

Agentic AI: Building Autonomous Systems from Scratch
A Step-by-Step Guide to Creating Multi-Agent Frameworks in the Age of Generative AI
This article was co-authored by Luís Roque and Rafael GuedesIntroduction
The rise of generative AI is the new platform shift of the digital era. It solves problems ranging from automation in large enterprises to various types of R&D and creativity. The global market is projected to surpass $65 billion in 2024, and 86% of IT leaders anticipate large organizational changes [1]. So far, the biggest returns are from chatbots (the more generic and abundant use case), code copilots, and enterprise search.
Investment continues to flow into AI, with $13.8 billion invested in 2024 (a sixfold increase from 2023) [1]. Besides, businesses are embedding AI into their core strategies and systems. Technologies like retrieval-augmented generation (RAG), fine-tuning, and specialized models for vertical applications (e.g., healthcare, legal) are becoming mainstream.
Large Language Models (LLMs) have brought attention to AI (in several ways) and opened the door to new ways of solving old problems. This new way is through Agentic AI — a framework where autonomous agents work collaboratively to execute complex, multi-step workflows.
Our demo shows how you can work and develop a multi-agent system. It integrates three specialized agents:
- A web researcher agent that ingests and analyzes internet data.
- Wiki Pageviews captures hourly views of Wikipedia pages. The data, ranging from 2021 to 2023, was aggregated to cover other granularities (daily, weekly, and monthly), resulting in a dataset of 300 billion time points.
- A transcriptor and summarizer agent that retrieves and condenses video or text data into actionable summaries.
- A blog writer agent that synthesizes this information into a coherent structure.
These agents operate within a structured workflow. They leverage foundational LLMs and existing tools in everyday enterprise stacks. We show how organizations can streamline tasks, reduce human effort, and enhance output quality — all while maintaining adaptability to complex scenarios.
As always, the code is available on our GitHub.
AI Agents: What are they?
AI agents, usually powered by an LLM, are systems designed to act autonomously to achieve a specific goal. They receive an input prompt and have access to a toolset needed to complete certain tasks.
The input prompt can take several forms. It can be a simple text prompt given by a human with instructions to follow, such as “Write a blog post about AI Agents.” In a Multi-Agent System (MAS), it can be the output of the previous agent, which can also be text or more structured data such as JSON.
The tools an agent can access to perform a task are crucial for its success (similar to humans). For example, if a chef does not have an oven working, they cannot cook a delicious roast. In the case of AI Agents, these tools are usually APIs that allow them to connect to other systems to perform a task. For example, a connection to a search engine to look up information or a database to run a query against.
When building these kinds of Agents, there are two main classes to be defined [2]:
1. The Agent (which has four main components):
- GThe LLM utilized by the agent can be a closed source like GPT-4 or Claude Sonnet or an open source like LLaMA 3.3 or Mixtral 8x22. The LLM receives parameters we should also set accordingly, such as temperature or the maximum number of tokens produced. The choice of the LLM will depend on the task the agent has to perform. For example, while GPT-4 has good reasoning capabilities, Claude Sonnet performs better at coding, and GPT-4o-mini is the fastest. On the other hand, one might opt for an open-source model to avoid sharing information with third-party companies if dealing with critical information.
- The Role of the agent defines its responsibilities, providing purpose and guiding the agent through the tasks and behaviors that are expected of it. For example, the role of the agent can be processing and analyzing information, retrieving data from a database, or coordinating interactions between other agents.
- The Backstory defines the agent’s current knowledge of its environment, responsibilities, and interactions with other agents or tools. It also defines the agent’s current intent, i.e., what the agent is planning to do based on its knowledge of the environment and its goal.
- The Goal is what the agent is expected to achieve, and it usually translates into the agent’s output. For example, if the agent is responsible for retrieving data from a database and answering a user’s question, its goal is to get an answer, and the output is the answer.
2. The Task (which has three main components):
- The Description provides a detailed explanation of what needs to be done by clearly defining the nature of the task and the outcome. It also provides specific instructions and constraints that the agent might face. For example, if the task is to retrieve data from a database, the description must specify the parameters for retrieval and any formatting requirements.
