as announced by TII. This means that developers and researchers can access and modify the model according to their specific needs without any royalties. However, it is important to note that while Falcon-40B is available for commercial use, it is still trained on web data and may carry potential biases and stereotypes prevalent online. Therefore, appropriate mitigation strategies should be implemented when using Falcon-40B in a production environment.",
"sources": [
{
"content": "This is where the significance of Falcon-40B lies. In the end of last week, the Technology Innovation Institute (TII) announced that Falcon-40B is now free of royalties for commercial and research use. Thus, it breaks down the barriers of proprietary models, giving developers and researchers free access to a state-of-the-art language model that they can use and modify according to their specific needs.\n\nTo add to the above, the Falcon-40B model is now the top performing model on the OpenLLM Leaderboard, outperforming models like LLaMA, StableLM, RedPajama, and MPT. This leaderboard aims to track, rank, and evaluate the performance of various LLMs and chatbots, providing a clear, unbiased metric of their capabilities. Figure 1: Falcon-40B is dominating the OpenLLM Leaderboard (image source)\n\nAs always, the code is available on my Github. How was Falcon LLM developed?",
"metadata": {
"source": "/app/content/Harnessing the Falcon 40B Model, the Most Powerful Open-Source LLM.txt"
},
"score": 1.045290231704712
},
{
"content": "The decoder-block in Falcon-40B features a parallel attention/MLP (Multi-Layer Perceptron) design with two-layer normalization. This structure offers benefits in terms of model scaling and computational speed. Parallelization of the attention and MLP layers improves the model’s ability to process large amounts of data simultaneously, thereby reducing the training time. Additionally, the implementation of two-layer normalization helps in stabilizing the learning process and mitigating issues related to the internal covariate shift, resulting in a more robust and reliable model. Implementing Chat Capabilities with Falcon-40B-Instruct\n\nWe are using the Falcon-40B-Instruct, which is the new variant of Falcon-40B. It is basically the same model but fine tuned on a mixture of Baize. Baize is an open-source chat model trained with LoRA, a low-rank adaptation of large language models. Baize uses 100k dialogs of ChatGPT chatting with itself and also Alpaca’s data to improve its performance.",
"metadata": {
"source": "/app/content/Harnessing the Falcon 40B Model, the Most Powerful Open-Source LLM.txt"
},
"score": 1.319214940071106
},
{
"content": "One of the core differences on the development of Falcon was the quality of the training data. The size of the pre-training data for Falcon was nearly five trillion tokens gathered from public web crawls, research papers, and social media conversations. Since LLMs are particularly sensitive to the data they are trained on, the team built a custom data pipeline to extract high-quality data from the pre-training data using extensive filtering and deduplication.\n\nThe model itself was trained over the course of two months using 384 GPUs on AWS. The result is an LLM that surpasses GPT-3, requiring only 75% of the training compute budget and one-fifth of the compute at inference time.",
"metadata": {
"source": "/app/content/Harnessing the Falcon 40B Model, the Most Powerful Open-Source LLM.txt"
},
"score": 1.3254718780517578
},
{
"content": "Falcon-40B is English-centric, but also includes German, Spanish, French, Italian, Portuguese, Polish, Dutch, Romanian, Czech, and Swedish language capabilities. Be mindful that as with any model trained on web data, it carries the potential risk of reflecting the biases and stereotypes prevalent online. Therefore, please assess these risks adequately and implement appropriate mitigation strategies when using Falcon-40B in a production environment. Model Architecture and Objective\n\nFalcon-40B, as a member of the transformer-based models family, follows the causal language modeling task, where the goal is to predict the next token in a sequence of tokens. Its architecture fundamentally builds upon the design principles of GPT-3 [1], with a few important tweaks.",
"metadata": {
"source": "/app/content/Harnessing the Falcon 40B Model, the Most Powerful Open-Source LLM.txt"
},
"score": 1.3283030986785889
}
]
}Conclusions
In this article, we built a solution to overcome the challenges of handling large-scale documents in AI systems, leveraging vector databases and a suite of open-source tools. Our approach employs ChromaDB and Langchain with OpenAI’s ChatGPT to build a capable document-oriented agent.
Our approach enables the agent to answer complex queries by searching and processing chunks of text from large-scale databases — in our case, a series of Medium articles on various AI topics. In addition to the agent’s answers, we also returned the chunks of the original documents used to support the LLM’s claims and their score regarding similarity to the user’s query. It is an important feature since these agents can sometimes provide inaccurate information.
Large Language Models Chronicles: Navigating the NLP Frontier
This article belongs to “Large Language Models Chronicles: Navigating the NLP Frontier”, a new weekly series of articles that will explore how to leverage the power of large models for various NLP tasks. By diving into these cutting-edge technologies, we aim to empower developers, researchers, and enthusiasts to harness the potential of NLP and unlock new possibilities.
References
More articles: https://zaai.ai/lab/