- The Output describes how the task result should be presented by setting clear expectations for the output. It can indicate that it should be in text, JSON, list, HTML, SQL, or the response from an API.
- Finally, the Agent is responsible for executing the task.
While one AI Agent can effectively perform a specific task, we can only extract its full potential when leveraging a group of agents. By interacting and collaborating with each other, they offer scalability and specialization to solve complex problems. The next section will address these MAS.

Multi-Agent Collaborative System (MAS)
MAS is defined by a group of agents, also referred to as a Crew. Each possesses unique skills and specialized capabilities. These agents collaborate to solve simple tasks in order to achieve a bigger and more complex common goal [3].
Within the Crew, each agent is an individual LLM with distinct characteristics, roles, and specific tools. Similar to humans, these agents communicate with one another by sending the output of their tasks to subsequent agents to build upon.
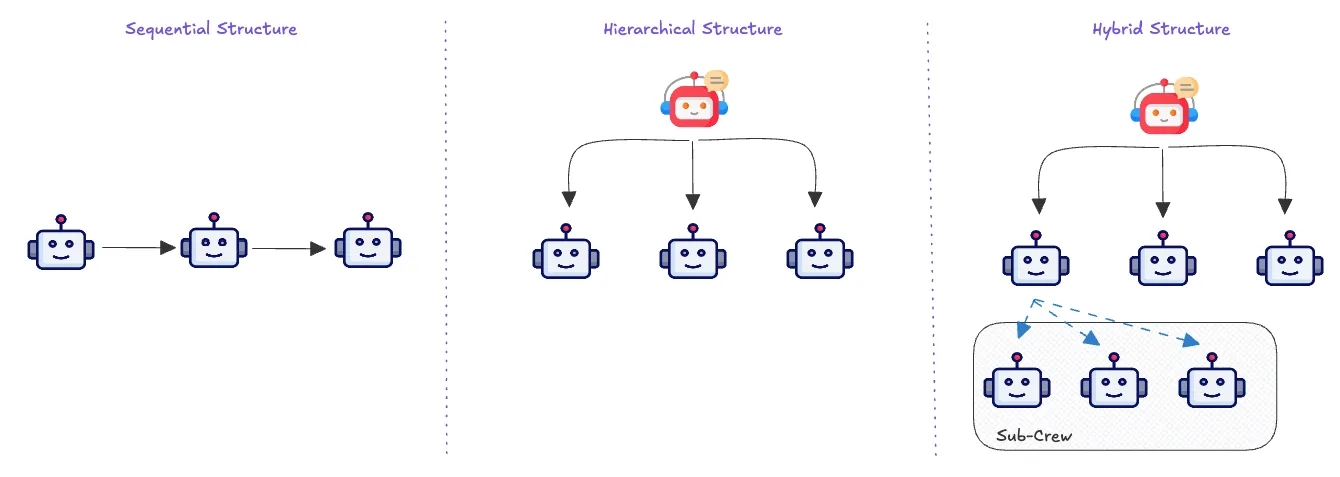
The structure of a Crew can be categorized into three main types based on the interaction between agents:
- Sequential: the agents work in a chain, where one agent’s output is the next’s input. By solving smaller tasks, they can solve the bigger and more complex objective for which the Crew was designed.
- Hierarchical: it usually consists of a manager and multiple subordinates, and the role of the leader is to delegate, plan, and manage the completion of tasks. The subordinates execute the leader’s instructions. In this scenario, we can have agents performing tasks simultaneously since not every agent has a sequential dependency.
- Hybrid: this structure has Sequential and Hierarchical environments within the same Crew. It typically happens when some agents, with complex tasks at hand, break them down into smaller ones and build a sub-crew with new agents. They become the leader of that sub-crew and, at the same time, a subordinate of the original Crew.
CrewAI: Creating a MAS to write a blog post
In this section, we will create a Multi-Agent System (MAS) to write a blog post about AI agents (we know it might sound a bit confusing to have AI agents writing about AI agents, but bear with us) using one of the most popular packages in this space, CrewAI. Figure 4 illustrates the complete architecture of our approach:
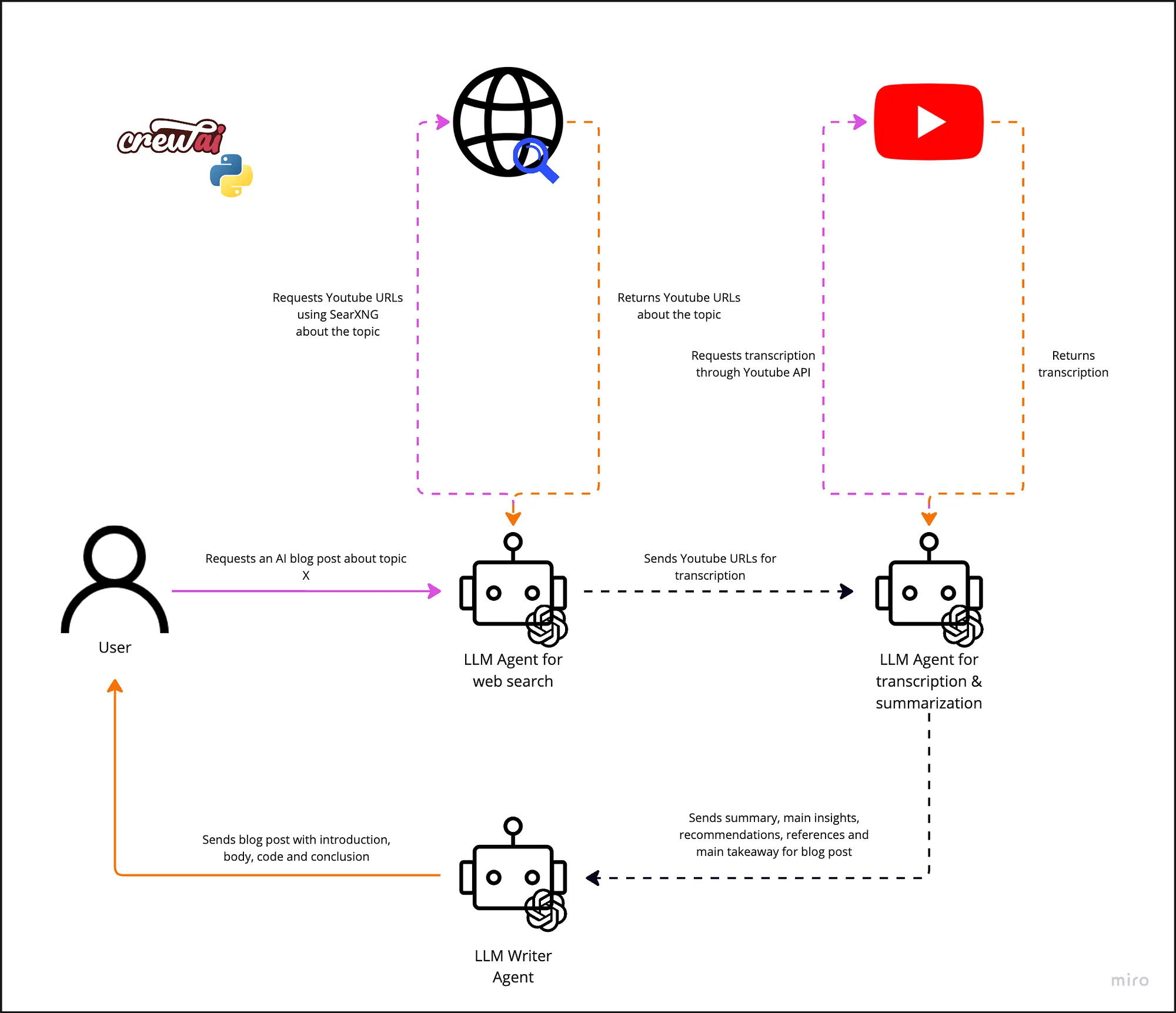
Our crew comprises three agents with different tasks that work collaboratively to generate a blog post in HTML format. These agents are:
- Web Researcher Agent responsible for connecting to a search engine called SearXNG and retrieving useful and the most up-to-date YouTube URLs about AI Agents. The agent and its task definition can be seen below:
researcher:
role: >
{topic} Senior Data Researcher
goal: >
Uncover cutting-edge developments in {topic}
backstory: >
You're a seasoned researcher with a knack for uncovering the latest
developments in {topic}. Known for your ability to find the most relevant
information and present it in a clear and concise manner.
research_task:
description: >
Conduct a thorough research about {topic}
Make sure you find any interesting and relevant youtube links given
the current year is 2024.
expected_output: >
A list with youtube URLs that cover {topic} and the respective description
with the most relevant information about {topic}. Ignore any links that don't
start with "https://www.youtube.com".
agent: researcher
- Transcriptor & Summarizer Agent connects to the YouTube API to retrieve transcriptions from the URLs provided by the Web Search Agent. It summarizes the transcription, extracts main insights and references, and makes recommendations based on the video’s content. As shown below, the agent and its task is defined as:
summarizer:
role: >
{topic} Summarizer
goal: >
Summarize and extract knowledge and other insightful and interesting information from {topic}
backstory: >
You're an expert on analyzing information and extracting the most important
and insightful information in a concise manner.
You're known for your ability to summarize and retrive facts, references, quotes
and recommend the most useful surprising information about the {topic}.
summarize_task:
description: >
Analyse the information about the {topic} thoroughly to extract the most valuable insights, facts, and recommendations.
Adhere strictly to the provided schema when extracting information from the input content.
Ensure that the output matches the field descriptions, types and constraints exactly. Ignore any links that don't
start with "https://www.youtube.com".
expected_output: >
A json with a summary of the {topic} and the most valuable insights, facts, and recommendations. Also add the
youtube links as references.
agent: summarizer
- Blog Writer Agent is the third and last agent of our crew. It makes use of the summary generated by the Transcriptor & Summarizer to create a blog post about the topic in an HTML format. This HTML must have a professional appearance, including a navigation bar to help the reader surface through the article. The agent and its task is defined as:
blog_writer:
role: >
{topic} Blog Writer
goal: >
Create detailed blog posts based on {topic} research findings
backstory: >
You're a meticulous writer with a keen eye for detail.
You're known for your ability to turn complex topics into clear and concise blog posts,
making it easy for others to understand and act on the information you provide.
write_task:
description: >
Review the context you got and expand each topic into a full section for a blog post.
Make sure the blog post is detailed and contains any and all relevant information.
The blog post must contain an introduction, a body, a code example and a conclusion section.
expected_output: >
A fully-fledged blog post with the main topics, each presented as a complete section of information.
Format it as HTML without using '```'. Make it look like a professional tech blog website,
including a navbar, menu, and styling. Incorporate YouTube links as clickable references within
the text and at the end.
agent: blog_writer
The definitions above must be defined in two different YAML files, one for agents (agents.yaml) and another for tasks (taks.yaml). Once this process has been done, it is time to create the tools agents use to perform their tasks.
In our case, only the Blog Writer does not need any tool, the Researcher needs the search engine, while the Transcriptor and Summarizer needs the connection to the YouTube API.
Search Engine (SearXNG)
- It is good practice to define the input schema when defining the tools. As shown in the code snippet below, our search engine tool expects to receive the search query and the number of results to retrieve.
- Then, we must define the tool itself. The __init__ function sets the search engine to use, while the _run function specifies how the agent will use the tool. It basically searches YouTube videos about the topic the user requested, in this case, AI Agents.
from crewai.tools import BaseTool
from typing import Type, Optional, List, Dict
from pydantic import BaseModel, Field, PrivateAttr
from langchain_community.utilities import SearxSearchWrapper
class SearxSearchToolInput(BaseModel):
"""Input schema for SearxSearchTool."""
query: str = Field(..., description="The search query.")
num_results: int = Field(10, description="The number of results to retrieve.")
class SearxSearchTool(BaseTool):
name: str = "searx_search_tool"
description: str = (
"A tool to perform searches using the Searx metasearch engine. "
"Specify a query and optionally limit by engines, categories, or number of results."
)
args_schema: Type[BaseModel] = SearxSearchToolInput
_searx_wrapper: SearxSearchWrapper = PrivateAttr()
def __init__(self, searx_host: str, unsecure: bool = False):
"""Initialize the SearxSearchTool with SearxSearchWrapper."""
super().__init__()
self._searx_wrapper = SearxSearchWrapper(
searx_host=searx_host, unsecure=unsecure
)
def _run(
self,
query: str,
num_results: int = 10,
) -> List[Dict]:
"""Perform a search using the Searx API."""
try:
results = self._searx_wrapper.results(
query=query + " :youtube",
num_results=num_results,
)
return results
except Exception as e:
return [{"Error": str(e)}]
YouTube API
- This tool follows the same principle by first defining the input schema, which consists of the YouTube URL and the language we want the transcription to be in.
- We also define an output schema where not only the transcription is returned but also the duration of the video.
- Finally, the tool itself consists of extracting the video ID from the URL and connecting to the Youtube API to retrieve the transcription, as seen in the _run function.
from typing import Type, Optional
from pydantic import Field, BaseModel
from youtube_transcript_api import (
NoTranscriptFound,
TranscriptsDisabled,
YouTubeTranscriptApi,
)
from crewai.tools import BaseTool
class YouTubeTranscriptToolInputSchema(BaseModel):
"""
Tool for fetching the transcript of a YouTube video using the YouTube Transcript API.
Returns the transcript with text, start time, and duration.
"""
video_url: str = Field(
..., description="URL of the YouTube video to fetch the transcript for."
)
language: Optional[str] = Field(
None, description="Language code for the transcript (e.g., 'en' for English)."
)
class YouTubeTranscriptToolOutputSchema(BaseModel):
"""
Output schema for the YouTubeTranscriptTool. Contains the transcript text, duration, comments, and metadata.
"""
transcript: str = Field(..., description="Transcript of the YouTube video.")
duration: float = Field(
..., description="Duration of the YouTube video in seconds."
)
class YouTubeTranscriptTool(BaseTool):
"""
Tool for fetching the transcript of a YouTube video using the YouTube Transcript API.
Attributes:
input_schema (YouTubeTranscriptToolInputSchema): The schema for the input data.
output_schema (YouTubeTranscriptToolOutputSchema): The schema for the output data.
"""
name: str = "youtube_transcript_tool"
description: str = (
"A tool to perform youtube transcript extraction. "
"Specify the url of the youtube video and optionally the language code."
)
args_schema: Type[BaseModel] = YouTubeTranscriptToolInputSchema
def __init__(self):
"""
Initializes the YouTubeTranscriptTool.
"""
super().__init__()
def _run(
self, video_url: str, language: Optional[str] = None
) -> YouTubeTranscriptToolOutputSchema:
"""
Runs the YouTubeTranscriptTool with the given parameters.
Args:
video_url (list[str]): The list of YouTube video URLs to fetch the transcript for.
language (Optional[str]): The language code for the transcript (e.g., 'en' for English).
Returns:
YouTubeTranscriptToolOutputSchema: The output of the tool, adhering to the output schema.
Raises:
Exception: If fetching the transcript fails.
"""
video_id = self.extract_video_id(video_url)
try:
if language:
transcripts = YouTubeTranscriptApi.get_transcript(
video_id, languages=[language]
)
else:
transcripts = YouTubeTranscriptApi.get_transcript(video_id)
except (NoTranscriptFound, TranscriptsDisabled) as e:
raise Exception(
f"Failed to fetch transcript for video '{video_id}': {str(e)}"
)
transcript_text = " ".join([transcript["text"] for transcript in transcripts])
total_duration = sum([transcript["duration"] for transcript in transcripts])
return YouTubeTranscriptToolOutputSchema(
transcript=transcript_text,
duration=total_duration,
)
@staticmethod
def extract_video_id(url: str) -> str:
"""
Extracts the video ID from a YouTube URL.
Args:
url (str): The YouTube video URL.
Returns:
str: The extracted video ID.
"""
return url.split("v=")[-1].split("&")[0]
With agents, tasks, and tools defined, we can now build our Crew and set their dependencies.
As shown below, we declare the agents by using the @agent decorator, together with the respective tools and their components (role, goal and backstory). For tasks, we use the @task decorator and define their components (description, output and agent). Finally, we define how they should collaborate, i.e., they work in a sequential manner Process.sequential.
import os
from crewai import Agent, Crew, Process, Task
from crewai.project import CrewBase, agent, crew, task
from crew_zaai.src.crew_zaai.tools.searx import SearxSearchTool
from crew_zaai.src.crew_zaai.tools.youtube import YouTubeTranscriptTool
@CrewBase
class CrewZaai:
"""CrewZaai crew"""
agents_config = "config/agents.yaml"
tasks_config = "config/tasks.yaml"
@agent
def researcher(self) -> Agent:
search_tool = SearxSearchTool(
searx_host=os.getenv("SEARXNG_BASE_URL"), unsecure=False
)
return Agent(
config=self.agents_config["researcher"], tools=[search_tool], verbose=True
)
@agent
def summarizer(self) -> Agent:
youtube_tool = YouTubeTranscriptTool()
return Agent(
config=self.agents_config["summarizer"], tools=[youtube_tool], verbose=True
)
@agent
def blog_writer(self) -> Agent:
return Agent(config=self.agents_config["blog_writer"], verbose=True)
@task
def research_task(self) -> Task:
return Task(
config=self.tasks_config["research_task"],
)
@task
def summarizer_task(self) -> Task:
return Task(
config=self.tasks_config["summarize_task"],
)
@task
def write_task(self) -> Task:
return Task(
config=self.tasks_config["write_task"], output_file="assets/report.html"
)
@crew
def crew(self) -> Crew:
"""Creates the CrewZaai crew"""
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential,
verbose=True,
)@CrewBase
class CrewZaai:
"""CrewZaai crew"""
The last step is to make our agents work together to write the blog post by kicking off our Crew.
import sys
import warnings
from crew_zaai.src.crew_zaai.crew import CrewZaai
from dotenv import load_dotenv
warnings.filterwarnings("ignore", category=SyntaxWarning, module="pysbd")
load_dotenv()
inputs = {"topic": "AI Agents"}
CrewZaai().crew().kickoff(inputs=inputs)
By default, the LLM used is GPT-4o-mini from OpenAI; therefore, the OpenAI API key must be set as an environment variable. We also need to set the API key for YouTube (check this link to create your key) and the URL for the search engine. Our .env file must contain the following variables:
YOUTUBE_API_KEY=OPENAI_API_KEY= SEARXNG_BASE_URL=https://search.zaai.ai
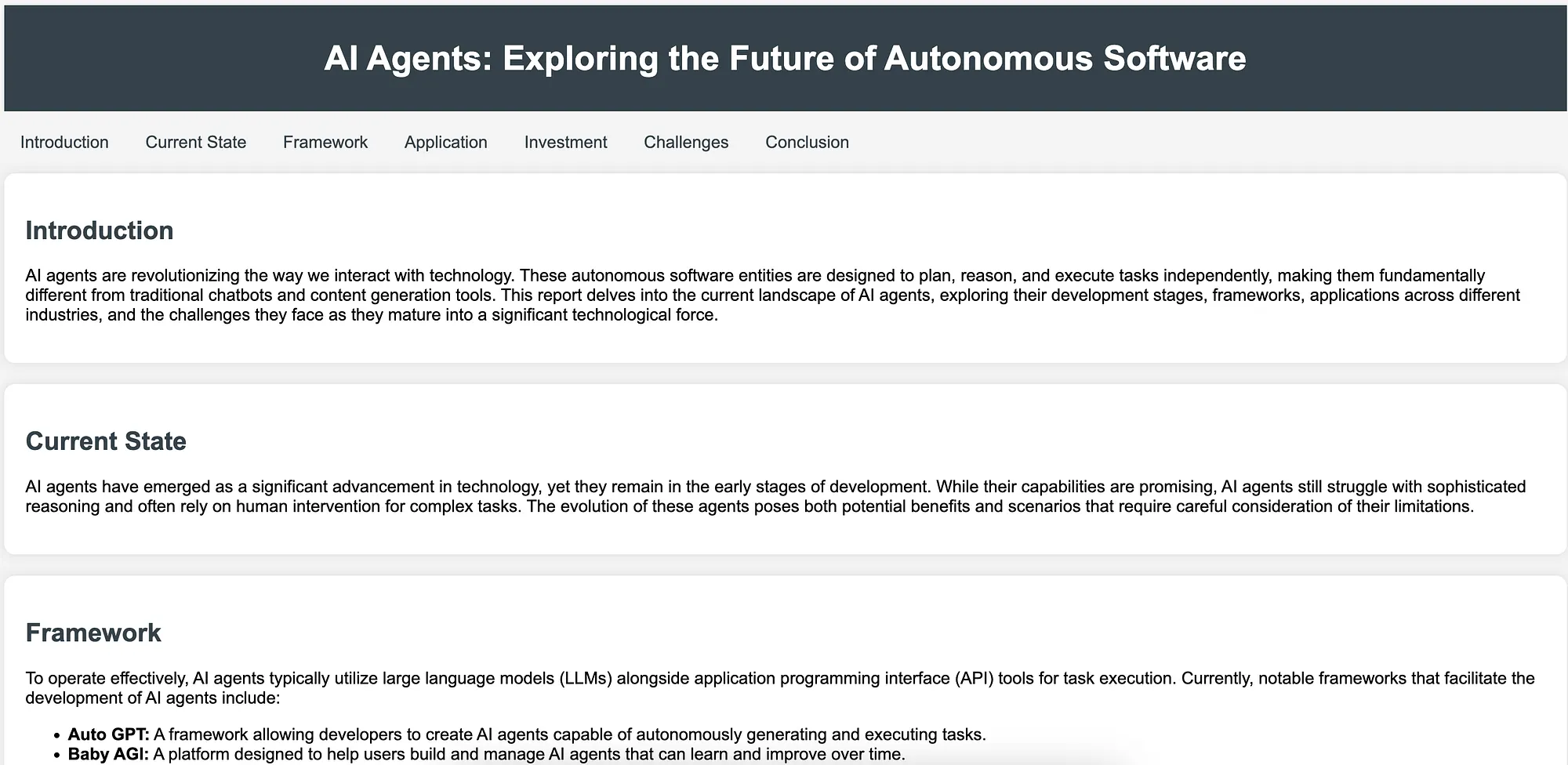
After running the script, the output of our crew is stored in a folder called assets/ and a screenshot of it can be seen below:
Conclusion
In this article, we explored the topic of the moment: Agentic AI.
Agentic AI is a shift in the industry towards a more autonomous and collaborative workflow without human intervention. It promises to free humans from boring and simple tasks and allow them to focus on more value-added ones.
We presented a simple use case where a MAS produced a blog post without human intervention. The agents searched the web for content, got transcriptions from recent YouTube videos, structured ideas, and produced an HTML page with the output. We can now use these agents for new and more complex use cases. For example, we could help customers search for products on a website using text and images, leveraging multimodal capabilities. We could also create personalized curriculums for a course (education) or review documents and assess their compliance (legal).
With the right investments and strategies, AI will continue to set new standards for productivity and creativity. The possibilities are endless, and the time to explore them is now.
About me
Serial entrepreneur and leader in the AI space. I develop AI products for businesses and invest in AI-focused startups. Founder @ ZAAI | LinkedIn | X/Twitter
References
[1] Menlo Ventures. (2024). The State of Generative AI in the Enterprise. Retrieved from https://menlovc.com/2024-the-state-of-generative-ai-in-the-enterprise/
[2] Talebirad, Y., & Nadiri, A. (2023). Multi-Agent Collaboration: Harnessing the Power of Intelligent LLM Agents. arXiv:2306.03314.
[3] Han, S., Zhang, Q., Yao, Y., Jin, W., Xu, Z., & He, C. (2024). LLM Multi-Agent Systems: Challenges and Open Problems. arXiv:2402.03578.
All images are by the authors unless noted otherwise.